Google Apps Scriptで書籍検索を実装してみる【GAS】
自社や学校等で様々な専門書を持っている所では、貸出管理や蔵書の購入、廃棄など様々な本に関する仕事があります。その中で「この本あったかな?」「現在何名借りてるのか?」などの情報が管理上必要になることはままあります。
今回は自前で持っている蔵書と、オンライン(今回は国会図書館および楽天ブックスのAPIを使ってみます)を検索し、蔵書であるものは●で表示し、ないものでも、ISBNコードをクリックすればそのまま、Amazonで検索し買えるまでをアプリケーションにしてみました。会社ではここに、蔵書の追加登録や、廃棄登録、貸出登録や貸出状況の確認などができるように改造を追加する予定です。
目次
今回使用するスプレッドシートやメソッド
事前準備
国会図書館API
国会図書館APIは検索結果を最大で500件までしか返せないので、いろいろと仕組みを考えなければなりませんが、今回は特に絞り込みを設けずに、名前検索で引っ張ります。試しに使用したクエリはこちら。
国会図書館APIの場合、事前申請やAPIキーなどはないので、自由に使えますが、相手サーバのレスポンスが遅いです。場合によってはタイムアウトしたりします。ただ、返り値の中には、対象の本や資料がどこの図書館にあるのかがわかったりするので、非常に便利な面と、本だけじゃなく論文的な資料もヒットするので、専門分野での蔵書検索では一役買うと思います。
楽天ブックスAPI側の準備
楽天ブックス書籍検索APIは、事前にアプリケーションIDの取得が必要です。国会図書館同様絞り込みをせず、名前検索で引っ張るようにしました。試しに使用したクエリはこちら。
APIの取得手順は以下の通り。楽天IDが必要です。今回はいつものようなOAuth2認証を使わないので、APIキーのみでオッケーです。
- 新規アプリ登録画面へ行く
- アプリ名、アプリのURL(設置場所等)を入力して、規約に同意して新規アプリを作成をクリック
- アプリIDが表示されますので、この値を控えておきます。プログラムの中で使用します。

図:アプリIDがそれになります。ほかの項目は不要です。
ソースコード
GAS側コード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 |
//楽天Books API用の設定 var appid = "ここにアプリIDを入力する" //検索用URL var jpnbookurl = "http://iss.ndl.go.jp/api/opensearch?title="; var rakutenurl = "https://app.rakuten.co.jp/services/api/BooksBook/Search/20170404?applicationId=" //ブック検索メインルーチン function booksearch(title){ //まずは国会図書館APIの検索URIを組み立てる(キーワードはURLエンコードする) var sURL = jpnbookurl + encodeURIComponent(title); var array = []; //myBooksデータを取得する var Properties = PropertiesService.getScriptProperties(); var sheetid = Properties.getProperty("mysheetid"); var books = SpreadsheetApp.openById(sheetid).getSheetByName("MyBooks").getRange("A2:G").getValues(); var blength = books.length; //スクリプトロックを使用する var lock = LockService.getScriptLock(); try{ //30秒間のロックを実施する lock.waitLock(30000); //検索結果を取得する var response = UrlFetchApp.fetch(sURL); //XMLを取得する var xmldocs = XmlService.parse(response.getContentText()); //itemノードを取得する var items = xmldocs.getRootElement().getChildren('channel')[0].getChildren('item'); var length = items.length; //namespaceを取得する var namespaceDc = XmlService.getNamespace("dc", "http://purl.org/dc/elements/1.1/"); var namespaceDcndl = XmlService.getNamespace("dcndl", "http://ndl.go.jp/dcndl/terms/"); var namespacexsi = XmlService.getNamespace("xsi", "http://www.w3.org/2001/XMLSchema-instance"); //ループでタイトルを取得 for(var i = 0;i<length;i++){ //変数を初期化 var isbn = ""; var tempArray = []; //dc:identifierを取得 var prop = items[i].getChildren('identifier', namespaceDc); //dc:identifier内をループでトレース for(var j = 0; j < prop.length; j++){ //1つ目のidentifierの属性値を取得 var property = prop[j]; //xsi:typeの値を取得 var name = property.getAttribute("type",namespacexsi).getValue(); //xsi:typeの値がISBNならば配列にISBN値としてpush if(name == "dcndl:ISBN"){ var isbn = items[i].getChildText("identifier", namespaceDc); tempArray.push(isbn); break; } } //isbn値が空の場合には、空値をpush if(isbn == ""){ tempArray.push(""); } //書籍のタイトル var bookTitle = items[i].getChildText("title", namespaceDc); tempArray.push(bookTitle) //著者名 var author = items[i].getChildText("author"); tempArray.push(author); //出版社名 var pubname = items[i].getChildText("publisher", namespaceDc); if(pubname == null){ tempArray.push(""); }else{ tempArray.push(pubname); } //画像はないので、値を空のままpush tempArray.push(""); //発売日 var pubday = items[i].getChildText("pubDate"); tempArray.push(getDate(pubday)); //値段 var price = items[i].getChildText("price", namespaceDcndl); if(price == null){ tempArray.push(""); }else{ tempArray.push(price); } //書庫にあるかどうかチェック var syoko = ""; if(isbn == ""){ //何もしない }else{ for(var b = 0;b<blength;b++){ if(String(books[b][0]) == String(isbn)){ syoko = "1" break; } } } tempArray.push(syoko); //書き込み用配列にpushする array.push(tempArray); } //arrayの個数を取得 var alength = array.length //生成した配列を返す return JSON.stringify(["OK",array,alength]); }catch(e){ //ロック取得できなかった時の処理等を記述する var msg; var checkword = "ロックのタイムアウト: 別のプロセスがロックを保持している時間が長すぎました。"; //通常のエラーとロックエラーを区別する if(e.message == checkword){ //ロックエラーの場合 msg = "誰かまだ使ってるみたい"; }else{ //ソレ以外のエラーの場合 msg = e.message; } //配列を返す return JSON.stringify(["NG",msg]); }finally{ //ロックを開放する lock.releaseLock(); } } //楽天ブックス書籍検索APIでサーチ function rakubook(title){ //URLを組み立てる var sURL = rakutenurl + appid + "&title=" + encodeURIComponent(title); var array = []; //myBooksデータを取得する var Properties = PropertiesService.getScriptProperties(); var sheetid = Properties.getProperty("mysheetid"); var mybooks = SpreadsheetApp.openById(sheetid).getSheetByName("MyBooks").getRange("A2:G").getValues(); var blength = mybooks.length; //スクリプトロックを使用する //複数名同時にアクセスしてきたことに考慮して var lock = LockService.getScriptLock(); try{ //30秒間のロックを実施する lock.waitLock(30000); //検索結果を取得する var response = JSON.parse(UrlFetchApp.fetch(sURL)); var books = response.Items; //ページカウントとヒットした件数を取得 var pagecnt = response.pageCount + 1; var hitlength = response.hits; var alength = response.count; //1ページ目のデータを取得 for(var i = 0;i<hitlength;i++){ //変数を初期化 var isbn = ""; var tempArray = []; //ISBNコード var isbn = books[i].Item.isbn; tempArray.push(isbn); //書籍のタイトル var bookTitle = books[i].Item.title; tempArray.push(bookTitle) //著者名 var author = books[i].Item.author; tempArray.push(author); //出版社名 var pubname = books[i].Item.publisherName; tempArray.push(pubname); //画像URL tempArray.push(""); //発売日 var pubdate = books[i].Item.salesDate; if(pubdate != ""){ //オカシナ日付形式を修正 pubdate = pubdate.replace("頃", ""); if(pubdate.length == 8){ pubdate = pubdate + "01日"; } //正規表現でフォーマットを変更 pubdate = pubdate.replace(/(\d{4})年(\d{2})月(\d{2})日/,"$1/$2/$3"); tempArray.push(getDate(new Date(pubdate))); }else{ tempArray.push(""); } //値段 var price = books[i].Item.itemPrice; if(isbn == ""){ //何もしない }else{ //カンマ区切りセパレートする price = String(price).replace( /(\d)(?=(\d\d\d)+(?!\d))/g, '$1,' ) + "円"; } tempArray.push(price); //書庫にあるかどうかチェック var syoko = ""; if(isbn == ""){ //何もしない }else{ for(var b = 0;b<blength;b++){ if(String(mybooks[b][0]) == String(isbn)){ syoko = "1" break; } } } tempArray.push(syoko); //arrayに追加 array.push(tempArray); } //2ページ目以降をpageCountをもとに全データを取得する var page = 2; for(var p = 1;p<pagecnt;p++){ //UrlfetchApp連続アクセス規制に掛からないようにsleepを入れる Utilities.sleep(3000); //ページ指定のURLでAPIに再アクセス var pURL = sURL + "&page=" + page; //検索結果を取得する response = JSON.parse(UrlFetchApp.fetch(pURL)); books = response.Items; hitlength = response.hits; //ページデータを取得する for(var i = 0;i<hitlength;i++){ //変数を初期化 var isbn = ""; var tempArray = []; //ISBNコード var isbn = books[i].Item.isbn; tempArray.push(isbn); //書籍のタイトル var bookTitle = books[i].Item.title; tempArray.push(bookTitle) //著者名 var author = books[i].Item.author; tempArray.push(author); //出版社名 var pubname = books[i].Item.publisherName; tempArray.push(pubname); //画像はないので、値を空のままpush tempArray.push(""); //発売日 var pubdate = books[i].Item.salesDate; if(pubdate != ""){ //オカシナ日付形式を修正 pubdate = pubdate.replace("頃", ""); if(pubdate.length == 8){ pubdate = pubdate + "01日"; } //正規表現でフォーマットを変更 pubdate = pubdate.replace(/(\d{4})年(\d{2})月(\d{2})日/,"$1/$2/$3"); tempArray.push(getDate(new Date(pubdate))); }else{ tempArray.push(""); } //値段 var price = books[i].Item.itemPrice; if(isbn == ""){ //何もしない }else{ //カンマ区切りセパレートする price = String(price).replace( /(\d)(?=(\d\d\d)+(?!\d))/g, '$1,' ) + "円"; } tempArray.push(price); //書庫にあるかどうかチェック var syoko = ""; if(isbn == ""){ //何もしない }else{ for(var b = 0;b<blength;b++){ if(String(mybooks[b][0]) == String(isbn)){ syoko = "1" break; } } } tempArray.push(syoko); //arrayに追加 array.push(tempArray); } //ページカウンタを回す page = page + 1; } //生成した配列を返す return JSON.stringify(["OK",array,alength]); }catch(e){ //ロック取得できなかった時の処理等を記述する var msg; var checkword = "ロックのタイムアウト: 別のプロセスがロックを保持している時間が長すぎました。"; //通常のエラーとロックエラーを区別する if(e.message == checkword){ //ロックエラーの場合 msg = "誰かまだ使ってるみたい"; }else{ //ソレ以外のエラーの場合 msg = e.message; } //配列を返す return JSON.stringify(["NG",msg]); }finally{ //ロックを開放する lock.releaseLock(); } } |
