Vertex AI のDocument AIで請求書読取り専用AIを作る
仕事の関係で、改めてVertex AI Studioを学ぶ必要が出てきた為、自分の為のまとめとして作成しています。APIとしては普段からGemini APIやClaudeを利用しているのですが、これもVertex AIのAPIであり、範疇なのですがVertex AI Studioとなるとまた少し話が異なるので、しっかり学ぶ必要があります。
今回は使い慣れているGeminiについて取り上げていますが、Vertex AI Studioは様々なモデルが用意されているので、Geminiに限らず使うことが可能です。今回はその1つであるDocument AIにフォーカスしてまとめてみました。
今回利用する素材
Vertex AI StudioはGoogle Cloud側のサービスであり、いつも利用してるGeminiアプリであったり、Google AI Studioとも異なります。学習するための素材はSkill Boostにも用意されているので、まずはそちらから入門するほうがスムーズでしょう。
GeminiアプリやAI Studioとは何が異なるのか?を見極めることが大きなポイントになります。
今回はその中でも事務の現場で使う機会が多いのではないかと思われるDocument AIと呼ばれる請求書や発注書データを読み取り、答えを返すものにチャレンジしてみたいと思います。
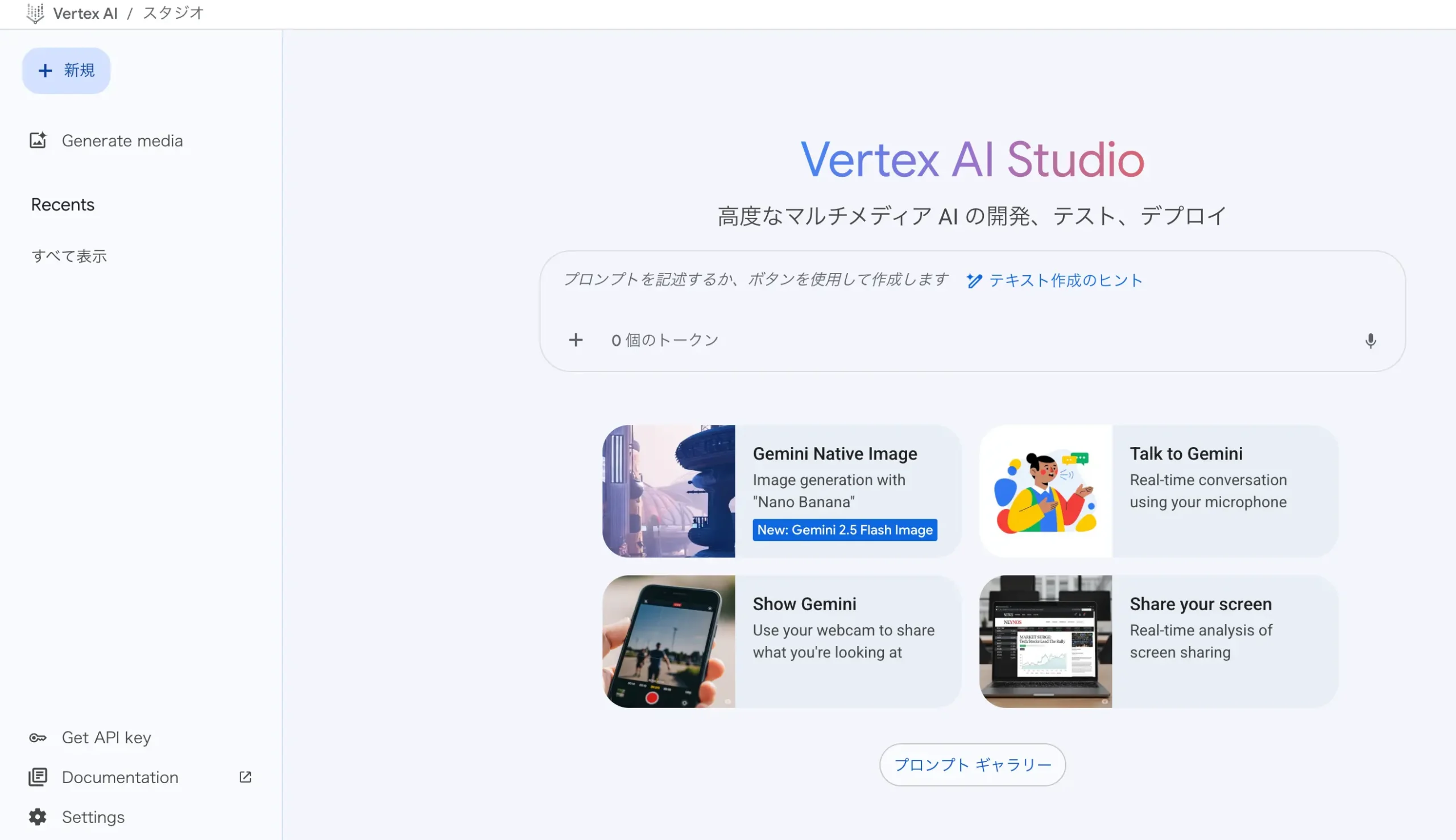
図:見た目はAI Studioと似ている
Vertex AI Studioとは?
概要
GeminiアプリやNotebookLMといったアプリは、生成AIを用いたアプリですが、これらはアプリとして構築しあげているものであり、自分自身でこれらのアプリに対して独自性やカスタマイズをすることは出来ません。APIを利用して呼び出しは出来ても中に手を入れることは出来ないということです。
一方でVertex AI Studioは、自組織独自のモデルを構築し、自組織独自のAIを開発することの出来る仕組みであり、自身でモデルのトレーニングを行い、独自のソースや社内の仕組みに特化したモデルそのものを構築することの出来る「開発環境」です。
開発者のやりたい方向性に応じて様々なサービスが用意されており、Google Cloudの別のサービスと連携しながらゼロから構築が可能であり、ハルシネーションの抑制や自社内完結の専用AIを用意出来ることが大きなポイントになります。主な方向性に応じて以下のように分類出来ます。
Document AIはこのうちの1つに属し、企業などの組織向けの大規模な生成AIによるOCRのソリューションという位置づけになります。大規模といっても個人レベルでも構築できる簡便さ大きな特徴です(今回のサンプルは、無学習の自分でもだいたい2日くらいで自分は構築しました)。その読取り精度や推測精度は非常に高く、OCRもここまで来たかと感じるレベルです。
| 目的 | サービス | 具体的用途 |
| 定型書類のデータ読み込み | Document AI | 請求・発注処理の自動化や契約管理 |
| 社内情報に基づく検索エンジン | Vertex AI Search | ナレッジ検索やFAQ自動応答 |
| 社内情報に基づくチャットボット | Vertex AI Conversation Agents | いわゆるチャットボット。 |
| 要約や汎用的なテキスト処理 | Vertex AI Studio | 議事録要約やコードアシスト |
| 画像生成や編集 | Imagen on Vertex AI | 広告の作成やデザイン、サムネ画像作成等 |
| 文字起こしや読み上げ | Speech-to-Text / Text-to-Speech | 議事録自動生成や音声ガイダンス |
作成をした独自の生成AI・モデルは、APIを利用して例えばGoogle Apps Scriptから呼び出して利用する、他のシステムと連携して利用するといった事が可能となります。チャットボットについては以下のエントリーを参考にしてみてください。
Document AIの利用料金
こちらに料金表があります。ちょっとわかりにくいですが大まかには以下のような構成になります。今回のケースだとカスタムプロセッサでCustom Extractorを使う構成なので
- 1,000ページあたり30ドル(1~1,000,000ページまで)
- カスタムプロセッサなのでホスティング料金が1 時間あたり 0.05 ドル
故にカスタムプロセッサをデプロイ状態で使って1日回した際の1枚あたりの単価は$1 = 155円で換算した際には以下のようになります。
- $0.03 * 155円 = 4.65円/1枚(1枚あたりの読み取りコスト)
- 0.05 * 24時間 * 155円 = 186円/1日(ホスティングの固定費)
故に少数だけだとホスティング料金を考えてしまうと190円も掛かる計算になるので、小規模ならばGeminiのGemsで動かしたほうがお得ということになります。
