Node.jsとPuppeteerでChromeを自動操縦する
ウェブブラウザを用いたウェブアプリケーションの自動操作は、昔と違って妙に需要があります。これまでのローカルアプリケーションの操作は、VBAなどがDLLを介して行う事ができました。ウェブブラウザの場合、Selenuim Basicを使って操作することも可能です。
一方で現代の多くのウェブアプリケーションはREST APIを装備しているので、人間が操作するような操作方法を持ってして、作業を再現するような事も不要になりつつありますが、コードの記述を必要とするため、RPAなどを用いて作ってるのが現状です。
今回、GoogleのChromeチーム謹製のChromeを操作するNode.jsライブラリ「Puppeteer」を用いて、ブラウザ操作の自動化と、ついでに単独実行ファイル化をやってみたいと思います。
※Microsoft Playwrightと呼ばれるPuppeteerフォークがあり、こちらはSafariやFirefoxも同様に操作が可能みたい。ただまだリリースしたばかりで、APIが変更される可能性もあるので、注意が必要です。
※Puppeteer-clusterと呼ばれる、複数同時並行でPuppeteerを動かす場合に色々制御しながらよしなにやってくれるものも存在します。Puppeteer-core同様、インストール済みのChromeを指定出来るので、利便性が高いです。サーバ等で同時並行で動かす場合、動作させるPuppeteerの数を制限出来るので、リソース食い尽くすといったようなケースの対応策で有効です。
目次
今回使用するライブラリ等
puppeteerというモジュールもありますが、coreと違いChromiumを別途ダウンロードしてしまい、ファイルサイズが大きくなります。coreはすでにインストール済みのChromeを使う場合に利用します。今回は後者のケースで作ってみたいと思います。
インストールは以下のコマンド一発で終了です
npm i puppeteer-core
pkgした実行ファイルは、ダブルクリックするだけで、Node.jsが入っていない環境でもPuppeteerが動き、Chromeを自動操縦します。
ソースコード
今回Googleを開き、「三峯神社」を検索し、スクリーンショットを取るというところまでを色々無駄にオプション設定して動かすコードをindex.jsに作り、node.jsで実行してみました。
const puppeteer = require('puppeteer-core');
(async () => {
//option
var option = {
headless : false,
executablePath: '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome',
slowMo:500,
args: [
// ゲストセッションで操作する。
"--guest",
// ウインドウサイズをデフォルトより大きめに。
'--window-size=1280,800',
//最大化で表示
'--start-fullscreen',
//情報バーの非表示
'--disable-infobars',
//シークレットモード
'--incognito',
],
}
const browser = await puppeteer.launch(option)
const page = await browser.newPage()
await page.setViewport({
width: 1280,
height: 700,
deviceScaleFactor: 1,
});
await page.goto('https://www.google.com/')
await page.type('input[name=q]', '三峯神社', { delay: 100 })
await page.click('input[type="submit"]')
await page.waitForSelector('h3 a')
await page.screenshot({ path: 'screenshot/result.png', fullPage: true})
await browser.close()
})()
- 予め、index.jsのあるフォルダ内にscreenshotというフォルダを作成しておく必要があります。
- optionとしてexecutablePathでChromeアプリがある場所までフルパスで指定してあります。
- headlessをfalseにすると、headlessモードではないseleniumのようにChromeを表示して動きを確認可能です。
- slowMoでミリセカンドを指定すると、動作を遅くすることが可能です。
- page.setViewportでサイズを指定しないと、chrome内でやけに狭い範囲で表示されてしまいます。
- screenshotでfullPageをtrueにすると現在表示されてる全部のスクリーンショットを取れます。
- Microsoft Edgeの最新版は中身がChromeなので、Puppeteerでコントロールが可能です。その場合のexecutablePathは「C:\\Program Files (x86)\\Microsoft\\Edge Dev\\Application\\msedge.exe」になります。macOS版だと「http://applications/Microsoft/ Edge/ Canary.app/」になるようです
図:こんな感じでresult.pngが出来ます。
Puppeteerが起動しない
オプションの追加が必要なケース
自宅のPCやmacOSでは問題なく動作するのに、会社のPCでは以下のようなエラーが出て起動しない!!というケースがあります。こちらでも言及されていますが、これに対する対応策は公式サイトにて、掲示されています。以下のようなoptionを追加する事で、起動するようになります。
//オプションを1個追加するだけ
const browser = await puppeteer.launch({
ignoreDefaultArgs: ['--disable-extensions'],
});
エラーは以下のようなもの
(node:888) UnhandledPromiseRejectionWarning: Error: Failed to launch the browser process!