- 国会図書館APIは返り値がXML形式であるため、パース作業が必要になります。ネームスペースの指定など結構面倒なコードになってます。
- 楽天ブックス書籍検索APIは返り値がJSON形式であるため、そのまま取得値を取り出すことが可能です。
- それぞれの取得し成型したデータの形式は同一にし、HTML側へ返しています。
- 排他制御を入れている理由は、複数名同時にアクセスしてきた場合に、自分の権限だけで動かしている場合、UrlfetchAppの連続リクエスト制限に掛かる為。ゆえにこのアプリは、アクセスしてきた人間の権限で動かすようにしたほうがベスト。
- 両者共に、自分のMyBooksシート記載の書籍にあるかどうかのチェックをしています。ある場合には●が返るようにしています。
- 楽天ブックス書籍検索APIは一気に検索データを取得できず、何ページにもわかれているため、ページ数を取得後にループで何度も残りのデータを取得するようになっています。
- また、1ページあたり最大30件にリターン値しかないので、短いワードだと何度もリクエストが発生する為、Sleepを入れてUrlfetchAppのリクエスト制限を回避しています。
- 楽天ブックス書籍検索APIの返り値のうち、日付に関して「日の無い、いい加減な出版日」であったり、余計な文字列、空欄になってるデータに対して対処するように、変換コードが入っています。
- 数値については、カンマ区切りに円をつけるように、正規表現にて返り値をリプレースしています。
HTML側コード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 |
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <title>書籍検索君</title> <!-- 外部ライブラリの呼び出し --> <script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.1.0/jquery.min.js"></script> <link href="//maxcdn.bootstrapcdn.com/bootstrap/3.1.0/css/bootstrap.min.css" rel="stylesheet" id="bootstrap-css"> <script src="https://cdnjs.cloudflare.com/ajax/libs/twitter-bootstrap/3.3.7/js/bootstrap.min.js"></script> <style> #imaginary_container{ margin-top:3%; width:700px; } .stylish-input-group .input-group-addon{ background: white !important; } .stylish-input-group .form-control{ border-right:0; box-shadow:0 0 0; border-color:#ccc; } .stylish-input-group button{ border:0; background:transparent; } </style> <script> //テキストボックスでEnterでも検索実行 document.addEventListener ('keydown',function(e){ var t = e.target; if(t.nodeName=="INPUT" && t.name=="kensaku" && e.keyCode==13){ searchman(); } }); //書籍検索APIにて書籍情報を検索する function searchman(){ //検索ワードをvalidate var validata = document.getElementById("wasabi").value; if(validata == "" || validata == null){ //ダイアログの内容を書き換える $('#modalman').find('.modal-body').text('検索ワードが空っぽですよ!!'); $('#modalman').find('.modal-title').text('☢あらーと'); //モーダルダイアログを表示する $('#modalman').modal('show'); return; } //検索先に応じて処理を分岐 var api = document.getElementById("apikick").value; if(api == "国会図書館"){ //GAS側へキーワードを送る google.script.run.withSuccessHandler(onSuccess).booksearch(validata); }else{ google.script.run.withSuccessHandler(onSuccess).rakubook(validata); } //プログレス表示 document.getElementById("result").style.display = "none"; document.getElementById("sendprogress").style.display = "block"; } //返り値の処理 