カスタムプロセッサとして構築している為、Googleが事前に用意した事前構築済みプロセッサではありません。よって、デプロイした状態ですと料金が掛かり続けます。テストならばデプロイ解除をしておくと良いでしょう。しかし、カスタムプロセッサの場合デプロイ解除してしまうとAPIリクエストが出来なくなるので、その点が大きな注意ポイントです。
事前学習済みプロセッサの料金にあるように、請求書パーサーという構築済みモデルもあるので、こちらを試してみるのも良いでしょう。こちらはホスティング料金かからずAPIからのリクエストも常時可能で、 文書10ページごとに0.10ドルの料金となります。
この仕組みの使い所
GeminiアプリのGemsなどでプロンプトをしっかり組み上げて仕込んでおけば、このような仕組み不要なのでは?という疑問は湧くと思います。しかしあくまでもGeminiアプリは個人利用の範疇であり、プロンプトでしか制御が出来ません。よって揺らぎが出やすく、また後処理につなげるのも人間が行う必要があります。
一方、Gemini APIであれば後処理も出来るのですが、同じくプロンプトでしか制御が出来ないのでどうしてこの部分で不安定さが出てしまいます。
また、Geminiアプリを使う為には個々人に月額のライセンス割当が必要であり、利用上限もあります。社内の基幹システムとして用意しておく事でライセンス無しの人でもチャット画面等使わずにシームレスなシステムの一部として組み込めるのがDocument AIの良きポイントになるかと思います。
※また、Cloud Run Functions連携でGCSにファイルが追加されたら自動的にGCFをトリガーし、してDocument AIで処理をやらせて値を取得し、特定のGoogleスプレッドシートに書き出すなんて仕組みも作れるかもしれません。ユーザはバケットにファイルを入れるだけで済みます(Sheets APIを利用します)
事前準備
あらかじめGoogle Cloudに対してプロジェクトを用意しておき、今回のケースで言えば以下のAPIを有効化しておく必要があります。もちろん課金アカウントとの紐付けについても完了済みであることが必要です。
APIの有効化
他から使うことが前提であるため、Google Cloud上で該当プロジェクトにてAPIを有効化しておきます。
似たような名前のDocument AI WarehouseというAPIもありますが、こちらはファイリングのための仕組みであり、ドキュメントの保管や検索が目的のものになるので今回の目的とはズレていますので注意。
またファイルの置き場としてGoogle Cloud Storageを利用するので、その為のAPIも有効化が必要です。
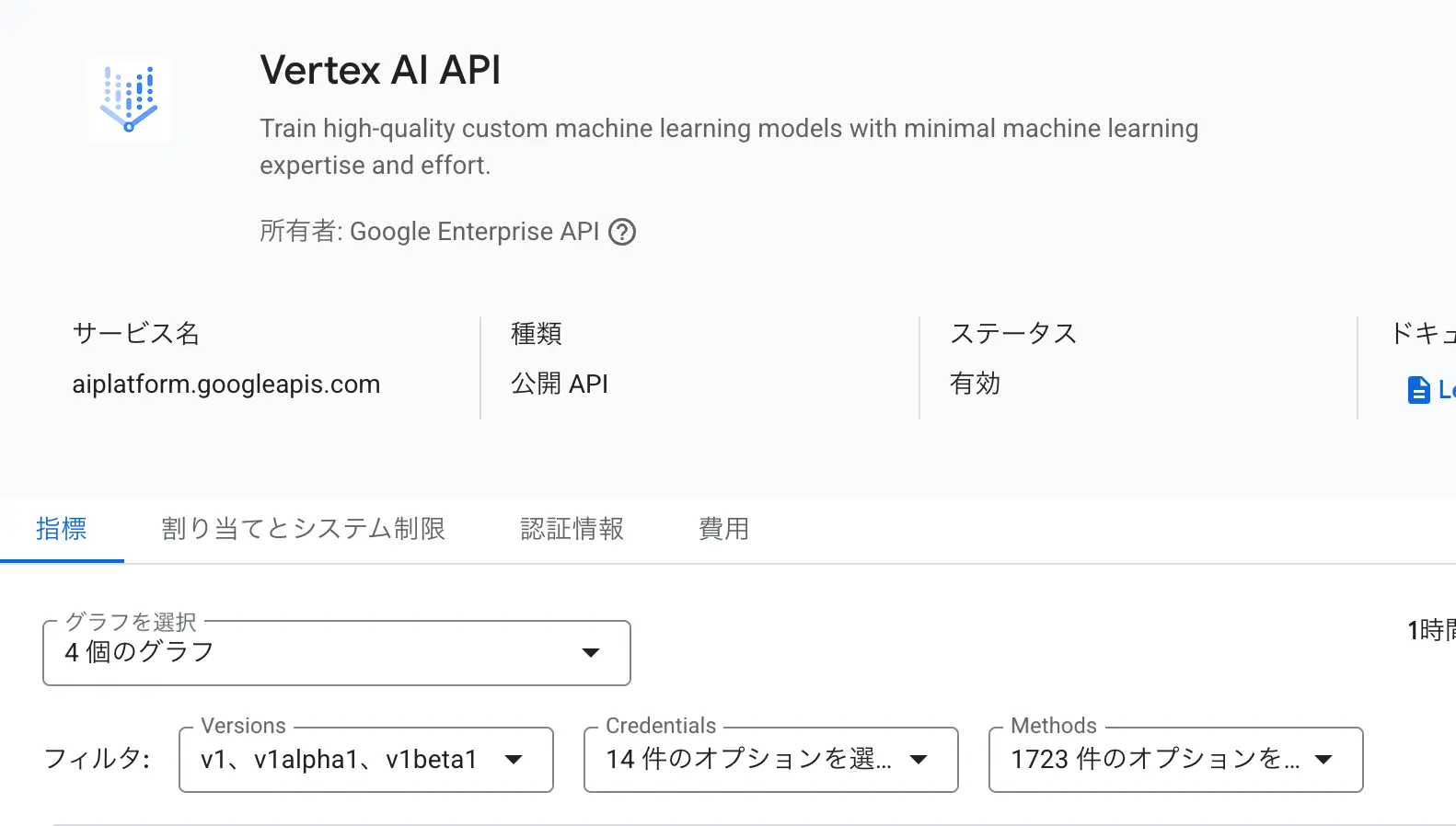
図:Vertex AI APIを有効化
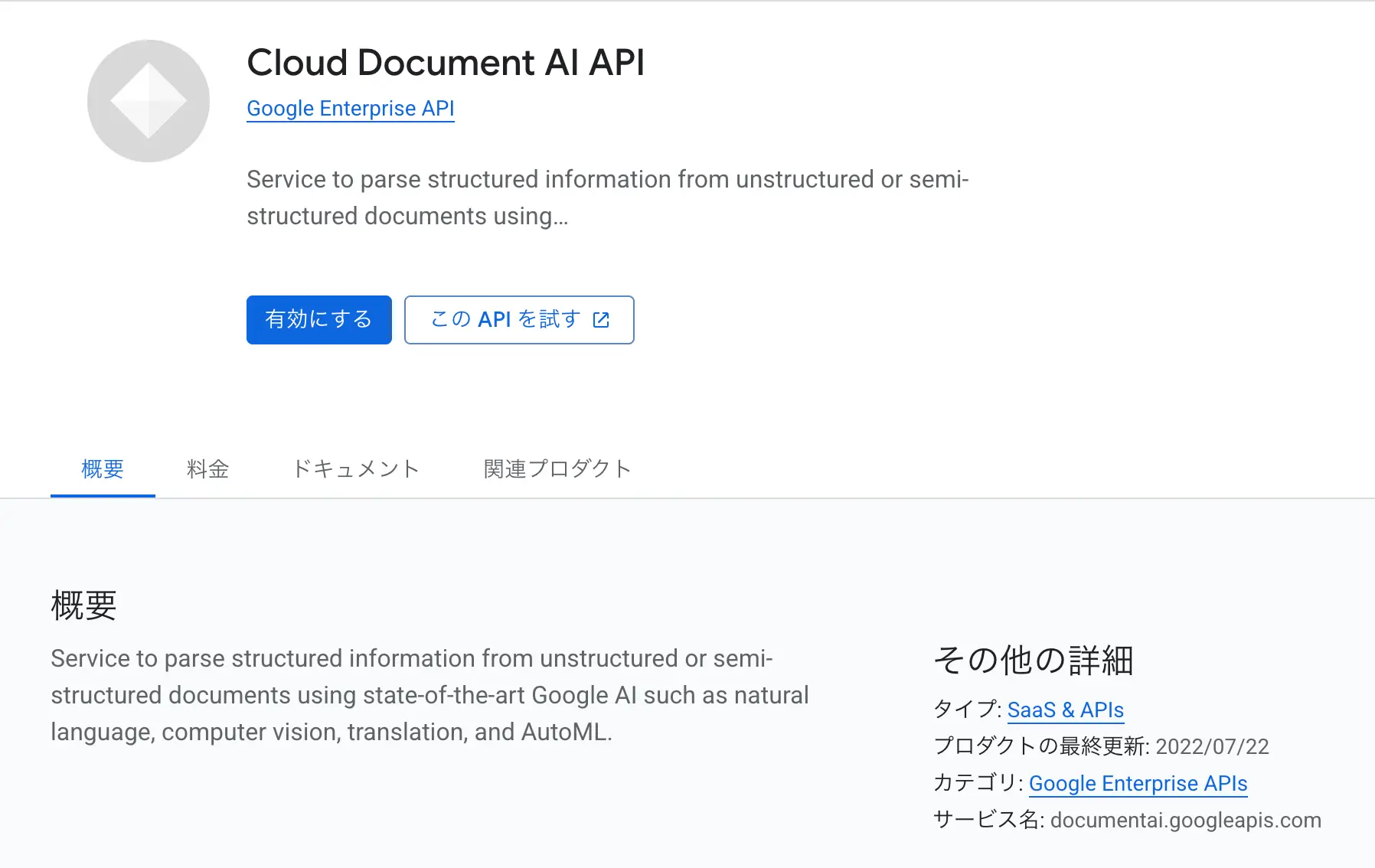
図:Cloud Document AI APIの有効化

図:GCS用のAPIも有効化しておく
サービスアカウントの作成
作成上の注意点
2024年より、新規のGoogle Cloudテナント作成時におけるデフォルトの組織ポリシー変更が発生しており、検証環境を作ってもらったはいいけれど、いざサービスアカウントを作成しようとすると作成権限が無いとして作れないといったケースが発生しています。
対象になるポリシーは「Disable service account key creation」であり、デフォルトで有効化されてしまっています。テナント作成担当者に伝えて、このポリシーをfalseにしてもらう必要があります。
他にも別のドメインのユーザをテナントのIAMに追加するものもできなくなっているので、他のドメインユーザをプロジェクトに参画させる場合には解除が必要です。
作成手順
GASで利用するサービスアカウントを用意する必要があります。このアカウントは1本でオッケー。以下の手順でGCP上でサービスアカウントを作成します。
-
GCP画面の左サイドバーより、IAMと管理⇒サービスアカウントを開く
-
上部にあるサービスアカウントの作成をクリックする
-
適当なサービスアカウント名、説明文を入れて作成して続行をクリックする
-
このサービス アカウントにプロジェクトへのアクセスを許可するでは、「Document AI 編集者 (Beta)」を追加します。
-
ほかは省略するので、完了をクリックして終わらせる
-
一覧に作ったサービスアカウントが出てくるので、アカウント名をクリックする
-
上部タブの「キー」をクリックして、鍵を追加⇒新しい鍵を作成をクリックする
-
キーのタイプはJSONを選び、作成をクリックする
-
JSONファイルがダウンロードされるので、Google Driveの安全な場所にアップロードする
- アップロードした10.のファイルのIDを取得する
作成したサービスアカウントおよびJSONキーは後ほど利用することになります。GCSにアクセスも必要なのですが、今回はDocument AI Userのロールだけでよしなにアクセス出来るので別途、「Storage オブジェクト ユーザー」というロールを付与する必要はありません。
※但しGAS側から直接GCSへアクセスして操作をする場合はロールの割当は必要になります。
※プロジェクト連結し、ScriptApp.getOAuthToken()でアクセストークンを取得する場合は、JSONキーファイルは不要です。