TROUBLESHOOTING: https://github.com/puppeteer/puppeteer/blob/master/docs/troubleshooting.md
at onClose (C:\Users\user\Documents\puppeteer\node_modules\puppeteer-core\lib\Launcher.js:750:14)
at ChildProcess.<anonymous> (C:\Users\user\Documents\puppeteer\node_modules\puppeteer-core\lib\Launcher.js:740:61)
at ChildProcess.emit (events.js:228:7)
at Process.ChildProcess._handle.onexit (internal/child_process.js:272:12)
(node:888) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). (rejection id: 1)
(node:888) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
Failed to launch the browser processというエラーです。puppeteerでchromiumを使っても同様にエラーがでます。必ず、ignoreDefaultArgs: ['--disable-extensions']のオプションを追加するようにしましょう。
自分が利用してるオプションは以下の通り。こちらにリストアップされてるので、参考にしましょう。
- guest - アカウント無しの状態で起動させます
- disable-extensions - 拡張機能をオフの状態で起動させます
- start-fullscreen - フルスクリーンで起動。但し、viewportを指定すると無効化されます。
- incognito - 新しいコンテキストを生成して起動させる
- proxy-server='direct:// - プロキシーサーバを指定する。例は無しでダイレクト接続の場合。
- proxy-bypass-list=* - プロキシーサーバ経由の場合、バイパスするアドレスの指定
- disable-infobars - Chromeの通知バーを消します。
Chromeの場所が特定できないケース
PuppeteerはChromeが必要です。特に今回はpuppeteer-coreなので、Chromeの別途インストールは必須ですが、入っていないケースも多いでしょう。また、管理者権限でインストールした先と、ユーザ権限でインストールした先が異なる為、入ってるのに使えないというケースもありえます。
そこで、これら3つのケースに対応したコードを冒頭で追加しておき、PuppetterのexecutablePathで確定した場所を指定するようにしてあげれば、対応が可能です。
//使用するモジュール
var shell = require('child_process').exec;
var fs = require('fs');
const path = require("path");
//Chromeのパスを取得(ユーザ権限インストール時)
const userHome = process.env[process.platform == "win32" ? "USERPROFILE" : "HOME"];
var kiteipath = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe";
var temppath = path.join(userHome, "AppData\\Local\\Google\\Chrome\\Application\\chrome.exe");
//chrome場所判定
if(fs.existsSync(kiteipath)){
var chromepath = kiteipath
console.log("プログラムフォルダにChromeみつかったよ");
}else{
if(fs.existsSync(temppath)){
var chromepath = temppath;
console.log("ユーザディレクトリにChrome見つかったよ");
}else{
console.log("chromeのインストールが必要です。");
//IEを起動してChromeのインストールを促す
shell('start "" "iexplore" "https://www.google.co.jp/chrome/"')
return;
}
}
- kiteipathに本来管理者権限で入る先を指定する
- temppathにユーザ権限で入る先を指定する
- fs.existsSyncでファイルの有無を調べられます。あればtrue, なければfalseが返ってきます。
- いずれの場所にも入っていない場合にはインストール必要と判定し、child_processでInternet Explorerを起動し、Chromeのダウンロードページを開くようにする
- chromepathをexecutablePathに指定する
操作を記録しコード化する
Chrome拡張機能を使う方法
今回のコードは非常に単純な作業ですが、それでもこれだけのコードを記述する必要があります。しかし、このPuppeteerの凄い点は、Google公式がメンテナンスしてるという点です。さらに、Chrome用の拡張機能として、Puppeteer Recorderがこれもまた公式からリリースされています。
※2021年頃、次項のChromeのデベロッパーツールにレコーダーとして標準装備された為、廃止されました。
selenium ideのように、Chrome上で録画スタートし撮影終了をすると、自動で上記のようなコードが生成される仕組みになっています。あとは生成済みコードを手直しすれば、ウェブ操作の自動化があっという間に完了するというわけです。慣れは必要ですが、高価なアプリを購入してRPAをやるより、まずこちらでチャレンジしてみる価値は十分にあると思います。