function onSuccess(data){ //データを取得する var json = JSON.parse(data); var record = json[1]; //エラー処理 if(json[0] == "NG"){ //エラーメッセージを表示して処理を中断 //ダイアログの内容を書き換える $('#modalman').find('.modal-body').text(json[1]); $('#modalman').find('.modal-title').text('エラーが発生しました。'); //モーダルダイアログを表示する $('#modalman').modal('show'); //プログレス表示 document.getElementById("result").innerHTML = ""; document.getElementById("result").style.display = "block"; document.getElementById("sendprogress").style.display = "none"; return; } //検索結果が0件の場合 if(json[2] == 0){ //ダイアログの内容を書き換える $('#modalman').find('.modal-body').text('検索結果が0件です'); $('#modalman').find('.modal-title').text('☢あらーと'); //モーダルダイアログを表示する $('#modalman').modal('show'); return; } //検索結果からテーブルを作る var reclength = record[0].length; var amazon = "https://www.amazon.co.jp/s/ref=nb_sb_noss?__mk_ja_JP=カタカナ&url=search-alias%3Daps&field-keywords=" var html = "<table class='table'>"; html += "<thead><tr><th>ISBN</th><th>タイトル</th><th>著者名</th><th>出版社名</th><th>出版日</th><th>価格</th><th>書庫有無</th>"; html += "</tr></thead>"; html += " <tbody>"; for(var i = 0;i<json[2];i++){ //レコードを生成 html += "<tr>"; //レコードデータをHTMLに展開 for(var j = 0;j<reclength;j++){ //画像は飛ばす if(j == 4){ continue; } //項目毎に処理を分岐 switch(j){ case 0: html += "<td class='col-md-1'>"; html += "<a href='" + amazon + record[i][j] + "' target='_blank'>" + record[i][j] + "</a>"; html += "</td>"; break; case 1: case 2: html += "<td class='col-md-3'>"; html += record[i][j]; html += "</td>"; break; case 3: html += "<td class='col-md-2'>"; html += record[i][j]; html += "</td>"; break; case 6: html += "<td class='col-md-1' align='right'>"; html += record[i][j]; html += "</td>"; break; case 7: //所持してる本の場合 if(record[i][7] == 1){ html += "<td class='col-md-1'>"; html += "<font color='#1df958' size='5'>●</font>" html += "</td>"; }else{ html += "<td class='col-md-1'>"; html += "" html += "</td>"; } break; default: html += "<td>"; html += record[i][j]; html += "</td>"; break; } } //レコードを閉じる html += "</tr>"; } //htmlを閉じる html += "</tbody></table>" //テーブルデータをdivに展開 document.getElementById("result").innerHTML = html; //プログレス表示 document.getElementById("result").style.display = "block"; document.getElementById("sendprogress").style.display = "none"; } </script> </head> <body> <!-- 検索ページロゴ --> <center> <img src="ここに好きなロゴ画像のURLを入れる" width="30%" height="10%"> </center> <!