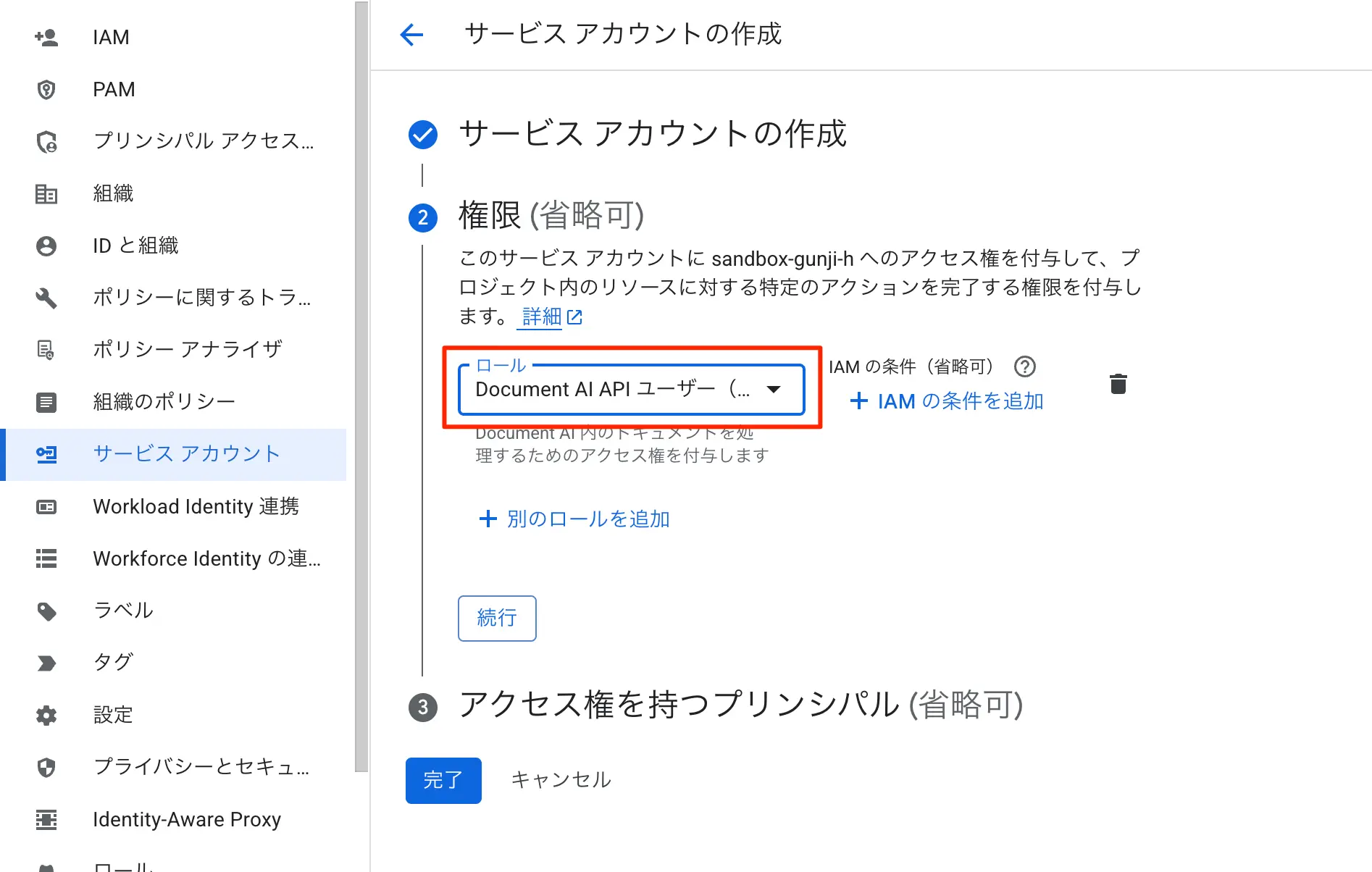
図:サービスアカウントを作成中
GCSのバケットを用意しておく
ここまで準備ができたら、あとはCloud Storage側にバケットを用意します。以下の手順でバケットを用意して、アップロード用コードの為のバケット名を取得しておきます。
- Cloud Consoleにて、Cloud Storageを開き、バケットの作成をクリック
- 名前に半角英数字で命名する。これがバケット名になる。今回は「driveman」というバケット名をつけました。
- 作成をクリックして完了。
- ここで、Document AI用のフォルダが必須です。作成しないと後述の作業で「データセットを構成できませんでした。プロセッサの詳細ページでデータセットを構成してください。」というエラーが出ます。また空っぽにしておく必要もあります。今回はdocumenaiという空のフォルダを作っておきました。
公開アクセスはしませんので注意してください。リージョンもデフォルトのusのままで今回は作成しています。この時つけたバケット名をDocument AIのカスタムプロセッサ作成時に必要になるので控えておきます。
※Document AI APIのリージョンもusにして合わせて上げる必要があります。
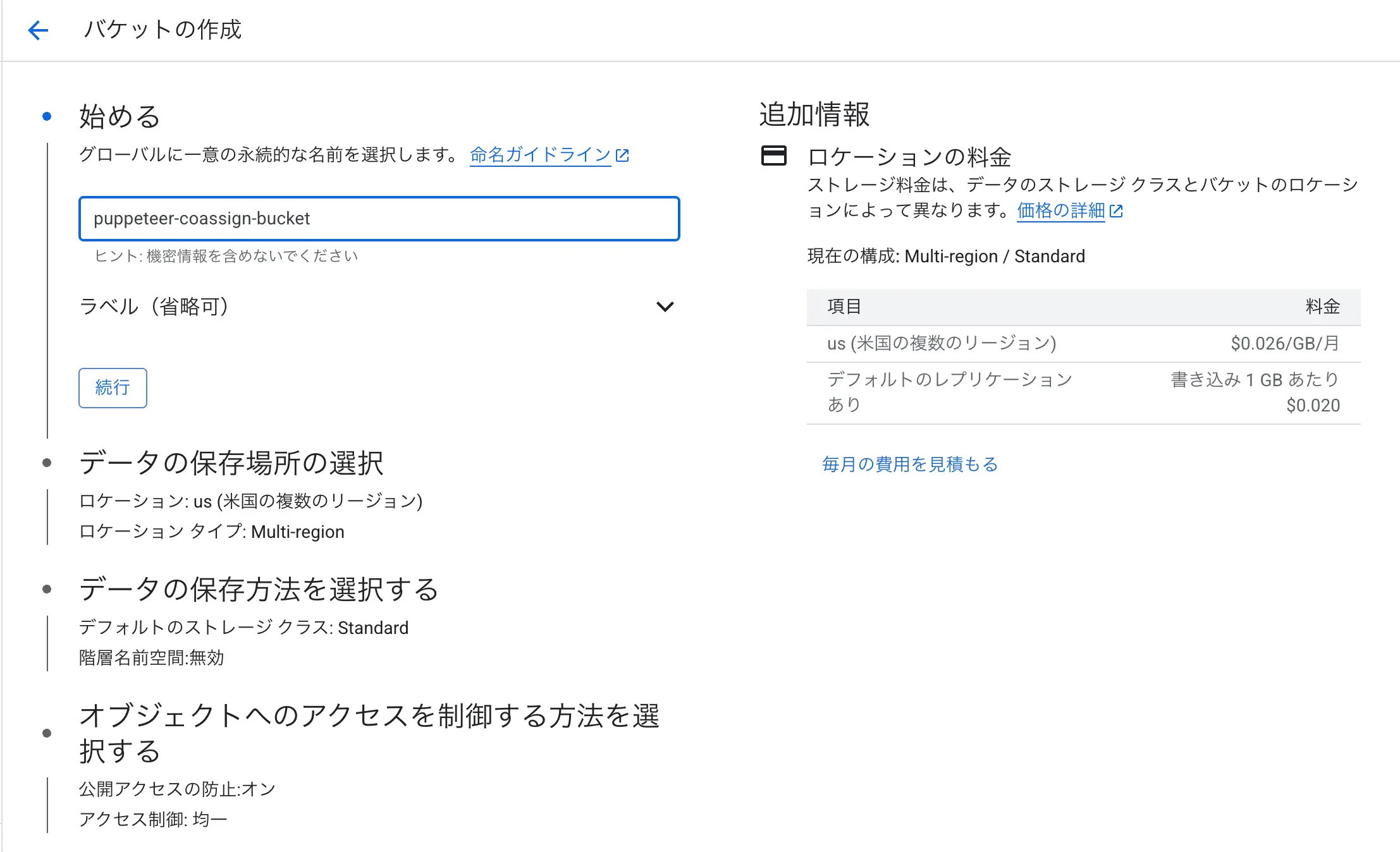
図:バケットを用意しましょう。
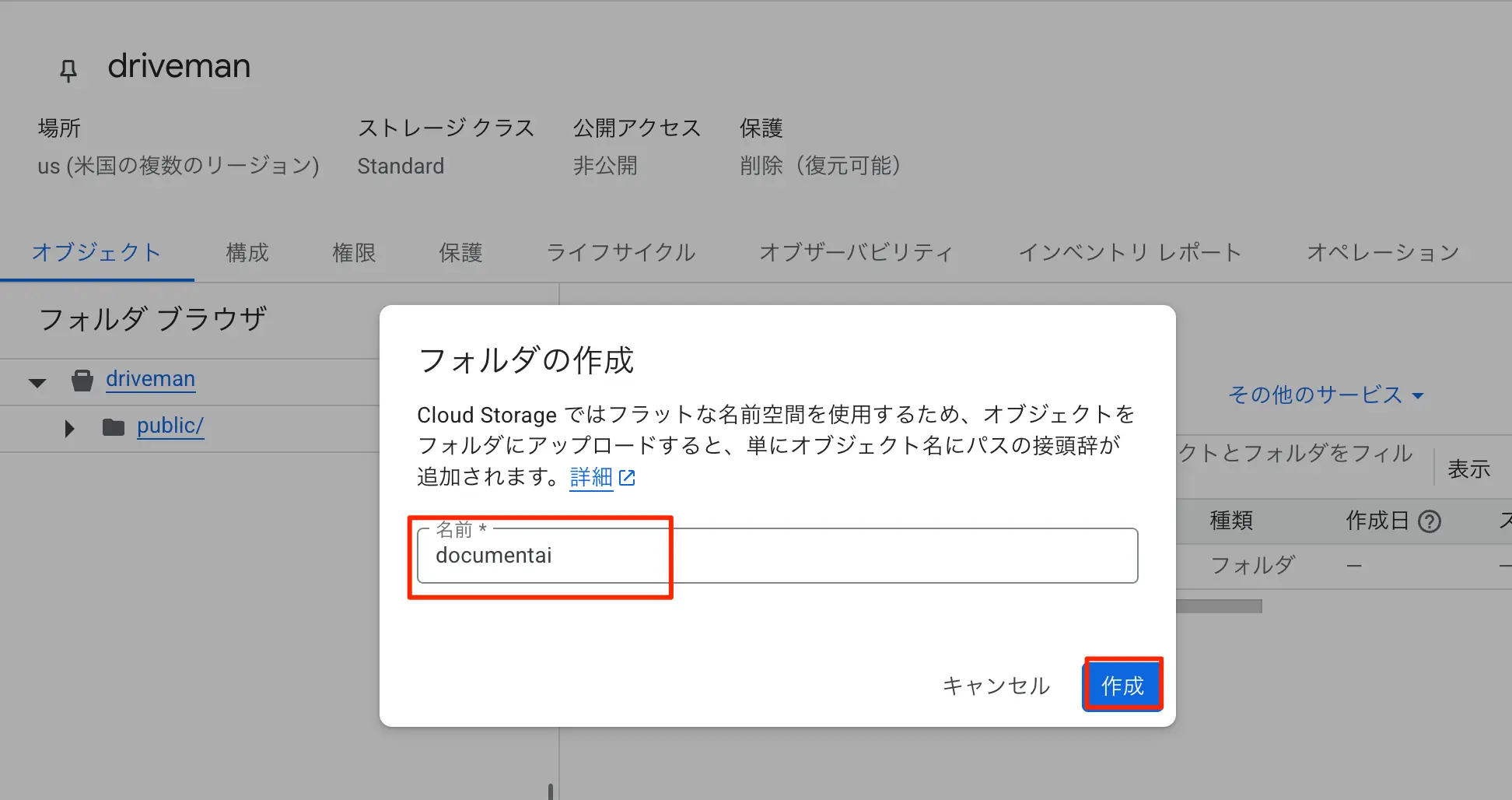
図:空のフォルダの作成も必須
GASプロジェクト
プロジェクト連携
GASのコンテナやプロジェクトを用意しておき、Google Cloudとプロジェクト連結をします。以下のエントリーを参考にプロジェクト連結をしておきましょう。
通常、ここでappsscript.jsonにスコープを追加して認証をすればリクエストが通るのですがDocument AIについてだけは特殊で、appsscript.jsonにスコープを記載してもNGであり、サービスアカウントからの呼び出しにだけ応答します。またOAuth同意画面で気密性の高いスコープとして検索しても、スコープ一覧にも出てきません。
よって、サービスアカウントを用意しOAuth2.0認証をしてUrlfetchAppからリクエストが今回の正しいリクエスト方法となります。
※プロジェクト番号で連結しますが、同時にエンドポイントURL用にプロジェクトIDも必要になるのでこの時点で取得しておきます。
スクリプトプロパティの設定
前述のサービスアカウントの作成時に作成しておいたJSONのキーファイルについて、手順10.にてファイルのIDを取得していると思います。これを使って認証を行うので、ファイルのIDをスクリプトプロパティに格納しておきます。
- jsonkey : サービスアカウントの鍵ファイルのIDを入れる
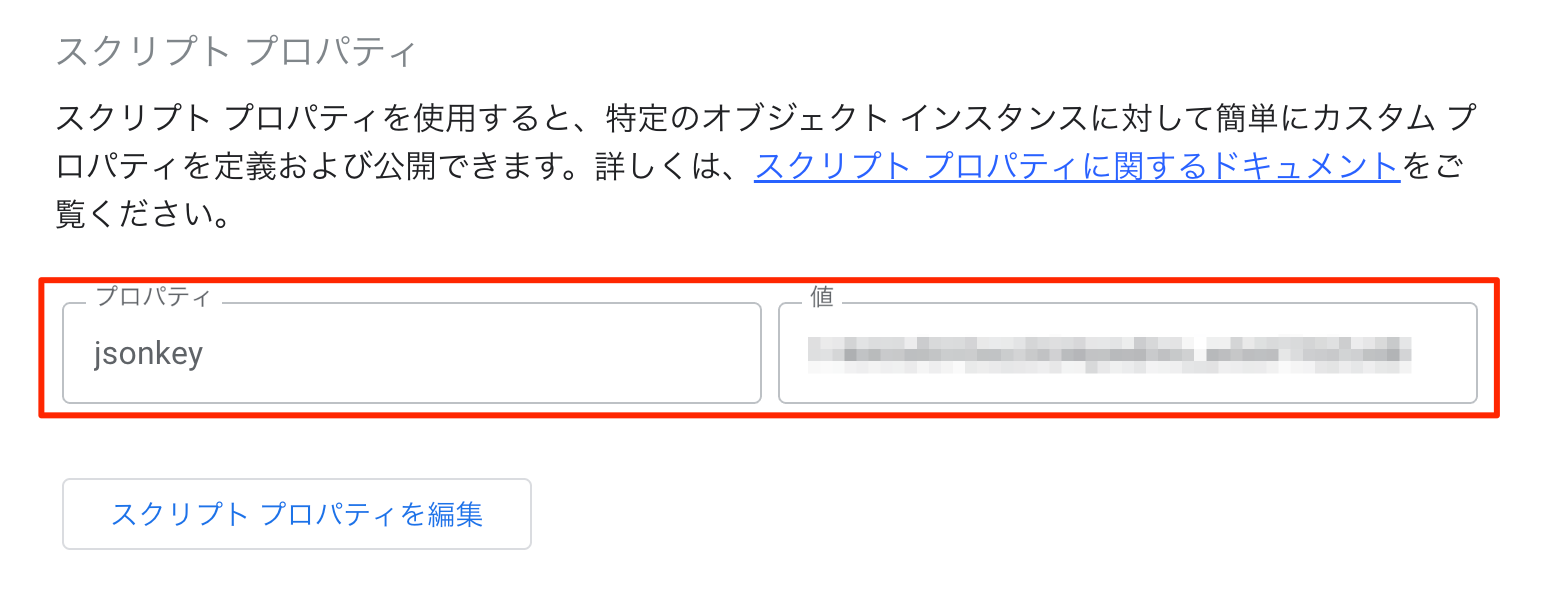
図:スクリプトプロパティにファイルIDを記述
appsscript.jsonに記述を追加する
スクリプトエディタの左サイドバーから「プロジェクト設定」を開き、「appsscript.json」マニフェスト ファイルをエディタで表示するにチェックを入れて、appsscript.jsonを表示する。その後そのファイルを開き、以下のように記述を行います。必須の作業です。これをしてしまうと、今後メソッドを追加したときに追加の認証は手動で、Scopeを入れてあげないと認証されないので要注意。
"oauthScopes":[ "https://www.googleapis.com/auth/script.external_request", "https://www.googleapis.com/auth/cloud-platform", "https://www.googleapis.com/auth/drive" ]
これを入れてあげないと403などのエラーになってしまうので要注意。GCPのAPIを叩く場合には必須の作業です。
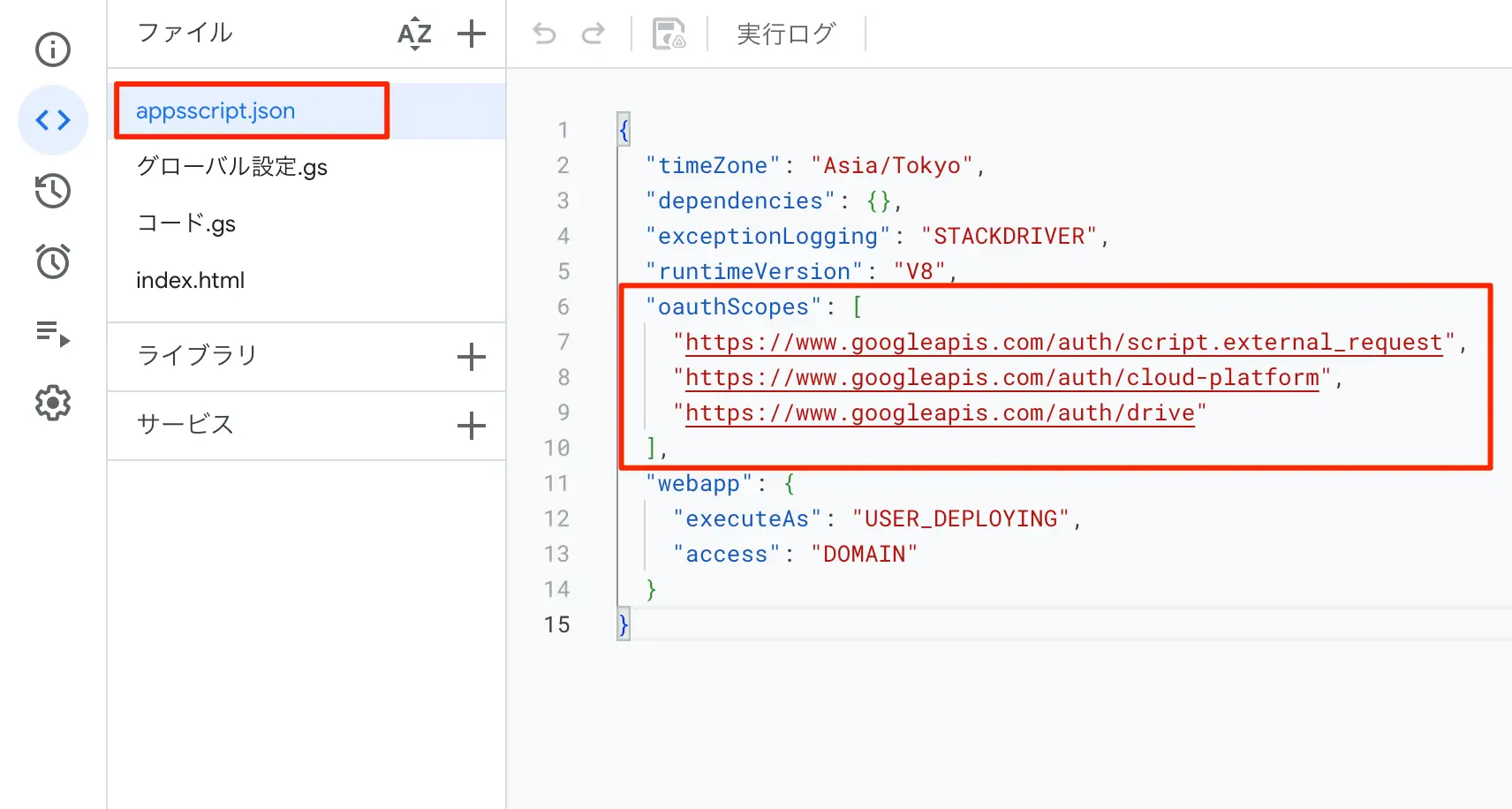
図:手動でスコープ追加が必要
グローバル設定
グローバル設定.gsというファイルをスクリプトエディタで用意しておき、以下のように記述しておきます。locationはGCSのロケーションと合わせる必要があるのでusのままでOKです。processorIdは後で書き換えを行います。
//エンドポイント用の変数
const projectId = 'ここにプロジェクトIDを入れておく';
const location = 'us'; // プロセッサを作成したリージョン (例: 'us' or 'eu')
const processorId = 'YOUR_DOCUMENT_AI_PROCESSOR_ID';
// Document AI APIのエンドポイントURLを構築
const url = `https://${location}-documentai.googleapis.com/v1/projects/${projectId}/locations/${location}/processors/${processorId}:process`;