使い方はひどく簡単で
- 拡張機能をインストールする
- 右上の拡張機能からPuppeteer Recorderをクリックする
- Recordボタンをクリック
- Chromeで色々操作する
- Stopボタンを押すとPuppeteer用のNode.jsコードを生成してくれる
- コードを手直しして、Node.jsで実行するだけ
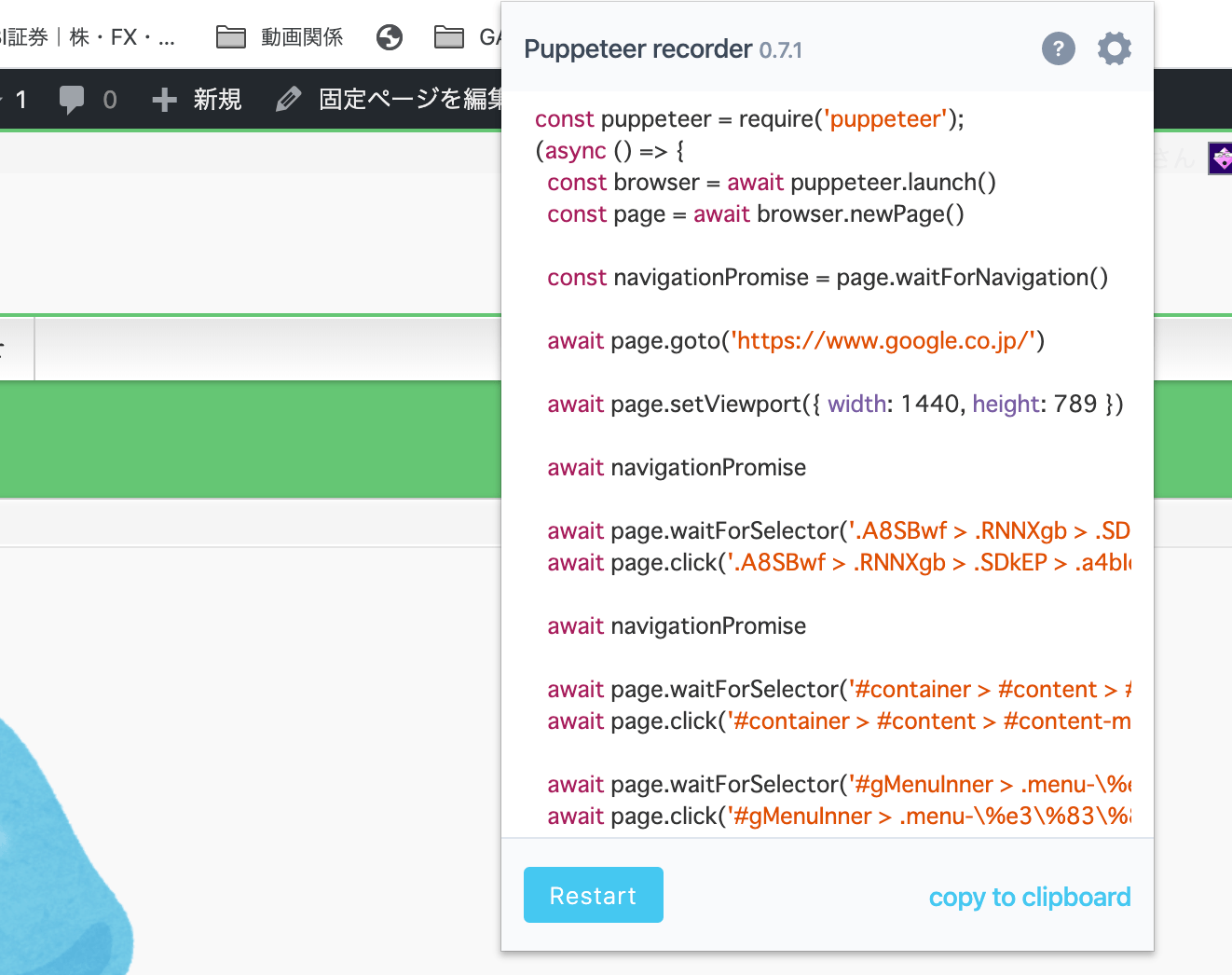
図:コードの手直しは必要だけれど、最低限の手直しで色々実現可能
Devtoolsの機能を使う方法
Chrome97以降から、Devtools自体にRecorder機能が搭載されました。以下の手順で操作を記録して、JavaScriptのコードで吐き出す事が可能です。ただ個人的には使い勝手は拡張機能のほうが楽だなぁと思います。
- F12キーを押してDevtoolsを表示する
- 右上の「︙」をクリック、More Tools⇒Recorderを選択
- Start New Recordingをクリック
- 適当に名前を付けて、下の方にある赤丸のボタンをクリックすると操作を記録開始
- もう一度赤丸のボタンをクリックすると操作記録終了
- ReplayとかPerformance測定などの機能も備わっています。
- Devtoolsのゴミ箱アイコンの隣にExportボタンがあるのでクリックする
- Export as a Puppeteer Scriptを選んでクリック
- 保存するとJSファイルで保存される

図:標準でレコーディング機能が装備された
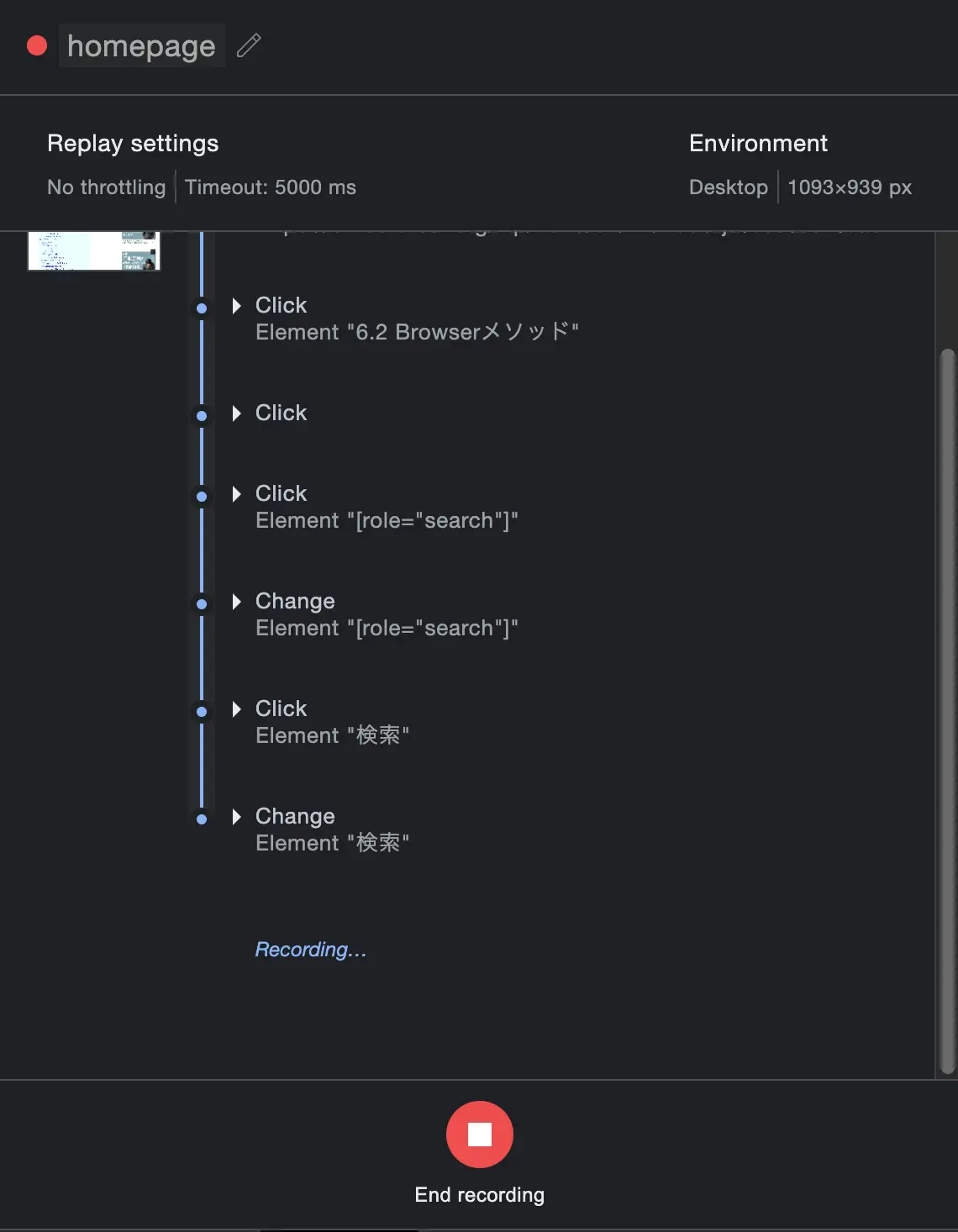
図:レコーディング中の様子
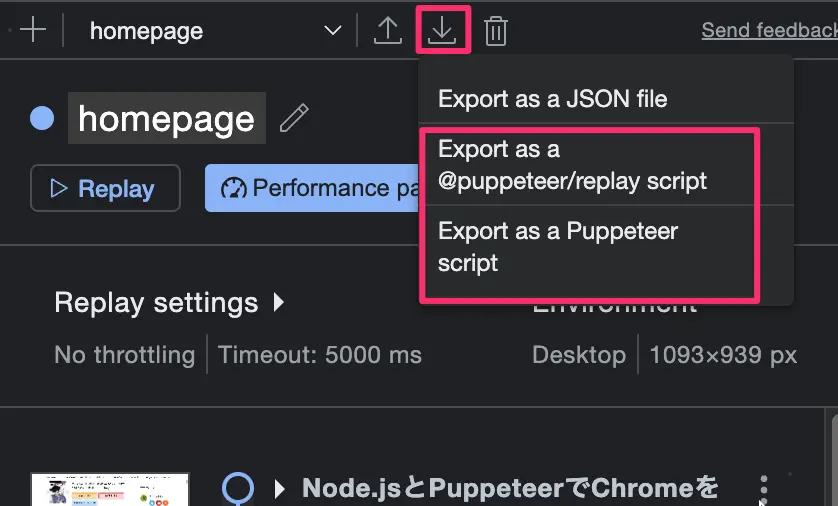
図:エクスポートする様子
pkgを利用してNode.jsを単一実行ファイル化
Node.jsがなければ、Puppeteerは動作させる事が出来ません。しかし、例えば社内で配布するとなると、Node.jsをインストールして実行用のスクリプトを配置してといった事は難しいです。
そこで利用したいのが、Node.jsおよびnode-module、index.jsを始めとするモジュール類を全部パッケージにして、実行ファイル化してくれるのがpkg。作成対象は、Windows, Linux, macOSの3環境用にジェネレートしてくれるので、コードの中でうまく動作環境に合わせた条件分岐を入れておけば、Puppeteerを動かす材料としては優れています。
インストール
インストールは簡単。グローバルモジュールとしてインストールします。
npm i -g pkg
パッケージ作成
パッケージを作成するには、以下の手順で作成が可能です。Chromiumは含めていないので、別途事前にChromeがインストールされている必要があります。コードは上記の検索結果をpng化する操作になります。
- ターミナルを起動する
- プロジェクトのフォルダ内へ移動する
- index.jsがあると思うので、ターミナルで以下のコマンドを実行する
pkg index.js -t win --public
- そのままですと、プロジェクトフォルダ内に、3環境用に実行ファイルが生成されます。
- 特定のOS用にするならば、オプション引数をつければ良い(Windows用ならば--target=node10-win-x64をつける)
- コードの中でディレクトリの位置であったり、PuppetterならばChromeのファイルのパスなどは、OS毎に違うので要注意。
- ファイルサイズは今回のケースならば45MBほど。Electronで構築するよりかはずっとコンパクトです。
- EXE化できるという事は、例えばVBAから仕込んだPuppeteerを実行するであったり、Electronから呼び出すといった用途を実現する事が可能になります。
- macOS環境でwindows用のexeを作ったら動かず・・・なので、Windows環境でpkgを実行したら無事に動きました。
- pkgで作成できるバイナリは64bit環境でしか動作しません。
図:pkgにて実行ファイルを生成してみた
引数と返り値
作成したいEXEに引数を渡し、返り値を取りたい場合、index.js側にその仕組を用意して上げる必要があります。
呼び出し先のEXE側
node.jsで引数を渡して、index.jsを実行する場合以下のようなコマンドを実行します。
node index.js xxxx yyyy zzzz
この時、xxxx yyyy zzzzといったスペース区切りの引数を取るには以下のコードで取得できます。
//引数を取得する var procman = process.argv; //引数を分解する var uid = String(procman[2]); var pw = String(procman[3]); var startday = procman[4];
Node.jsの場合、引数部分は配列の2から始まるので、0はnode.exe, 1はindex.jsが取れてしまいます。process.argvで引数が配列で取得されるので、それぞれを変数に格納して利用することになります。これはpkgでパッケージにしても同じなので、pkgにしたことを想定してコードを書く必要はありません。
呼び出し元
pkgで作成したindex.exeから逆に出力結果を返り値として受け取りたい場合は、EXE側はconsole.logで出力すれば良いだけ(逆にconsole.logで出してしまうと渡ってしまうので、EXE側のindex.jsでは出力以外でconsole.logを使わないようにしましょう)。
一方呼び出し元で受け取る為には、以下のような形で関数を用意します。Syncにしないと非同期で処理が進んでしまって、EXEの終了を待たずに終わってしまうので要注意です。
//vbs実行用(同期的にexe実行を行う)
var spawnSync = require('child_process').spawnSync;
//外部コマンドを実行する
function puppetcommand(args) {
