PuppeteerでBasic認証を通過しページ数を取得する
最近久しぶりに、ちょっとした仕事で「Basic認証の掛かってるページ」にログインして、検索をし、出てきたページからファイルをダウンロードしてほしいという依頼があり、実装をしてみました。
ページ数は検索結果により変動し、ページネーションの数が異なるので、最大ページ数を取得して後は連続でファイルを順次ダウンロードを実行させるのですが、記録の為に残しておこうと思います。
目次
今回使用するライブラリ
今回のダウンロード上の問題点
今回対象にしているサイトは以下のような問題点を抱えています。検索ページで検索を行った結果表示されるページは全データが掲載されてるわけではなく、最大200件ずつのページネーションがされており、総件数を200で割った分だけページが存在していて、全部のデータを必要とする場合には、工夫が必要です。
- 通常のログインページではなく、Basic認証でログインが必要
- 検索ページでは様々な検索オプションが用意されている(今回はオプション指定しない)
- 検索後のページでは、デフォルト50件ずつのレコードが表示されている(最大200件)
- 件数に応じてページネーションの最大数が変わる為、全件取得したい場合は、ページネーションの最大数を取得する必要がある
- ページネーション数は最期のページへのリンクにjavascriptで移動する関数内に指定がある(例:paging(900);といった感じ。900ページある事がここからわかる)
- 全件チェックを入れて、ダウンロードをクリックする必要がある
今回は全件ダウンロードの一歩手前の最初のページだけダウンロードを実行させてみます。全件必要な場合は、さらに次のページへの移動とループでページネーションの最大数分だけ、ダウンロード処理が必要です。
コードと解説
今回のコードは冒頭部分とプロンプト受付部分については、これまでのエントリーとほぼ同じなので省略しています。必要な方はそちらを参照してください。
ソースコード
//Puppeteerメイン処理
async function main(userid,pw) {
const browser = await puppeteer.launch({
headless: false,
executablePath: chromepath,
ignoreDefaultArgs: ["--guest",'--disable-extensions','--start-fullscreen','--incognito',],
slowMo:100,
});
//ブラウザのダウンロード先をすべて統一する
await browser.on('targetcreated', async () =>{
const pageList = await browser.pages();
pageList.forEach((page) => {
page._client.send('Page.setDownloadBehavior', {
behavior: 'allow',
downloadPath: deskpath,
});
});
});
//pageを定義
const page = await browser.newPage()
const navigationPromise = page.waitForNavigation()
//Basic認証を突破してログイン
await page.authenticate({username: userid, password: pw});
await page.goto(url, {waitUntil: "domcontentloaded"});
await page.setViewport({ width: 1300, height: 900 })
await navigationPromise
//検索ボタンをクリック
await page.waitForSelector('.search #search_button')
await page.click('.search #search_button')
await navigationPromise
//200件表示に変更
await page.waitForSelector('#contents > #new_service_medicine_code_search_form > #search_result #limit')
await page.click('#contents > #new_service_medicine_code_search_form > #search_result #limit')
await page.select('#contents > #new_service_medicine_code_search_form > #search_result #limit', '200')
await navigationPromise
await sleep(5000);
//最後のページの数値を取得
var cnt = 1;
await page.waitForSelector('.clear-fix:nth-child(6) > .float-left > .pagination > li:nth-child(10) > a')
const lastnum = await page.evaluate(() => {
var node = document.querySelector('.clear-fix:nth-child(6) > .float-left > .pagination > li:nth-child(10) > a').getAttribute('href');
//数値だけ取り出す
return node.replace(/[^0-9]/g, '');
});
//ダウンロード実行
await page.waitForSelector('#new_service_medicine_code_search_form > #search_result #all_check')