Document AI
カスタムプロセッサの作成
前述のグローバル設定でセットするべきプロセッサーIDというものを用意する必要があります。以下の手順で用意します。請求書データからの取り出しというテーマであるので、「Custom Extractor」というプロセッサを利用します。
- こちらのURLをクリックする
- カスタムプロセッサを作成をクリックする
- Custom Extractorというものがあるのでプロセッサを作成をクリックする
- プロセッサ名を入れます(invoice-parserとしました)
- リージョンはusのままとします。
- 前述で用意しておいたGCSのバケットを指定します。独自の既存のストレージロケーションを指定をクリックします
- データセットフォルダの参照をクリックし、作成しておいたバケット=>作成済みフォルダを選びます。
- 作成をクリックする
これで入れ物が出来上がりました。
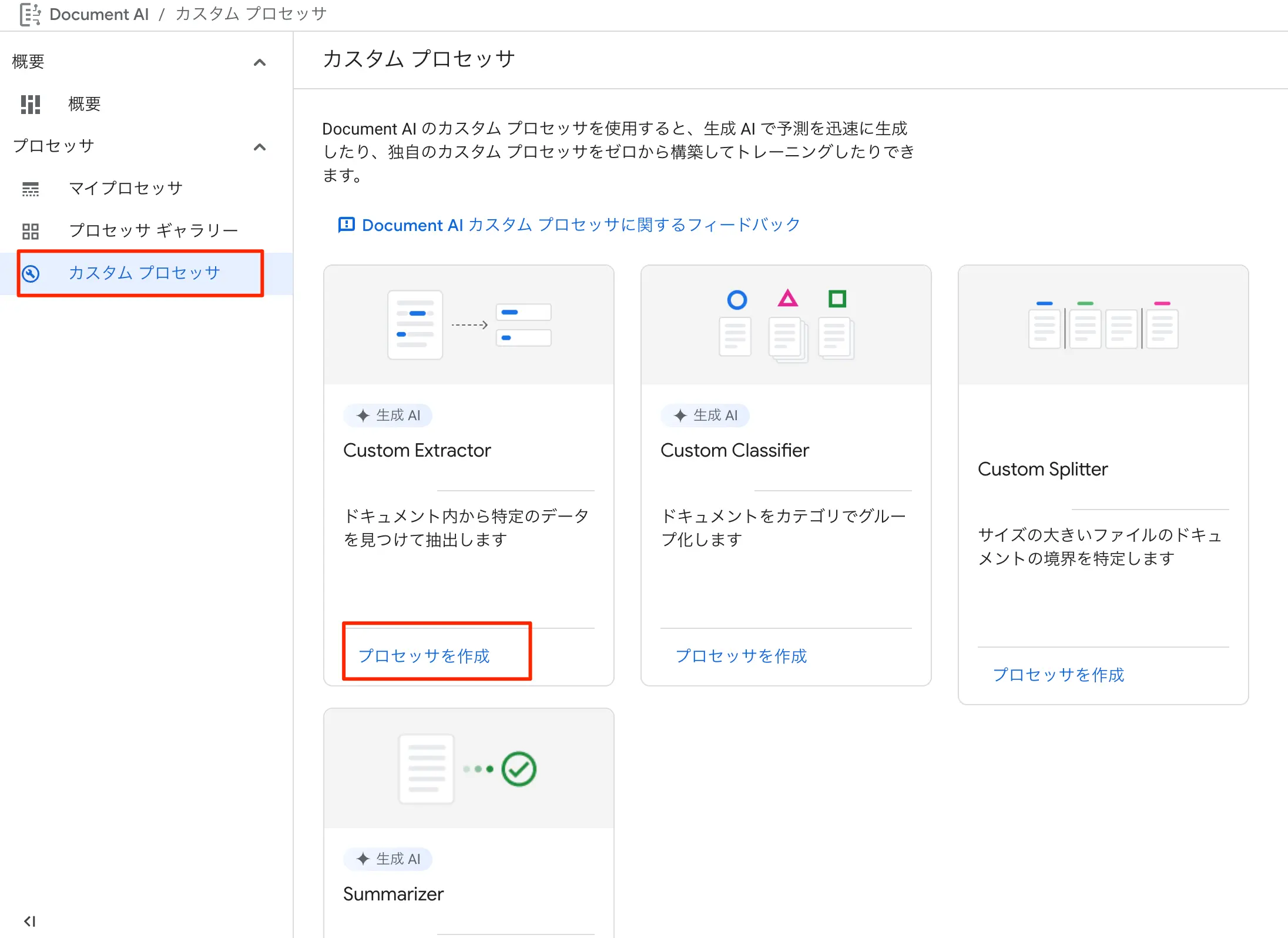
図:カスタムプロセッサから作成する
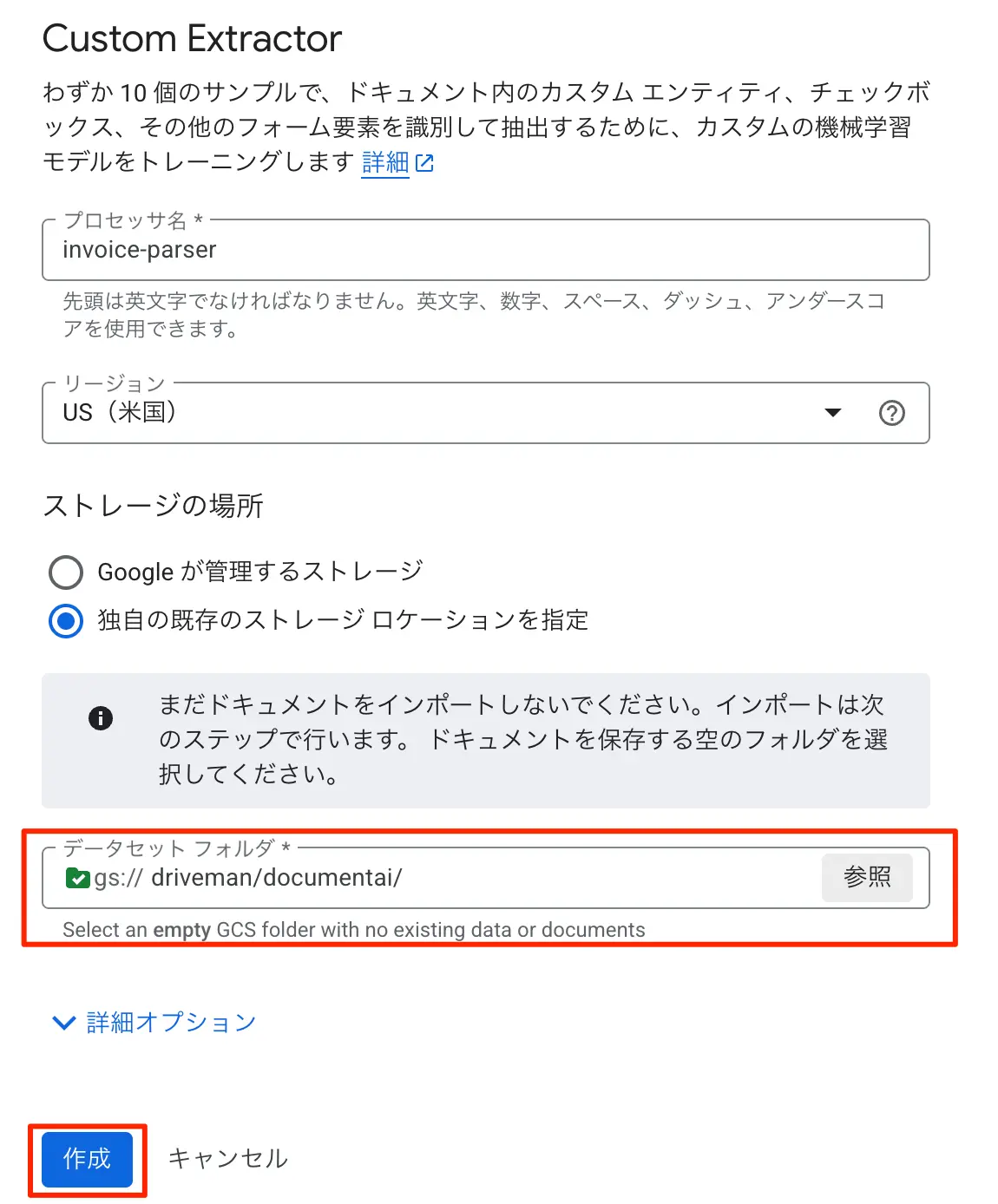
図:GCSのバケットを指定が必要
プロセッサIDの取得
プロセッサ作成が完了するとデータセットの初期化が始まり、すでにプロセッサの詳細という画面のハズ。この時、基本情報の中にIDという項目があり、ここにプロセッサのIDが記載されているので控えておき、前述のGASのグローバル設定のprocessorId変数の中に記述をしておきます。
予測エンドポイントに既に今回のGASからのリクエストに利用するエンドポイントURLが記述されていますが、これをGAS側のurl変数で組み立てています。
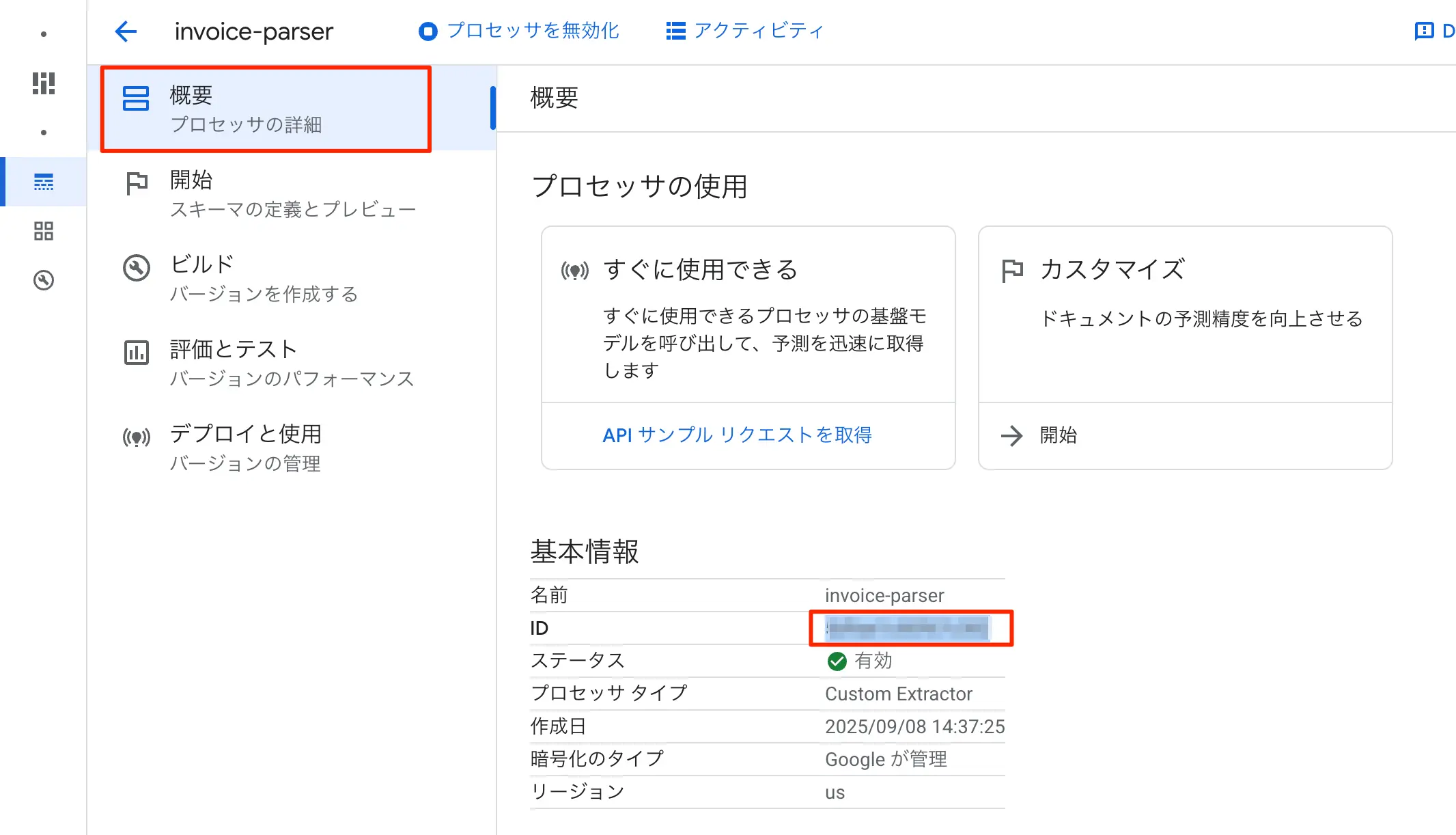
図:プロセッサIDを取得する
開発手順
スキーマ定義
請求書本体の定義
請求書データから一体何をどう取り込むのか?を定義するもので、フィールドを用意しますが請求書データは「請求書本体」と「請求明細」の2つで構成されています。その為単純に定義すると明細ってどうやって定義するのよ?と困惑することになります。以下の手順で作ってみましょう。サンプルドキュメントのアップロードからの作業が手軽です。
今回は請求書を受け取る側として作ってるので、発行元と顧客名とが逆になる点に注意が必要です。
- 前述で用意したプロセッサの画面を開く
- 概要が出ている状態なので、その下の「開始」をクリックします。
- サンプルドキュメントのアップロードをクリックして、ローカルから1枚アップロードしてみます
- フィールドを新規作成をクリックする
- 英語でフィールド名は定義します。まず請求書番号からやってみるのでinvoice_idとでもしておきます。
- メソッドは抽出。データ型は書式なしテキスト。エンティティはオプションの1回としました。Deriveとは他のフィールドを使って計算させる特殊な機能です。
- 作成をクリックする
- すると自動判定して、請求書番号に該当する内容を取ってきてくれます(かなり精度が良い)。間違ってる場合編集をクリックして、枠のドラッグ&ドロップで具体的な場所を任意に指定が可能です。
- 同様の手順で以下のような内容をフィールド定義します。インボイス番号や請求書発行元名がちょっとハードルかもしれない。total_amountは複数箇所出る可能性があります。
issue_date (発行日) due_date (支払期日) supplier_name (供給者名) customer_name (顧客名) total_amount (合計金額) invoice_num (インボイス登録番号)
- 一旦ここで、ラベル付きとしてマークをクリックして定義完了を行います。
他にも小計(税抜き)や消費税8%、消費税10%といった定義も必要になるかと思うのでこの部分で定義しておくと良いでしょう。Deriveで計算させてしまうというのも手です。
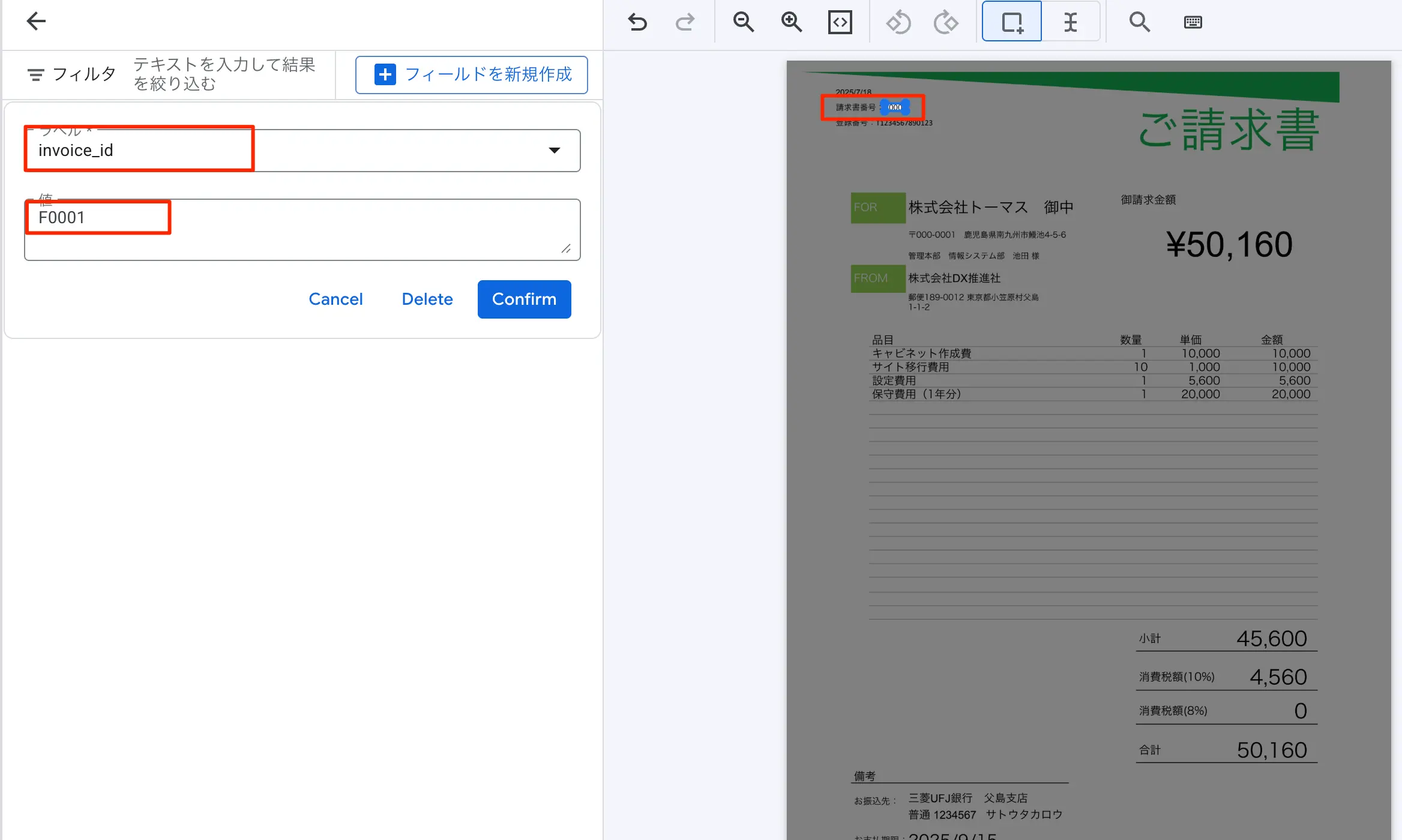
図:編集で手動で場所を指定してる様子
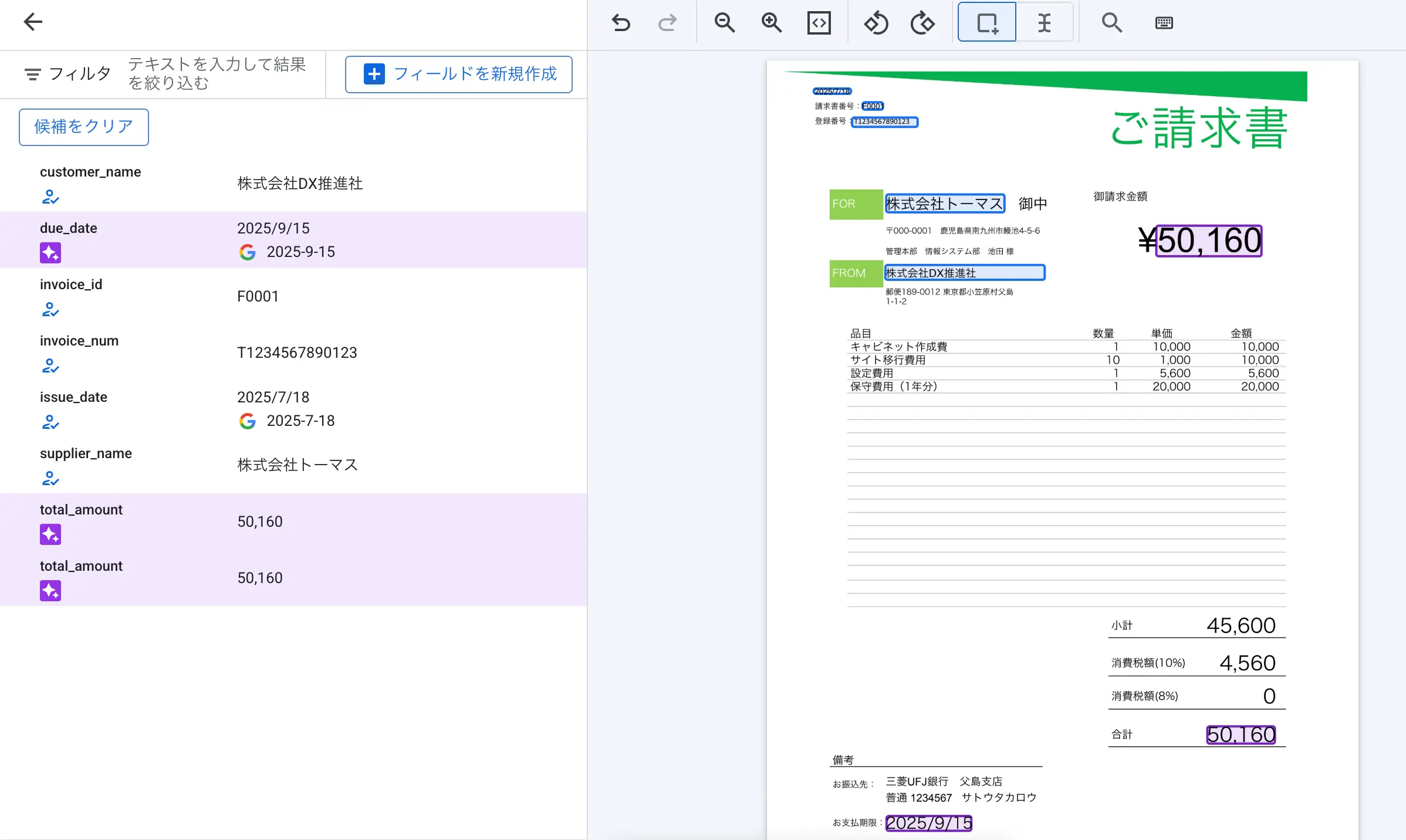
図:請求書部分の定義が完了
請求明細部分の定義
次に本丸の請求明細部分を定義するのですが、1つのプロセッサにセット出来る定義は1つだけなので、2つの定義は作れません。そこで、親ラベルという機能を作って、その下にネストする形で明細行部分の定義を作る必要があります。
サンプルアップロード画面で見ながらの定義が出来ないのでちょっと面倒です。
- 次に一番の壁である請求明細部分の定義を追加します。
- サンプルアップロードせず、フィールドの新規作成をクリックしてダイアログを出す
- 名前は「line_item」とし、「これは親ラベルである」のチェックを入れます。
- オカレンスは明細の無い請求書も考慮して、「オプションの複数回」を指定します。ラベルのプロンプトを指定することも出来るようです。
- 保存をクリックする
- 子を追加フィールドという部分をクリックする