//コマンドを組み立てて実行
var child = spawnSync(__dirname + '\\exe\\puppetman.exe', args);
var retman = child.output[1];
//改行コードを削除する
retman = retman.replace(/\r?\n/g, '');
//retを返す
return retman;
}
- spawnSyncで同期的に実行し、返り値をchildに格納しています。実行するEXEと引数をココで渡します。
- EXEの実行完了し、console.logで出力された内容を取得したら、その中にあるoutputの配列の1つ目がソレになるので、child.output[1]で取得します。
- 最後にreturnでこの関数を呼出した元の処理に結果を返します。
- 何故か、outputには改行コードが含まれてしまってるので、replaceにて削除しておく
返り値の中身
{
status: 0,
signal: null,
output: [
null,
<Buffer 43 3a 5c 55 73 ... 9 more bytes>,
<Buffer >
],
pid: 16352,
stdout: <Buffer 43 3a 5c ... 9 more bytes>,
stderr: <Buffer >
}
主に使うメソッド
公式リファレンスを見てみると膨大な量の様々な操作メソッドが列挙されています。また、Node.jsですのでその他のNode.jsモジュールを組み合わせてみたり、コードを追記すればより高度なChrome自動化が実現できるでしょう。ここでは、その中で非常によく使うであろうメソッドを列挙してみたいと思います。
launch
PuppeteerからChromeを起動します。この時、引数optionに色々と指定する事でヘッドレスChromeの挙動をコントロールする事が可能です。主なオプションは以下の通りです。全ての基本になるものです。
- headless - trueならばヘッドレスモードとなり、Chromeを見せずにバックグラウンドで起動します。
- executablePath - Chromeの実行ファイルのパスを直接指定する。Chromiumを同梱していない場合には必須です。Windows10 64bitなら「'C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe'」等を指定する(管理者権限インストールの場合)。
- slowMo - Puppeteerの動作に掛かる時間を指定します。1個の動作に掛かるスピードが高速すぎる場合には指定すると上手くいくかも。ミリセカンド単位で指定する。
- args - 配列で指定する細かなオプション。フルスクリーンにしたり、画面のサイズを指定したり、シークレットモードで起動したりといったものを担当。
//Puppeteerをオプション付きで起動する const browser = await puppeteer.launch(options);
Browserメソッド
launchで起動したPuppeteerは、Browser変数に入れてから色々と指示を出してあげます。
newPage
新しいタブを追加して、その中でChromeのインスタンスを実行します。。
close
起動したChromeを閉じます。操作が完了したら速やかに起動したChromeを終了させるべきです。でないと、何かエラーがあった場合、これらのインスタンスがゾンビ化して残るとも限りません。
//新しいタブでChromeに追加する const page = await browser.newPage(); //Puppeteerで起動したChromeを終了させる browser.close();
pageメソッド
Browserを起動したらpageに格納し、いよいよ細かなメソッドをここに順番に割り当てて、操作をしていきます。
goto(url, option)
指定したURLを開きます。この時OptionでwaitUntilを指定すると、例えばドキュメントの読み込みが完了するまでWaitといった指定をする事が可能です。指定しなかった場合、待たずに次の処理に進んでしまいます。
//googleを開き読み込み完了まで待機
page.goto("https://www.google.com/", {waitUntil: "domcontentloaded"});
トラブルシューティング
Chromeが起動しても操縦できない
非常に便利なPuppeteerですが、開発当初動いていたのに、Chromeがバージョンアップを重ねた結果、PuppeteerでChromeが起動出来ても、そこから動かなくなる現象があります。例えば、Chromeのバージョンが90.0.4430.212の場合、2022年9月最新版のPuppeteer 17.0で動かそうとすると動作しません。この場合、Puppeteerは10.1.0では動作します。
最新のPuppeteerが後方互換性を確保してるとは限らないので、この場合あえて古いバージョンのPuppeteerを使う必要性があります。
反対にChromeは常に最新である場合、Puppeteerが古いままで動作しないというケースもありえます。この場合、Puppeteerは最新版を入れるようにして、再度ビルドしなければなりません。
開発の基本は常にChromeもPuppeteerも最新版を利用するようにすれば問題が生じませんが、動かない場合にはこの辺りを気をつけてバージョン指定してみると良いでしょう。ちなみに、過去版Puppeteerを入れたい場合は以下のコマンドを実行する。
npm i puppeteer-core@10.1.0
expressと同時に使えない
最近発生するようになったのか?それとも、気がついていなかったのか?expressとPuppeteerを同時に使うと、Puppeteerがクラッシュするという現象を確認しました。Issueには見当たらないのですが、app.js側でexpressを立ち上げてlocalhost:4100でMicrosoft Azureの認証用の処理を作っているのですが、それとは全く別にサイトのスクレイピングをするコードをindex.js側で作成しています。