await page.click('#new_service_medicine_code_search_form > #search_result #all_check')
await page.waitForSelector('#new_service_medicine_code_search_form > #search_result > .clearfix > .float-left > .download_excel')
await page.click('#new_service_medicine_code_search_form > #search_result > .clearfix > .float-left > .download_excel')
//終了メッセージを表示
const script = `window.alert('処理が完了しました')`;
await page.addScriptTag({ content: script });
//ブラウザを閉じる
//await browser.close()
}
//スリープ用関数
function sleep(milliSeconds) {
return new Promise((resolve, reject) => {
setTimeout(resolve, milliSeconds);
});
}
解説
今回のコードの最初の壁はBasic認証。しかしこれは簡単で、await page.authenticate({username: userid, password: pw}); これだけです。useridがユーザID、pwがパスワードで今回のアプリはpromptsにてユーザから入力してもらっています。簡単にログインが可能です。
次の壁が検索結果は200件表示にし、ページネーションの数を取得する事。200件表示に変更後にsleepを5秒間入れてるのは、変更後にページネーションの関数の数値が入れ替わるのですが、変わる前に次に進んでしまうため。これを待つ為にsleepさせています。
これは、page.evaluateを利用し、document.querySelectorにて、最後のページに飛ぶリンク要素内にあるhrefの値を取り出し、またそこから正規表現で数値だけを抜き出してページネーション数としています。正規表現はnode.replace(/[^0-9]/g, '');で指定して取り出しています。
あとは全件チェックを入れてダウンロードボタンをクリックするだけ。実際にあと全件取得をするには
- 次のページのリンクをクリックする(このページにある、pagingという関数に数値を入れればそのページに移動できるので、これを移動するのも良いかも)
- 全件チェックを入れる
- ダウンロードを実行
- ダウロードが完了するまで処理を待機
- これをページネーションの最大値分だけ、ループで処理を行う
この処理が必要になります。また、このページの検索はPOSTで送信されている為、URLに検索オプションは無いので、送信処理はクリックなどで自前で実装が必要です。
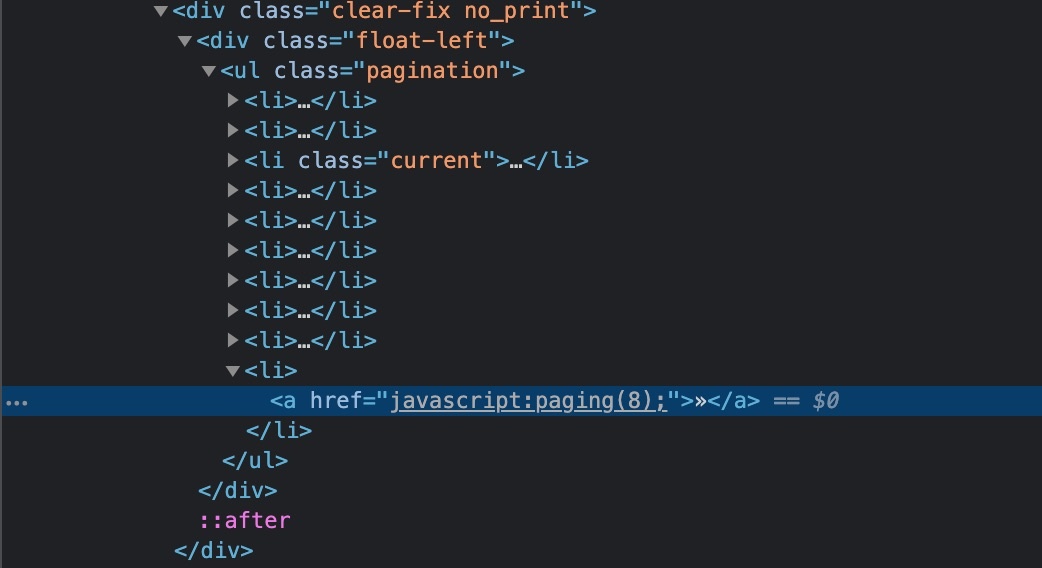
図:ここのhrefの中身を取得し、正規表現で数値のみ取り出す
Page.setDownloadBehaviorがDeprecatedな件
コードの中の「ブラウザのダウンロード先をすべて統一する」の部分、ここでは、これまでpage._client.sendを利用してPage.setDownloadBehaviorを送り込む事で、ダウンロード先を指定の場所に変更していました。
しかしこの機能が2020年7月頃、Deprecatedになり、代わりに以下のコードでダウンロード先を変更する必要有りとGithubのIssueに掲載されていました。今回のコードで言えばPageを定義後に
//pageを定義
const page = await browser.newPage()
const navigationPromise = page.waitForNavigation()
//ブラウザのダウンロード先をすべて統一する
const cdpsession = await page.target().createCDPSession();
cdpsession.send ("Browser.setDownloadBehavior", {behavior:"allow", downloadPath: dir_desktop });
といったように、createCDPSessionを定義して、Browser.setDownloadBehaviorとして送り込むように変更すべしとのこと。実際にコードを置き換えて実行してみたら問題なくダウンロード出来ました。これまではPage単位だったものをBrowser単位になっている為、Pageのリストを回してセットする必要がなくなっています。
関連リンク
- JavaScriptでアンカータグのhrefを取得する方法を現役エンジニアが解説【初心者向け】
- cheerio - cheerio / jqueryセレクター:タグaのテキストを取得する方法?
- Puppeteer: add basic auth header for main page domain only, not for 3rd party requests
- Page.setDownloadBehaviour deprecated
- page._client.send('Page.setDownloadBehavior', {behavior: 'allow', downloadPath: './tmp/order'}) causing error
- TypeScript + Seleniumのヘッドレスモードで実行したら指定したディレクトリにファイルがダウンロードされない場合の対処法