- item_nameという定義を作り、オカレンス等の指定をしておく。プロンプトでは取りこぼしの無いように具体的な「品目や商品名、サービス名を取得する」といった指示を与えておく。
- 同様に以下のような定義を加えておく
description (商品名・説明) quantity (数量) unit_price (単価) amount (金額)
- 定義が完了したら終了です。
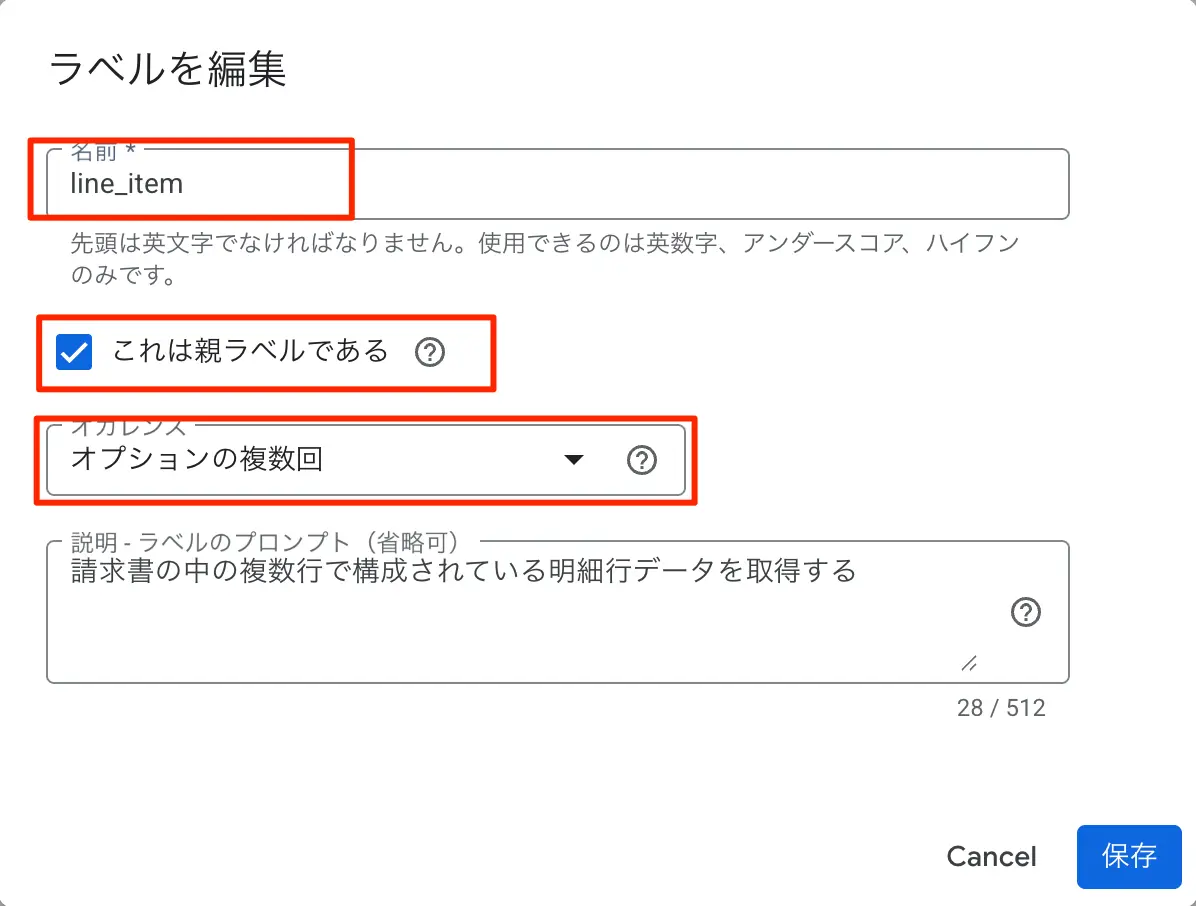
図:親ラベルとして定義が必要
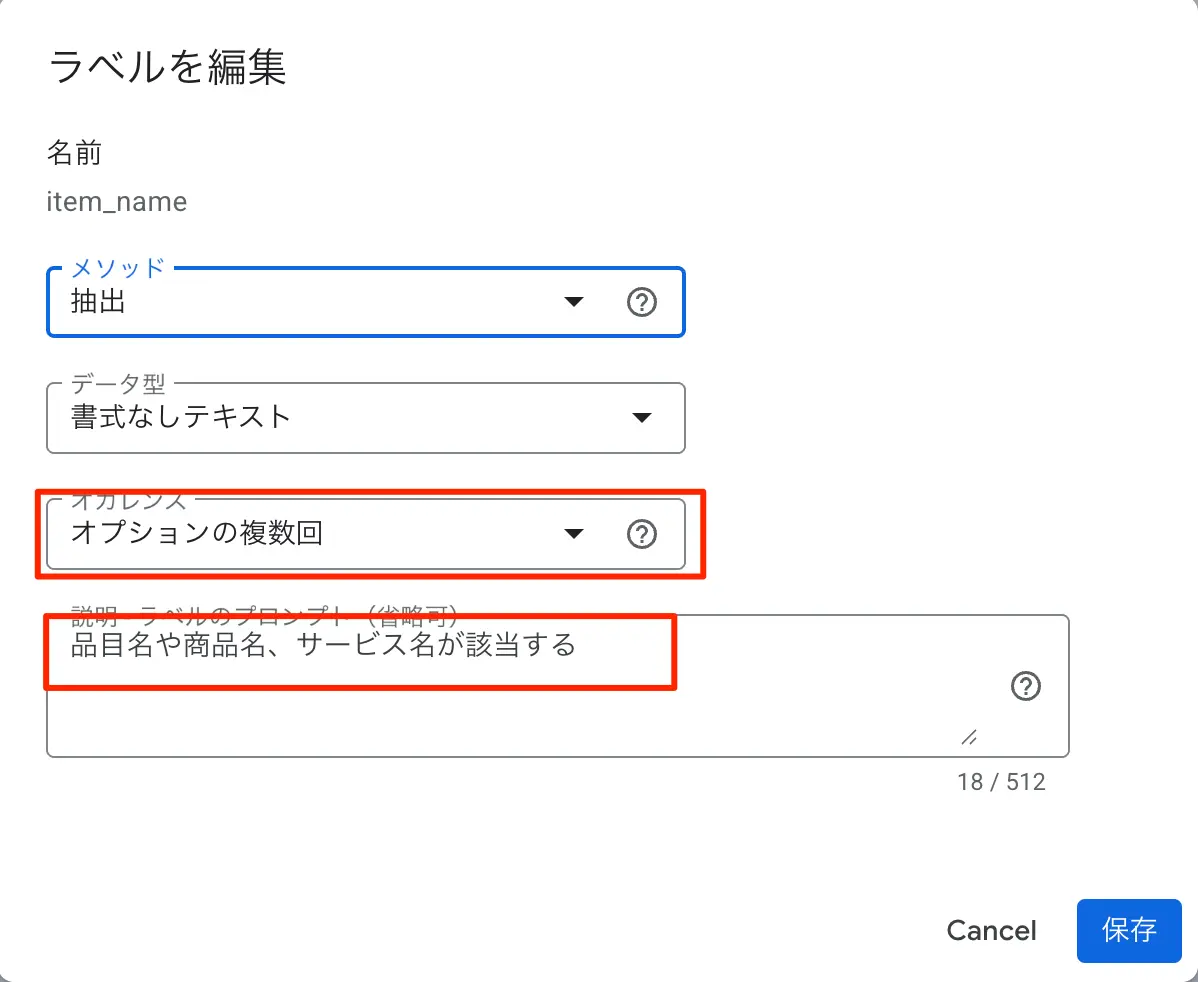
図:明細側のフィールドの定義
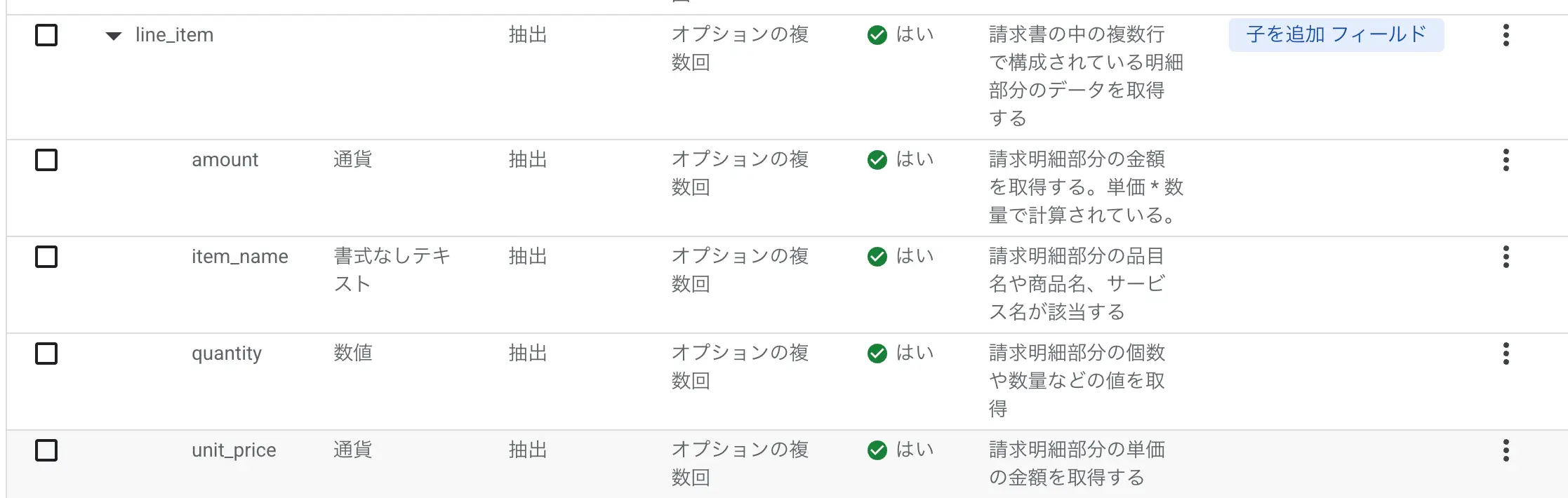
図:line_itemとして4列を定義しました
トレーニングデータの準備
様々なパターンの請求書のPDFデータを10枚用意しました(最低限これだけ必要のようです)。失敗するものもあるだろうなと思いつつ、そういった書式も現実に存在するので、まずはこれらをアップロードが必要です。以下の手順でアップロードします。
- 前述で用意したプロセッサの画面を開く
- 左サイドバーから「ビルド」をクリックする
- ドキュメントのインポートというボタンがあるのでクリックする
- ローカルコンピュータからインポートで次々とアップロードしていく
- データ分割は「トレーニング」を選択します。
- 自動ラベル付をインポートというチェックを入れてると定義から自動でラベル付作業をしてくれるようですが、今回はとりあえずスルーします。
- インポートをクリックする
GCSのバケットに直接入れてもここで取り込む内容を指定が必要なので、ローカルからインポートが一番楽ちんです。
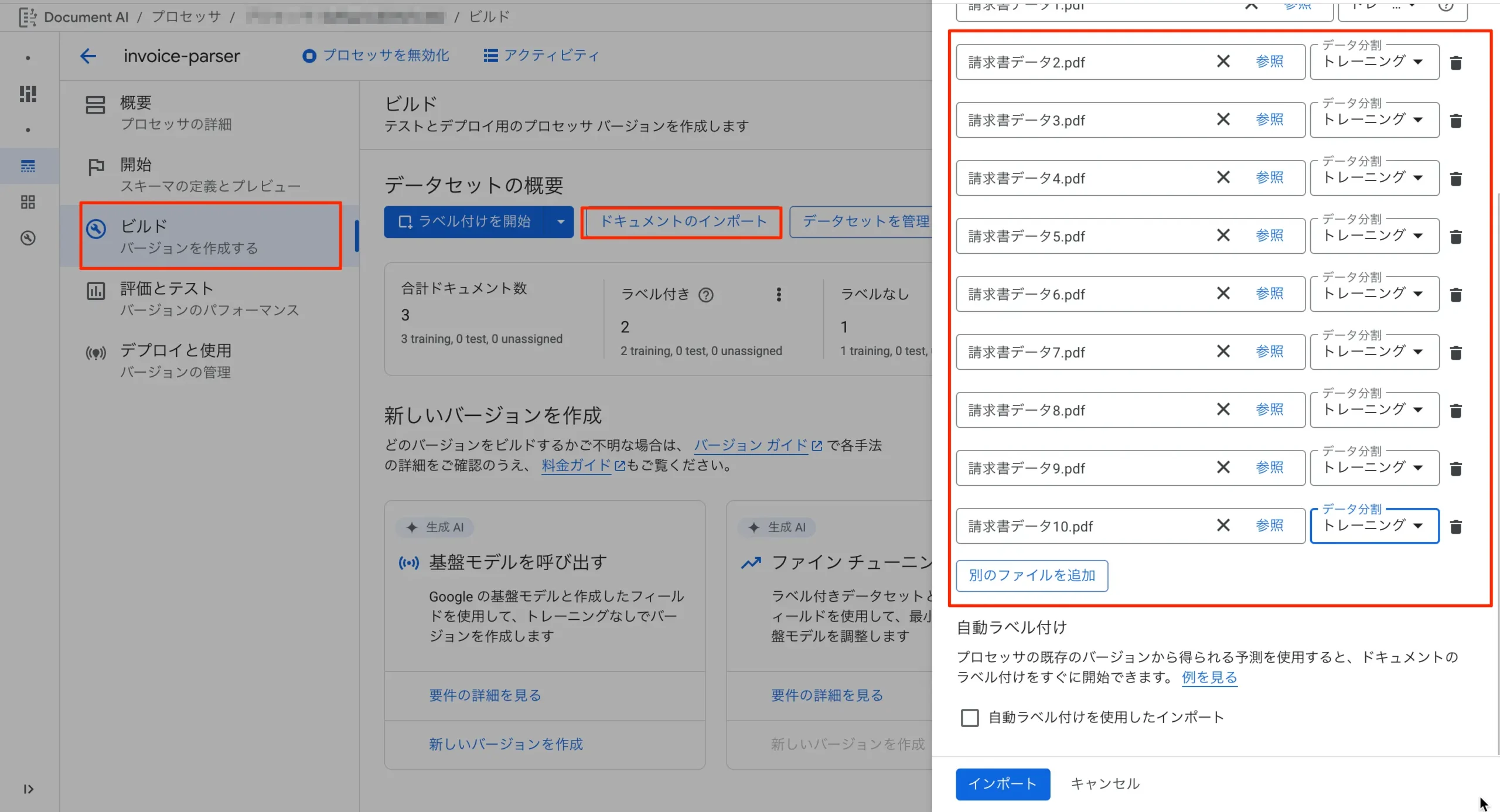
図:請求書サンプルを10パターンアップする
ラベル付け
前述で自動ラベル付けでインポートでも良いのですが、変な書式の請求書も世の中には沢山あります。そこで、インポートしたドキュメントに対して自分で定義したスキーマ定義からラベル付作業を次に行います。
- 同じくビルドの画面にて、次にラベル付けを開始をクリックします。
- サンプルドキュメントからのスキーマ定義画面同様のものが出てきます。
- 拾えていないものがあるので、編集ボタンや注釈を追加等をクリックして範囲指定等をして手動で指定してあげます。
- ここでポイントですが、明細行についてですが、10行あったら10行分全部をここで一個ずつ定義します。
- 1行目は注釈を追加にて、amount〜unitpriceまで一個ずつセル単位で囲って指定します。
- 次にインスタンスを追加で2行名を定義します
- 同様に10行分あれば10行分キッチリここで定義づけをしてあげます。
- ラベル付きとしてマークをクリックすると、次のサンプルを読み込みに行きます。
- 10個分のラベル付作業を完了させます。
一度ガッチリ定義すると次のサンプルPDFの場合かなりの精度で取ってきてくれるようになるのでラベル付作業は楽になります。
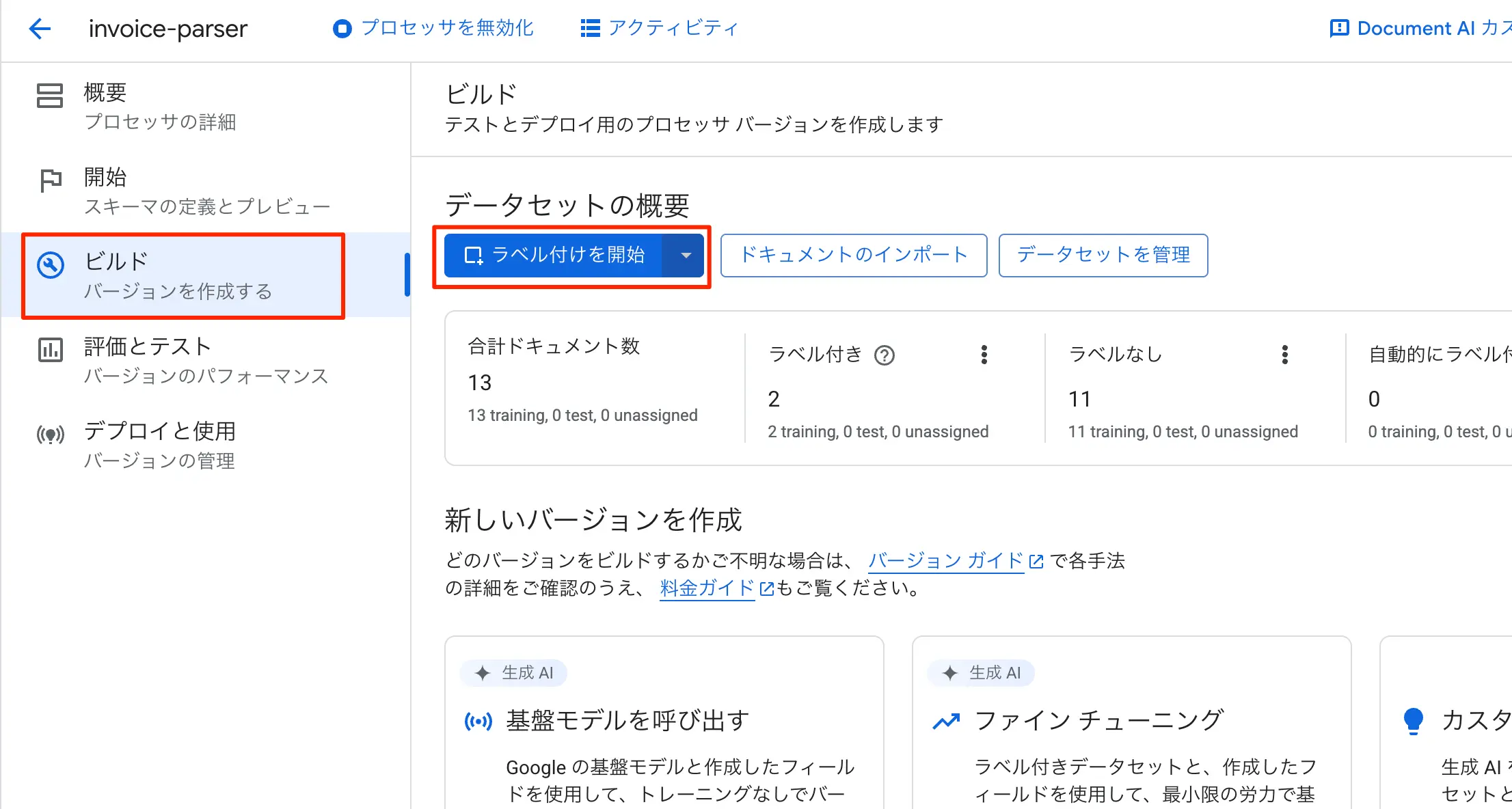
図:ラベル付を開始します
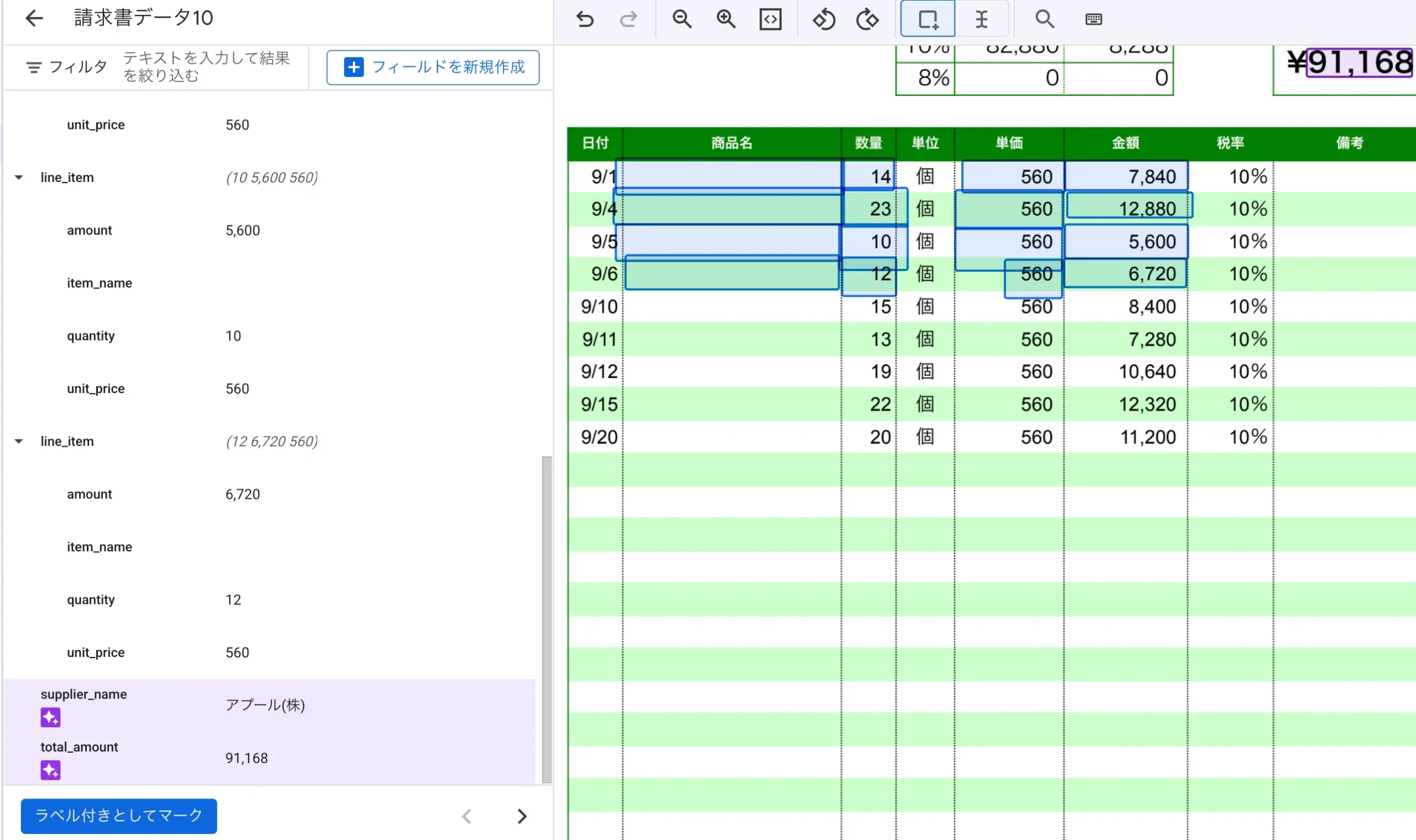
図:1行ずつ丁寧に明細などは拾って指定してあげる
トレーニングの実施
次に、同じビルド画面の下にある「新しいバージョンを作成」において、どのバージョンで構築するかを指定しますが、10枚程度のサンプルだと「基盤モデルを呼び出す」しか選択出来ません。25枚以上あるとファインチューニングやカスタムモデルのトレーニングを選べるようです。
今回は10枚しか用意していないので、基盤モデルを呼び出すで実行してみます。基盤モデルを呼び出すの新しいバージョンを作成をクリックします。バージョン名を指定してベースのバージョンはデフォルトの1.5proのままでオッケーです。今回は2025-06-20と日付の入ってるものを選びました。
作成をクリックします。ここでトレーニングが実施されるため、アップしてある枚数やスキーマの複雑さに応じて完了までに時間が掛かります。25枚程度だと30分〜2時間程度で完了するようです。
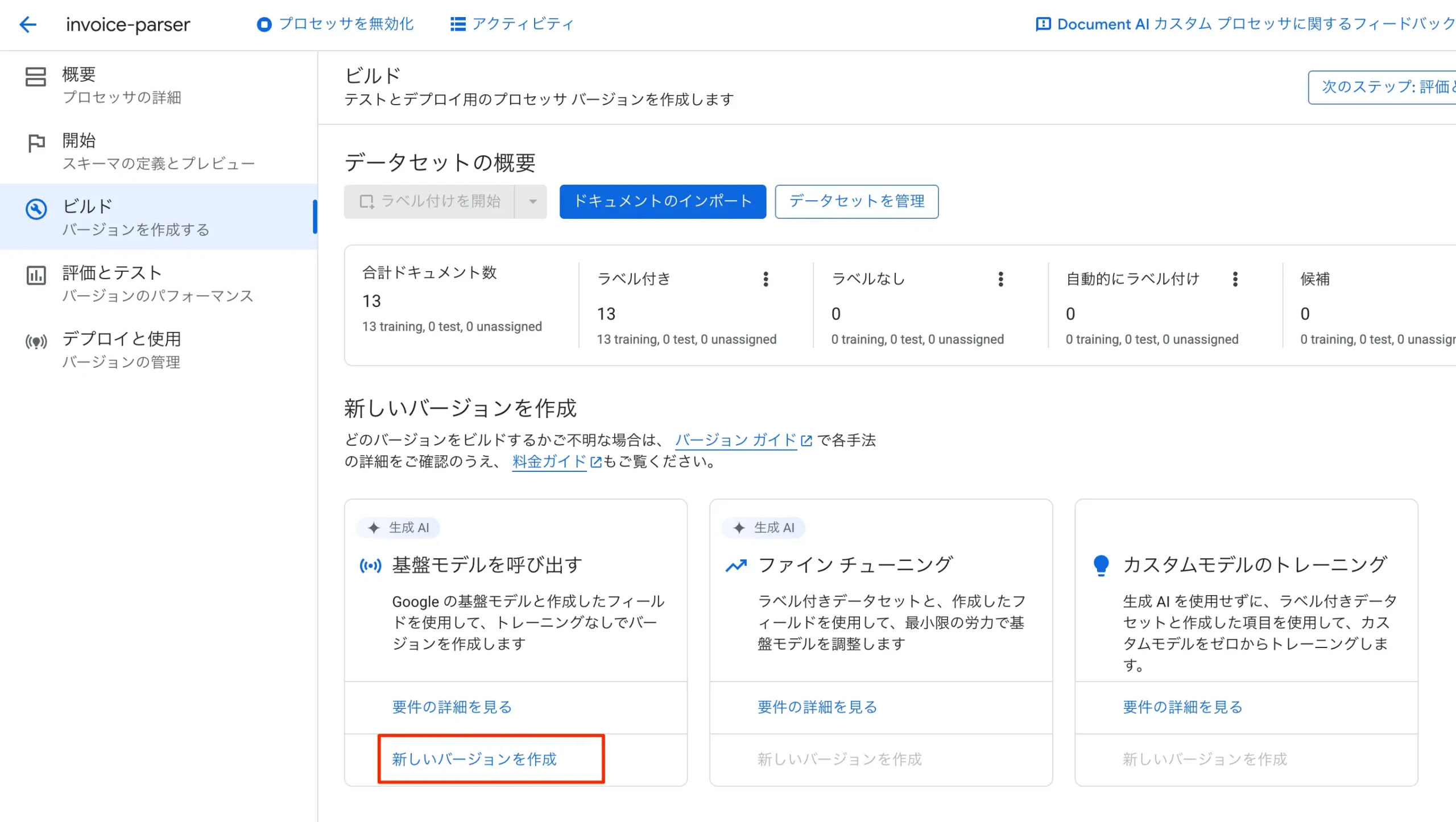
図:バージョン作成の実行
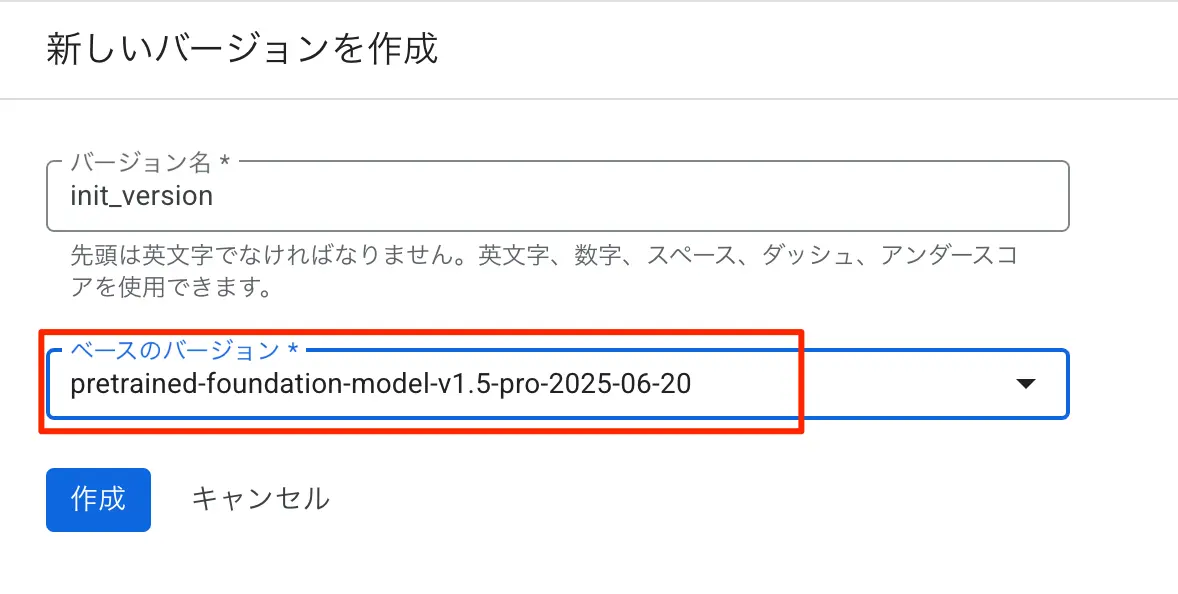
図:バージョンの指定を行う
デプロイの実施
評価とテストをする前に既存バージョンのデプロイをしろと怒られるので、以下の手順で作っておいたバージョンをデプロイします。
- 左サイドバーからデプロイと使用をクリックします。
- 先ほど作ったバージョンにチェックを入れて、デプロイをクリックします。
- 確認ダイアログが出るので、デプロイをクリックします。
- デプロイが完了するまで待機します。
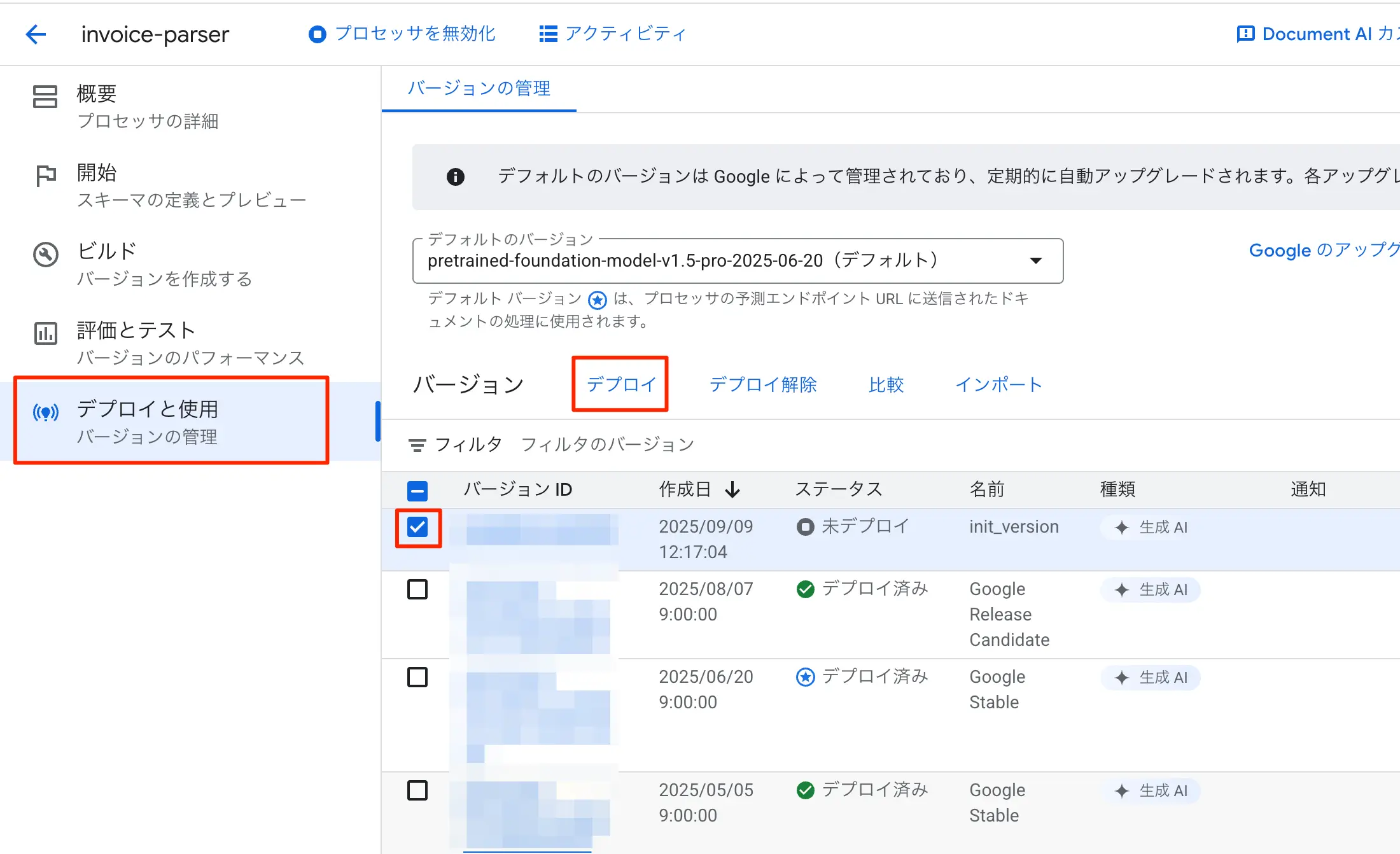
図:テスト実行前にデプロイをしておく
評価とテスト
ここまででサンプルファイルによるラベル付けや定義、トレーニングは完了しています。しかし、新たなタイプの請求書が来たら、またトレーニングに追加するのか?といったらそうではありません。ここまでの学習を元にして推測を行い、新しい未知の請求書でも対応出来なければシステムとして不完全です。