index.js側ではmodule.exportしたapp.jsをrequireで読み込み、express.listenしてるのですが、このコードが存在すると、Puppeteerがクラッシュします。このコードを除去すると障害は発生しませんが、認証用ページも表示されないので、困ったことになります。
この問題の解決法ですが、PuppeteerではなくPuppeteer-coreを利用すること。puppeteer-coreの場合は特に問題もなく共存している為、puppeteer自身の抱えている問題ではないかと思います。Microsoftが開発してる同様の技術である「Playwright」はまだ検証していません。
TimeoutError対策
2つのパターンがありますが、いずれもタイムアウトの数字を大きくする事で回避が可能です
起動が遅すぎてタイムアウト
Chromeの起動が遅すぎて、デフォルトの30秒を超えてしまった場合に、エラーが吐かれて操作できなくなるケースです。この場合、以下のようにtimeoutオプションを加えて、msで指定すると指定した時間がタイムアウトになるので、付けるようにしましょう。timeoutオプションに数字を指定します。
const browser = await puppeteer.launch({
headless: false,
executablePath: chromepath,
timeout: 300000,
ignoreDefaultArgs: ["--guest",'--disable-extensions','--start-fullscreen','--incognito',],
slowMo:100,
});
上記の例だと、300秒までタイムアウト時間を拡大しています。
ページ読み込みが遅すぎてタイムアウト
こちらは通信の問題で、特定のページを開き、表示されるまでの時間が長すぎてタイムアウトする事例。以下の事例では特定要素が現れるまで待機のコードですが、デフォルトだと30秒でタイムアウトになり、コードが止まってしまうのを90秒まで拡大させています。
await page.waitForSelector('#status',{timeout:90000});
こちらのサイトにタイムアウト関係の回避方法がまとめられているので、Puppeteerを常用する人必見です。
デフォルトタイムアウトの設定
Puppeteerの既定のタイムアウト設定は30秒です。よって、基本的に上記のように個別のメソッドでタイムアウトを設定してる場合を除いて、30000msを経過すると、タイムアウトエラーになってストップします。しかし、個別に設定するのは面倒。
という場合に使うのが、page.setDefaultNavigationTimeoutや、page.setDefaultTimeout。引数に90000と指定すれば90秒がデフォルトタイムアウトになります。自分の場合は前者をよく使っています。手っ取り早く既定値変えてしまったほうが楽かもしれませんね。
page.setDefaultNavigationTimeout(90000);
EPERMエラーについて
まれに、Puppeteerを動かそうとした時に遭遇するバグの1つに、EPERMエラーがあります。ターミナルに以下のようなエラーが出て止まってしまいます。ブラウザを終了して閉じる際に発生するトラブルです。
[Error: EPERM: operation not permitted, unlink 'C:\Users\googl\AppData\Local\Temp\puppeteer_dev_chrome_profile-32N54n\CrashpadMetrics-active.pma'] {
errno: -4048,
code: 'EPERM',
syscall: 'unlink',
path: 'C:\\Users\\googl\\AppData\\Local\\Temp\\puppeteer_dev_chrome_profile-32N54n\\CrashpadMetrics-active.pma'
}
通常はpageを閉じずにBrowserを閉じても問題ないのですが、この場合の回避策としては、browser.closeをする前にpageをすべて閉じるようにしたり、強制終了するようなコードを書く回避策が提示されています。ただ使ってみたのですが、オカシナトラブルが出るので、自分は使っていません。
//すべてのpageを閉じてからcloseする
let pages = await browser.pages();
await Promise.all(pages.map(page =>page.close()));
await browser.close();
//強制終了させる方法
await browser.close();
browser.process().kill('SIGKILL');
自分が行ったこの厄介なエラーに対する対処は以下の通りです。
- ターミナルよりnpm cache verify --forceコマンド(npm4までは、npm cache clear --forceでした)で、npmのキャッシュをクリアする(特にnpm install時にエラーが出た時のキャッシュが悪さをしてるケースでは有効)
- puppeteer-coreなどを一旦npm remove puppeteer-coreでアンインストールし、再度最新版のpuppeteer-coreをインストールする
- stackoverflowでは、Windowsセキュリティの除外リストに、nodeやエラーの出ている一時フォルダを登録する方法も提示されていますが、配布するアプリである場合、都度そのマシンの除外リストに追加が必要となるため、あまり有効とは言えない。
上記のうち、キャッシュのクリアと最新版のpuppeteer-coreインストールで今の所問題なく動いています。ChromeとPuppeteerは密接な関係にあるため、都度、最新のpuppeteer-coreに入れ替えてビルドするメンテが必要になるのかなと思います(Seleniumだとバージョンまで合わせないといけないため、よりセンシティブ)