-- 検索ワード入力フォーム --> <div class="container"> <div class="row"> <div class="col-sm-6 col-sm-offset-3"> <div id="imaginary_container"> <table class="tg" width="650px"> <tr> <th class="tg-0lax" width="400px"> <div class="input-group stylish-input-group"> <input type="text" class="form-control" placeholder="検索ワードを入力してください" id="wasabi" name="kensaku"> <span class="input-group-addon"> <button type="submit" onClick="searchman()"> <span class="glyphicon glyphicon-search"></span> </button> </span> </div> </th> <th class="tg-0lax" width="150px"> <select class="form-control" id="apikick"> <option>楽天ブックス</option> <option>国会図書館</option> </select> </th> </tr> </table> </div> </div> </div> </div> <!-- 検索結果の表示場所 --> <div id="result"> <center> <br> <p>国会図書館検索は最大200件まで表示です。楽天書籍検索は最大300件まで表示可能。</p> <br> <p>あまり短いワードだと検索結果を集めるのに時間が掛かります。</p> </center> </div> <!-- モーダルダイアログ --> <div class="modal fade" id="modalman" tabindex="-1" role="dialog" aria-labelledby="modal" aria-hidden="true"> <div class="modal-dialog" role="document"> <div class="modal-content"> <div class="modal-header"> <h5 class="modal-title" id="dialogtitle">タイトル</h5> <button type="button" class="close" data-dismiss="modal" aria-label="Close"> <span aria-hidden="true">×</span> </button> </div> <div class="modal-body" id="modaldescript"> 内容・・・ </div> <div class="modal-footer"> <button type="button" class="btn btn-secondary" data-dismiss="modal">閉じる</button> </div> </div> </div> </div> <p> <!-- プログレスインジケータ --> <div id="sendprogress" style="display:none;" align='center'> <center><span id="progress">検索中・・・<img border='0' src='https://officeforest.org/wp/library/icons/spinner.gif' width='32' height='32'></span></center> </div> </body> </html> |
- 今回はいつもと違い、Bootstrap3ライブラリでUIを構築しています。よって、アラートメッセージなどがちょっと呼び出し方が変わったやり方になっています。
- テキストボックス内でEnterにて、検索ができるようにコードを追加しています。
- 返り値はTable方式で生成し、innerHTMLで挿入しています。Class指定はBootstrap3のライブラリを利用するために付与しています。
- セレクトメニューの内容に応じて、国会図書館APIおよび楽天ブックス書籍検索APIの2つを切り替えています。
実行と結果
利用方法は簡単。ウェブアプリケーションとしてデプロイしたのちにアクセスし、セットアップを実行後検索するだけ。セットアップはそのシートのIDをスクリプトプロパティに格納しており、所有書籍と検索書籍の結果と突合させる為に利用しています。
ただし、両者のAPIともに、速度面で遅かったり、ページが分けられていてトータル取得が遅いなど、ちょっと面倒が面があります。もっと良い書籍検索APIがあったら良いのですが。GAS側も連続アクセスでUrlfetchAppのリミットに掛からないように、Sleepを入れている為、遅い原因になっています。
ですので、実際には標準で色々絞り込みやトップ100だけ出すなどの対策が必要です。日本のAPIサービスはこういったケースが多いのでなかなか不便ですね。
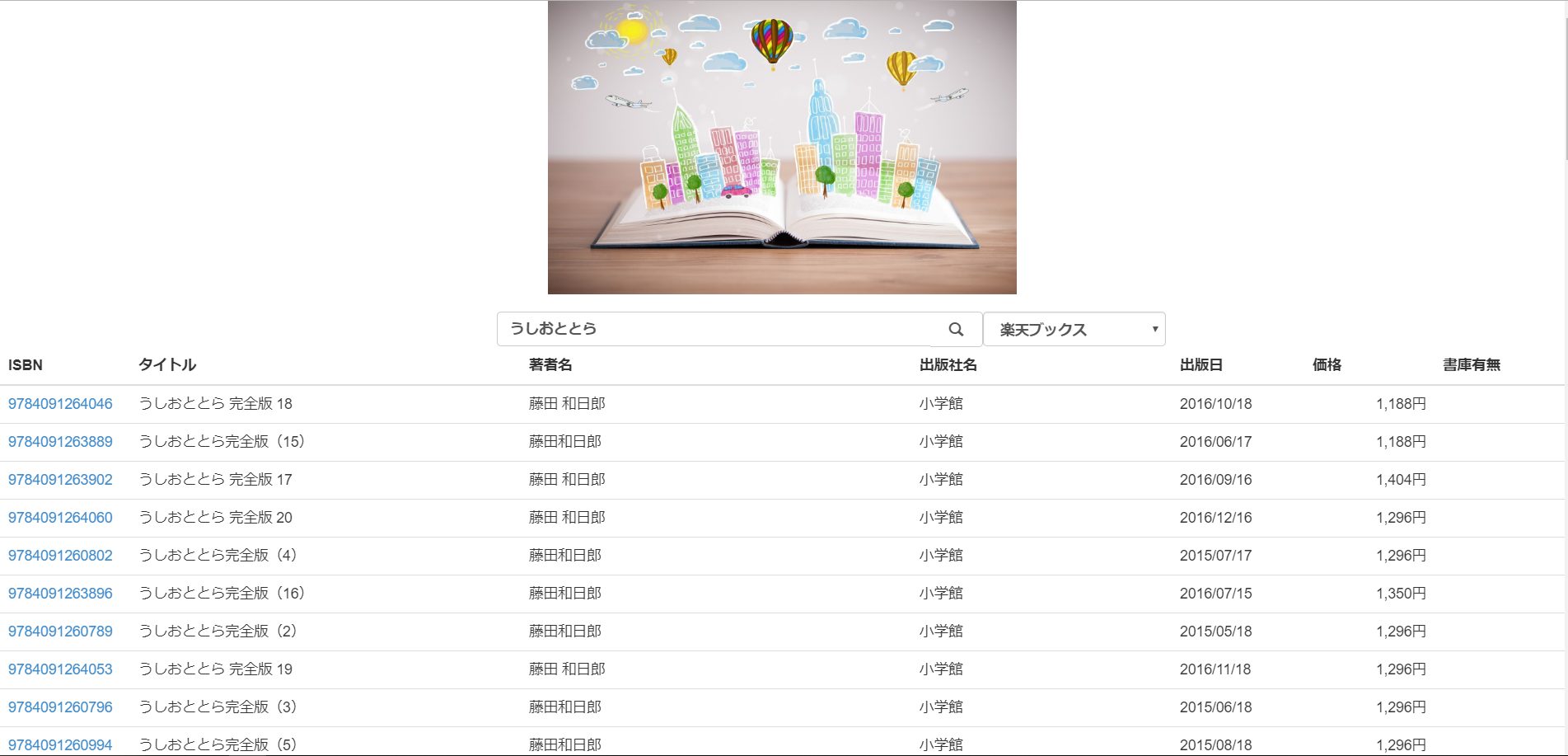
図:うしおととらを検索してみた
関連リンク
- Google Books API
- GASからCalendarResourceAPIを叩いてみた(+XmlServiceの説明)
- 国会図書館の書誌データをxmlで取得しphpで
- phpを使って国立図書館APIとAmazonの画像URLを利用した書籍検索
- jQueryでXML要素を属性指定で値を一発取得できた!(if文を使わずにですよ?)
- Excel VBAでWebサービス - Excelで書籍情報を検索・取得してみよう
- Amazon MWS商品APIセクションについて知っておくべきこと
- AmazonAPIとは? PA-APIとMWS-APIの違い
- Bootstrapでテーブルを利用する方法