そこで、評価とテストにて新たにトレーニングで使用していない5枚程度の新しい請求書データを用意して食わせて、実践テストを行います。
- 左サイドバーから評価とテストをクリックする
- バージョンでは自身が先程選択して用意したものを選択する
- このバージョンのテストにある「テストドキュメントをアップロード」をクリックする
- 分析が開始されます。
- 無事に全部の項目がしっかりと拾えているかチェックする
- 5個全部をテストしていい感じであれば、このモデルの調整は完了となります。
ここでオカシナ点があったら、またトレーニングに追加して正しく拾えるように調整を続けていく必要があります。
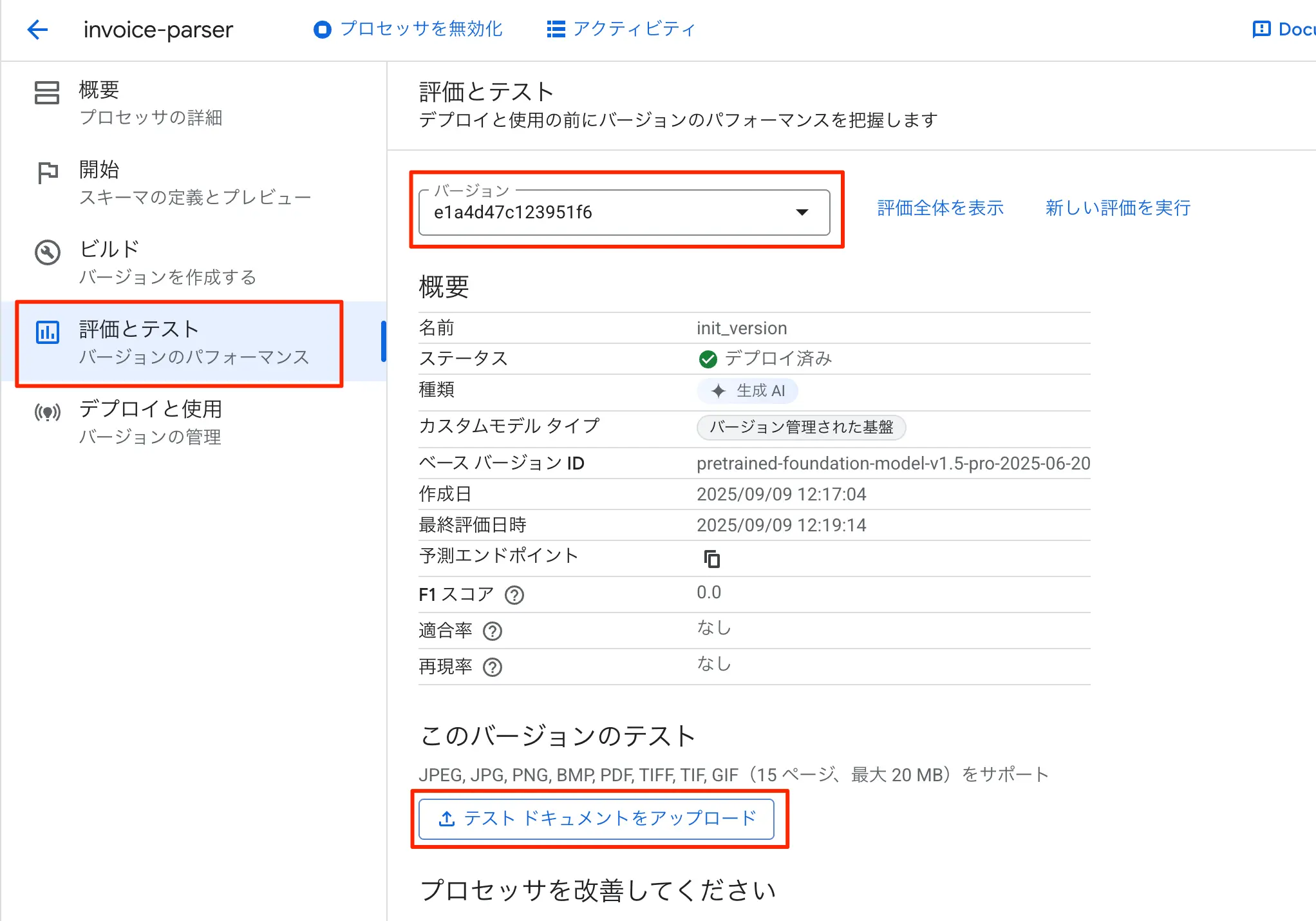
図:テストの実行をしましょう
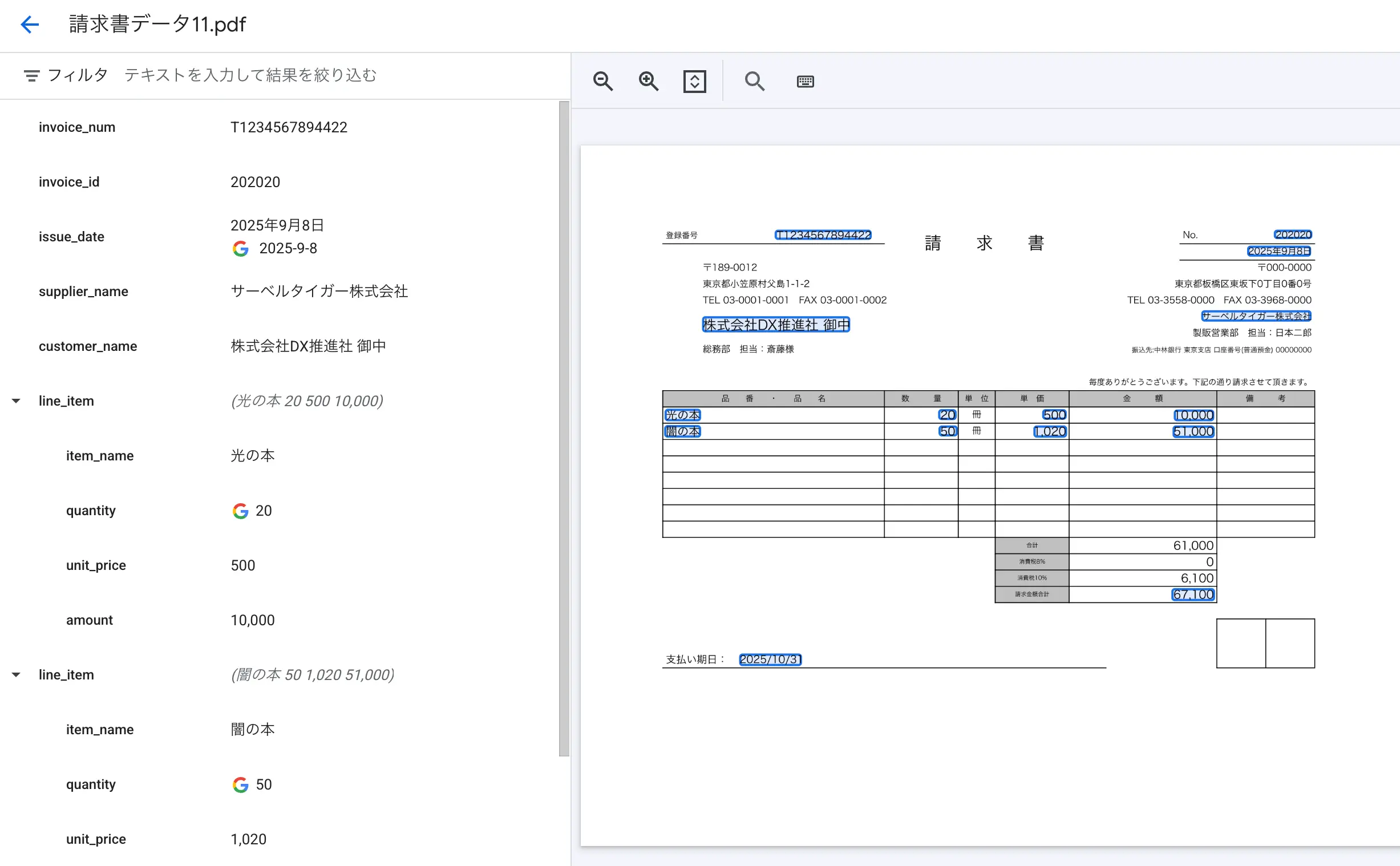
図:無事に全部正しく読めたようだ
GASからの呼び出し
概要
Document AIはそれそのものはインターフェースを持っていません。よって、処理をやらせるためには何らかのプログラムを外部に用意する必要があります。Gemini API同様にエンドポイントが個別に用意されるので、それに対して実行を指示して結果を受け取るために今回はGASで実装しました。
また、ある程度ためておいてバッチ処理で一括処理をやらせることも可能です。
Cloud Storageのトリガー + Cloud Run Functionsでアップロードを自動検知したら一連の作業を行わせて、対象のスプレッドシートに書き込むまでを自動化するという手段もあります。そちらについては以下のエントリーに別途切り出しましたので、興味ありましたら御覧ください。
完成品のコード
ここまでで自分で構築したモデルがきっちり動作するようになりました。しかし、用意したモデルというのはそれだけあっても何も出来ません。利用する為のフロントエンドが必要です(Vertex AI Studio上のChatから呼び出せるわけじゃない)。
そこで使うのがGoogle Apps Script。自身の用意したモデルに対してリクエストを送り、答えを得るという簡単なプロセスを構築できれば後はGASでBigQueryに蓄積するなり、Google Chat APIを使ってチャットのスペース上で使えるようにしたりすることが可能です。
以前作成したGemini APIで請求書データ全部引き抜くのと似てるコードですがプロンプトは一切ありません。独自のエンドポイントのURLに対してリクエストとPDFをBase64エンコードしたものをつけて送りつけて処理をし、JSON形式の構造化したデータで受け取るというスタイルです。
//Document AI APIを呼び出し、請求書PDFを処理するメイン関数
//引数に処理したいPDFファイルのIDを渡す
function processInvoice(pdfFileId) {
try {
// アクセストークンの取得
const accessToken = ScriptApp.getOAuthToken();
if (!accessToken) {
throw new Error('アクセストークンの取得に失敗しました。');
}
// DriveからPDFファイルを取得し、Base64にエンコード
const pdfBlob = DriveApp.getFileById(pdfFileId).getBlob();
const encodedPdf = Utilities.base64Encode(pdfBlob.getBytes());
// リクエスト用のPayloadを構築
const payload = {
"rawDocument": {
"content": encodedPdf,
"mimeType": "application/pdf"
}
};
// リクエストオプションを構築
const options = {
'method': 'post',
'contentType': 'application/json',
'headers': {
'Authorization': 'Bearer ' + accessToken
},
'payload': JSON.stringify(payload),
'muteHttpExceptions': true
};
//APIリクエストを実行
const response = UrlFetchApp.fetch(url, options);
//レスポンスを取得する
const responseCode = response.getResponseCode();
const responseBody = response.getContentText();
//リクエスト成功時
if (responseCode === 200) {
//レスポンスを取り出す
const result = JSON.parse(responseBody);
console.log(result.document)
//構造化されたデータに変換