タブを全部閉じることでクローズする方法が一番手っ取り早いかもしれません。以下のコードで取り敢えずオカシナ現象は表示されていません。
let pages = await browser.pages(); await Promise.all(pages.map(page =>page.close()));
STATUS_STACK_BUFFER_OVERRUN
Puppeteer自体はきちんとChromeを操作できているのに、最後の最後、ボタンクリックでファイルをダウンロードと言うシーンに於いて、「STATUS_STACK_BUFFER_OVERRUN」というエラーが出てダウンロードできず。というケースがありました。Node.js上では正しく動くのに、Electron上で動かすとこれが発生し、どうにも対処が。このエラーコード自体で検索してみてもPuppeteerで有効な手段ではありませんでした。
コードの違いはElectronでは最後にbrowser.process().kill('SIGKILL');を入れているのですが、Node.jsでは入れていない点。ということで、この部分のコードを以下のように書き直しました。
const allpages = await browser.pages(); for(const page of allpages) await page.close();
ブラウザのページを全て閉じてもbrowser.close();と同じくChromeを終了出来るので、これでしばらく様子見しています。
※最終的に駄目だった場合、前述にあるように、動作するパターンをNode.js + pkgでEXE化し、それをspawnSyncで呼び出す方式を取ればうまく稼働すると思います。

図:非常に難解なエラー
Page Crashエラー
自分自身まだ解決できていない問題の1つにPage Crash。つい最近起きた問題で、Dockerで使ってる場合のエラーとしてはすでに報告が出ているものの、自分はDockerを使っていない為この事象は関係ない。
しかもこのエラーは、途中まではきちんと動作し、ファイルのダウンロードの部分でエラーとなる。それまでは動作していたコードにも関わらず。また、何故かEdgeを指定した場合、管理者権限を要求される謎の現象も付いています。
直近で行った変更は、puppeteer-coreを最新14.0に変更した点。また、土台にNode.jsをLTSの16.0に変更した点。Chrome自体は特に変更しておらず、現在はpuppeter-coreを10.1.0に戻した場合は以下のコードでも動作します。
問題のあったコード
//puppeteerでTSログを取りに行く
async function puppetrun(repurl,filenames,startday,endday,tspasswd,callback){
const browser = await puppeteer.launch({
headless: false,
executablePath: chromepath,
ignoreDefaultArgs: ["--guest",'--disable-extensions','--start-fullscreen','--incognito',],
slowMo:100,
});
//パス指定
var dpath = dir_desktop+"\\tsdownload"
var loginuid = store.get("loginuid");
//ブラウザのダウンロード先をすべて統一する
await browser.on('targetcreated', async () =>{
const pageList = await browser.pages();
pageList.forEach((page) => {
page._client.send('Page.setDownloadBehavior', {
behavior: 'allow',
downloadPath: dpath,
});
});
});
・・・・中略・・・・
try{
//ダウンロードが完了するまでウェイト
var filename;
var lastname= await ((async () => {
while ( ! filename || filename.endsWith('.crdownload')) {
//一時フォルダの1個目のファイルを取得
filename = fs.readdirSync(dpath)[0];
if(filename == undefined){
//何もしない
await sleep(5000);
}else{
//ファイルの拡張子がcrdownloadの場合スルーする
var ext = await filename.slice(-10);
if(ext == "crdownload"){
//何もしない
await sleep(5000);
}else{
//ファイルのフルパスを構築する
let fullname = dpath + "\\" + filename;
//ファイルのリネームと移動
await fs.renameSync(fullname, dpath + "\\" + filenames, (err) => {
if (err) throw err;
console.log('ファイルを移動しました');
filename = dpath + "\\" + filenames;
return filename;
});
await sleep(2000);
}
}
}
})());
}catch(e){
//エラー発生
filename = "NG"
return;
}
try{
//ブラウザを閉じる
await browser.close()
browser.process().kill('SIGKILL');
//処理を戻す
await callback(filename);
}catch(e){
//filenameに"NG"を追加
filename = "NG"
return;
}
});
修正したコード
async function puppetrun(repurl,filenames,startday,endday,tspasswd,callback){