const structuredData = parseDocumentAiResponse_(result.document);
//結果を表示する
console.log(structuredData);
} else {
console.log(`エラーが発生 ${responseCode}`);
console.log(`エラーレスポンス: ${responseBody}`);
}
} catch (e) {
console.log(`エラーが発生しました: ${e.message}`);
console.log(`スタックトレース: ${e.stack}`);
}
}
//APIからの返り値をJSONで構造化する関数
function parseDocumentAiResponse_(document) {
const extractedData = {
fields: {},
lineItems: []
};
// document.entities をループして、単純な項目とテーブル項目を振り分ける
(document.entities || []).forEach(entity => {
//単純なキーと値のペアの場合 (mentionTextを持つ)
if (entity.mentionText) {
extractedData.fields[entity.type] = entity.mentionText;
//テーブルの行(line_item)の場合 (propertiesを持つ)
} else if (entity.type === 'line_item' && entity.properties) {
const lineItem = {};
// 入れ子になったプロパティをループして、列と値を取得
entity.properties.forEach(prop => {
lineItem[prop.type] = prop.mentionText;
});
extractedData.lineItems.push(lineItem);
}
});
return extractedData;
}
ちなみに、サンプルのPDFを読み込ませて返ってきた返り値のレスポンスは以下のような構造になりました。fields直下は請求書部分のデータ、lineItems以下のデータが請求明細のデータになります。
それぞれを取得してスプレッドシートに書き出すなり、AppSheetなどを使って表示するなりこの後の処理をつなげることで、Document AIで構築した独自モデルを活かすことが可能になります。
今回は請求書でしたので、この後処理としてはインボイス番号を用いて、適格請求書発行事業者公表システムWeb-API機能を使って正確な企業情報を取得してマージするであったり(住所等の情報はこちらで取れるので無理にOCRしなくて良い)、電子帳簿保存法に従って、対象のファイルを別の場所にアーカイブするであったり、また取得した年月が和暦なので西暦に変換したり、全角半角の統一や余計なハイフンの除去などのデータクリーニングといった作業なども備えることで、社内システムとして仕上がると思います。
{
fields:
{
customer_name: '株式会社DX推進社 様',
due_date: '2025年05月20日',
invoice_id: '21310',
invoice_num: 'T1234567892223',
issue_date: '2025年04月20日',
supplier_name: '株式会社十夢',
total_amount: '6,314'
},
lineItems:
[
{
amount: '450',
item_name: 'まぐろ',
quantity: '1',
unit_price: '450'
},
{
amount: '500',
item_name: 'ギンガメアジ',
quantity: '5',
unit_price: '100'
},
{
amount: '690',
item_name: 'トビウオ',
quantity: '3',
unit_price: '230'
},
{
amount: '1,200',
item_name: 'ハタ',
quantity: '4',
unit_price: '300'
},
{
amount: '500',
item_name: 'ボラ',
quantity: '1',
unit_price: '500'
},
{
amount: '2,400',
item_name: 'ミズイカ',
quantity: '10',
unit_price: '240'
}
]
}
おまけ
今回、サービスアカウントなので自身で認証は行っていません。裏でScriptApp.getOAuthToken()としておくことで、プロジェクト連結されてるので勝手に取ってきてくれます。
一方でJSONキーを使って認証をすることも出来ます。その場合には以下のようなAccess Token取得をリクエストして取ることが出来ました。この場合プロジェクト連結しなくても行けるのではないかと思います。
//サービスアカウントを使ってアクセストークンを取得する
function getServiceAccountAccessToken() {
const scriptProperties = PropertiesService.getScriptProperties();
const keyFileId = scriptProperties.getProperty('jsonkey');
if (!keyFileId) {
throw new Error('スクリプトプロパティ "jsonkey" が設定されていません。');
}
// 秘密鍵JSONを取得
const keyFileContent = DriveApp.getFileById(keyFileId).getBlob().getDataAsString();
const serviceAccount = JSON.parse(keyFileContent);
const privateKey = serviceAccount.private_key.replace(/\\n/g, '\n');
const clientEmail = serviceAccount.client_email;
// JWT ヘッダー
const header = {
alg: "RS256",
typ: "JWT"
};
// JWT クレームセット
const now = Math.floor(Date.now() / 1000);
const claimSet = {
iss: clientEmail,
scope: "https://www.googleapis.com/auth/cloud-platform",
aud: "https://oauth2.googleapis.com/token",
exp: now + 3600, // 1時間有効
iat: now
};
// Base64URL エンコード
function base64UrlEncode(str) {
return Utilities.base64EncodeWebSafe(str).replace(/=+$/, "");
}
// JWT 署名用文字列
const jwtHeader = base64UrlEncode(JSON.stringify(header));
const jwtClaim = base64UrlEncode(JSON.stringify(claimSet));
const unsignedJwt = jwtHeader + "." + jwtClaim;
// 署名
const signatureBytes = Utilities.computeRsaSha256Signature(unsignedJwt, privateKey);
const signature = Utilities.base64EncodeWebSafe(signatureBytes).replace(/=+$/, "");
const signedJwt = unsignedJwt + "." + signature;
// アクセストークンを取得
const response = UrlFetchApp.fetch("https://oauth2.googleapis.com/token", {
method: "post",
payload: {
grant_type: "urn:ietf:params:oauth:grant-type:jwt-bearer",
assertion: signedJwt
}
});
const result = JSON.parse(response.getContentText());
if (!result.access_token) {
throw new Error("アクセストークン取得失敗: " + response.getContentText());
}
console.log("AccessToken:", result.access_token);
return result.access_token;
}
関連動画


関連リンク
- Vertex AIとは?使い方や料金、GoogleのGeminiとの違いも紹介
- 生成 AI をあなた用にカスタマイズ!Vertex AI Studio の使い方と機能紹介
- 【初学者向け】Vertex AI の使い方と機能の紹介
- Google AI StudioとVertex AI Studioの違いを解説!機能や料金まで比較
- Vertex AI Searchが切り拓く、RAG開発の新境地
- 【Google Cloud】Vertex AIのグラウンディングに独自のデータを利用する
- GA になった RAG Engine で Gemini がもっと賢くなる!
- トレーニング方法を選択する
- Vertex AI カスタム トレーニングの概要
- Document AIを徹底解説
- Document AIで独自OCRモデルをトレーニングしてみた
- Google Cloud で機械学習モデルを使うときの方針
- Vertex AIの勉強
- Google Document AIとは何ですか?基本情報とその重要性について
- ウェブサーバー アプリケーションに OAuth 2.0 を使用する
- Document AI を使った請求書読み取り機能の検証