//puppeteerを起動
const browser = await puppeteer.launch({
headless: false,
executablePath: chromepath,
ignoreDefaultArgs: ["--guest",'--disable-extensions','--start-fullscreen','--incognito',],
slowMo:100,
});
//pageを定義
const page = await browser.newPage()
const navigationPromise = page.waitForNavigation();
//ブラウザのダウンロード先をすべて統一する
const cdpsession = await page.target().createCDPSession();
cdpsession.send ("Browser.setDownloadBehavior", {behavior:"allow", downloadPath: dir_desktop });
//エラー発生時
page.on('error', err=> {
console.log(err);
});
・・・・中略・・・・
try{
//ダウンロードが完了するまでウェイト
var filename;
while ( ! filename || filename.endsWith('.crdownload')) {
//一時フォルダの1個目のファイルを取得
filename = fs.readdirSync(dir_desktop)[0];
if(filename == undefined){
//何もしない
await sleep(5000);
}else{
//ファイルの拡張子がcrdownloadの場合スルーする
var ext = await filename.slice(-10);
if(ext == "crdownload"){
//何もしない
await sleep(5000);
}else{
//フルパスを構築
var fullpath = dir_desktop + "\\" + filename;
//一時ウェイト
await sleep(3000);
//ダウンロードパスを返す
await callback(fullpath);
//ブラウザを閉じる
await browser.close()
browser.process().kill('SIGKILL');
return;
}
}
}
}catch(e){
console.log(e)
//filenameに"NG"を追加
filename = "NG"
return;
}
}
//スリープ用関数
function sleep(milliSeconds) {
return new Promise((resolve, reject) => {
setTimeout(resolve, milliSeconds);
});
}
変更点は以下の通り
- Downloadするパスの変更をPage.setDownloadBehaviourではなく、cdpsession.sendの方法に変更
- ダウンロード後にファイル名を書き換えず、そのまま呼び出し元にcallbackして返すように変更
- またダウンロード完了待のコードを簡略化
- ダウンロード完了後にcallbackした後に続けて、brwoser.close()するように変更。
- また、エラーに「CDPSession.Page.client.on.event」と出ている場合には、ignoreDefaultArgsに「'--no-sandbox'」を追加すると回避される場合があります。
可能であれば、page.onのerror時イベントにエラーを補足して、ログを送信する機能があると、実機でなくともエラーを取得できるので、開発側は楽になれます。
図:クラッシュエラー
Failed to launch the browser process puppeteer
前述のコードでChrome.exeの場所を正しくPuppeteer-coreにexectablePathで伝えているにも関わらず発生したエラー。こちらのエントリーにも同様の事例が質問されているのですが、puppeteer-coreなので、参考にならず。
結果的には前述のコードに戻し、またpuppeteer-coreも古いバージョンに戻したところ発生しなくなったので、モジュール特有のバグ?か何かだと思うものの、すっきりしない。可能性として考えられるものは、「ignoreDefaultArgs」に余計なオプションを指定していた可能性。とにかく起動に失敗したという内容なので、いずれ再度バージョンを上げて調査したい。
現時点でChromeのパスを特定してpuppeteerに渡すコートできちんと動作しているのは以下のコード。
//Chromeのパスを取得(ユーザ権限インストール時)
const userHome = process.env[process.platform == "win32" ? "USERPROFILE" : "HOME"];
var kiteipath = "C:\\Users\\googl\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe";
var kiteipath2 = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe";
var temppath = "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe";
var edgepath = "C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe";
//chrome場所判定
var chromepath = "";
if(fs.existsSync(kiteipath)){
chromepath = kiteipath
console.log("ユーザフォルダにChromeみつかったよ");
}else{
if(fs.existsSync(kiteipath2)){
chromepath = kiteipath2;
console.log("プログラムフォルダに x86 Chrome見つかったよ");
}else{
if(fs.existsSync(temppath)){
chromepath = temppath;
console.log("プログラムフォルダに x64 Chrome見つかったよ");
}else{
if(fs.existsSync(edgepath)){
chromepath = edgepath;
console.log("ユーザディレクトリにChromium Edgeが見つかったよ");
}else{
console.log("chromeのインストールが必要です。");
//IEを起動してChromeのインストールを促す
shell('start "" "iexplore" "https://www.google.co.jp/chrome/"')
}
}
}
}
ユーザの環境によっていくつかのインストール先が存在するので、このような対応をしています。ここで得たchromepathをPuppeteerのexectablePathに渡して利用します。
Edge操作時にレジストリコンソールツール表示
特に企業ユースで使う場合、且つ制限が掛けられている場合に表示されるもので、エラーというよりもPuppeteerから操作する場合にレジストリの一部を操作するようなコード(ダウンロード先変更等)が入っている場合に表示される画面。管理者権限がなければ動かせなくなるため、このようなエラー画面が表示される。
このエラー自体の回避方法は、Page.setDownloadBehaviour等を利用せずに、CDPSessionを使った以下の手法に書き換えたりしましょう。
//ブラウザのダウンロード先をすべて統一する
const cdpsession = await page.target().createCDPSession();
cdpsession.send ("Browser.setDownloadBehavior", {behavior:"allow", downloadPath: dir_desktop });
図:Edgeの場合だけ出てくる
単一実行ファイルを作成する
Node.js 18よりSingle executable applicationsという機能が装備され、標準で単独実行ファイルが作成できるようになりました。結果pkgはプロジェクト終了となっています。よって、以下のエントリーの単一実行ファイルを作成するを参考に、Node18以降はexeファイルを作成することが可能です。
関連リンク
- Puppeteer API Tip-Of-Tree
- PuppeteerでヘッドレスChromeを操ってみる
- puppeteer-coreとMacにインストール済みのChromeを使って自動操作
- ヘッドレス Chrome Node API 「Puppeteer」
- 画面操作を自動化するツール Puppeteer (パペティア)職場環境では動かない…(解決)
- Error: EPERM: operation not permitted #6563
- puppeteerで普段使っているChromeを自動操縦する。
- How to read child_process.spawnSync stdout with stdio option 'inherit'
- What is "Page crashed!" error?
- puppeteerで--no-sandboxを付ける理由は何なのか
- setDownloadBehavior issue
- TimeoutError: Timed out after 30000 ms while trying to connect to Chrome! The only Chrome revision guaranteed to work is r662092
- デベロッパー ツールの使用を許可する状況を管理する
- WebDriver を使用して Microsoft Edge を自動化する
- Universal path to chrome.exe
- Puppeteer: 例を実行しようとしたEPERMエラー
- Puppeteerの使い方(スクレイピング, フロントテストで活用)
- puppeteerでクリックしてCSVをダウンロードする
- nexeでNode.jsのアプリをパッケージングしてみた
- node.js pkgで1ファイル実行ファイル化
- Chrome拡張「Puppeteer Recorder」を使って簡単にブラウザの自動操作を行う
- Python & Selenium のプログラムを実行形式(.exe)化する(webdriverも.exeに含める方法)
- 「Puppeteer Recorder」を試してみた
- Puppeteerでできることまとめ
- 【puppeteer】基本情報&逆引き
- Cloud Functions with Puppeteer + Google Apps Script でスクレイピングサーバーをサクッと作る
- cloud functions × puppeteer × Google Apps Scriptで超低コスト定期実行クローラを作って金曜ロードショーを毎週slackに通知させる
- microsoft/playwright - github
- Question: How do I get puppeteer to download a file?
- prompts : node.js用のコマンドラインからの値を受け取る時に便利なライブラリ
- Puppeteerでファイルダウンロード
- puppeteerでよく使うであろう処理の書き方
- Chrome操作ライブラリ chromy と puppeteer を比較
- Playwrightも知らないで開発してる君たちへ
- puppeteerでステータスコード系エラーとconsoleのエラーを拾う
- Puppeteer: 最後のページを閉じたときにブラウザを閉じると、エラーがスローされることがあります