Puppeteerでテーブルデータを取得する
PuppeteerでChrome自動操縦によるRPAアプリケーションを現在、現場にテスト導入中。これまでの課題は4つのウェブサービスにログインして、パラメータを指定し、請求書データをダウンロードするものでした。今の所バッチリ動いています。(大塚、日経、勤怠、ゼロックスはクリア)
さて、5つ目の課題がハードルが高い。ヤマトビジネスメンバーズの請求書ダウンロードです。このサイトは検索が出来ません。しかし、過去の請求書が数ヶ月分ほど列挙されています。それらを選択させて上げる必要があるのですが、ラジオボタンにはIDが振られており、テーブルデータをスクレイピングして、対象の年月を特定して、ラジオボタンのIDを特定してあげる必要があります。
今回はこのテーブルデータをスクレイピングして、自分が欲しい年月の請求書データをダウンロードに挑戦してみたいと思います。
リンク
目次
今回使用するライブラリ等
今回はスクレイピングさせる為の補助として、cheerioと呼ばれるNode.js上でjQueryのようにDOM操作をする事のできるモジュールを入れています。
今回のダウンロード上の問題点
今回対象としてるウェブサービスでは、以下のような問題点があるため、そのままクリックでダウンロードですと、最新のファイルがダウンロードされてしまいます。
- 年度月でフィルタして特定する事が出来ない。
- 今回のコードではお客様コードの切り替えは考慮していないので、複数コードを持つ場合には、お客様コードの選択のコードの追加が必要です。
- 請求書ページまでは、セッションが必要になってるので、いきなりそのページには飛べないので、クリックさせて遷移が必要。
- 一番の肝は対象の年月のデータをラジオボタンで特定出来ない事。Tableをスクレイピング&解析して、請求年月日から推察、対象のラジオボタンをチェックしてあげる必要があります。これが一番のハードル
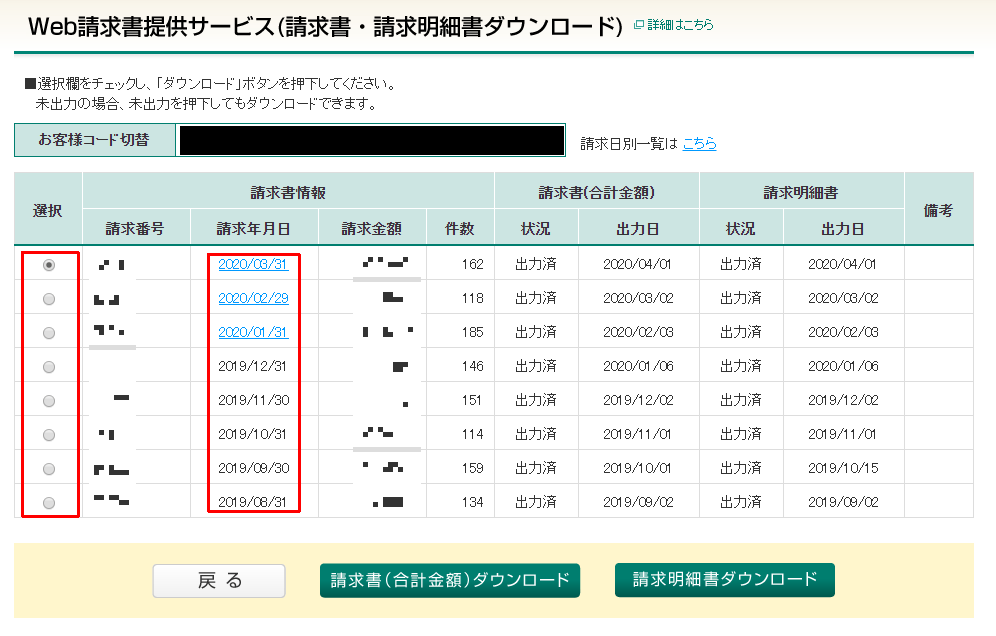
図:日付を比較し、対象のラジオボタンをクリックさせる
ソースコード
冒頭部分
//使用するモジュール
const puppeteer = require('puppeteer-core');
const prompts = require("prompts");
var fs = require('fs');
const path = require("path");
var shell = require('child_process').exec;
var spawnSync = require('child_process').spawnSync;
const makeDir = require("make-dir");
var os = require('os');
var cheerio = require('cheerio');
//デスクトップのパスを取得
var dir_home = process.env[process.platform == "win32" ? "USERPROFILE" : "HOME"];
var deskpath = require("path").join(dir_home, "Desktop");
var dir_desktop = deskpath + "\\tmpman\\";
var userInfo = os.userInfo();
var username = userInfo.username;
var subfolder = 'c:\\Users\\' + username + '\\Box\\請求書ダウンロード\\';
var nendoman = "";
//ダウンロードする日付を組み立てる
var choiceday;
//オープンするURL
var url = "https://bmypage.kuronekoyamato.co.jp/bmypage/servlet/jp.co.kuronekoyamato.wur.hmp.servlet.user.HMPLGI0010JspServlet";
//Chromeのパスを取得(ユーザ権限インストール時)
const userHome = process.env[process.platform == "win32" ? "USERPROFILE" : "HOME"];
var kiteipath = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe";
var temppath = path.join(userHome, "AppData\\Local\\Google\\Chrome\\Application\\chrome.exe");
//chrome場所判定
if(fs.existsSync(kiteipath)){
var chromepath = kiteipath
console.log("プログラムフォルダにChromeみつかったよ");
}else{
if(fs.existsSync(temppath)){
var chromepath = temppath;
console.log("ユーザディレクトリにChrome見つかったよ");
}else{
console.log("chromeのインストールが必要です。");
//IEを起動してChromeのインストールを促す
shell('start "" "iexplore" "https://www.google.co.jp/chrome/"')
return;
}
}
//プロンプト表示
getprompt();
- 今回はログイン画面から順番にたどっていく必要があるので、請求書ページにダイレクトに飛びません。
- Box Driveに直接保存する為、subfolderはユーザIDと組み合わせてパスを生成しています。
- グローバル変数でデスクトップのパスを取得しておきます。
- つづけて、getprompt()を実行してユーザの入力を受付待ちします。
- chromeはいつもの「C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe」ではなく、「C:\\Users\\ユーザー名\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe」となるため、ユーザ毎のパスを取得して、chromepathに格納する
プロンプト入力受付部分
//プロンプトを表示
async function getprompt(){
// 入力を待ち受ける内容
let question = [
{
type: "text",
name: "id",
message: "ログインIDを入力してください(例:090xxxxxxxx)"
},
{
type: 'password',
name: "pass",
message: "パスワードを入力してください"
},
{
type: "number",
name: "nendo",
message: "年度を指定してください(例:2020)"
},
{
type: 'text',
name: "month",
message: "月を指定してください(例:02)"
}
];
// promptsの起動
let response = await prompts(question);
//回答を取得
var userid = String(response.id);
var pw = String(response.pass);
var nendo = String(response.nendo);
var month = String(response.month);
//ダウンロード日付を構築する
choiceday= String(nendo) + String(month);
//サブフォルダ名を定義(年月で命名))
nendoman = subfolder + choiceday;
//一時フォルダを作成する
await makeDir(dir_desktop).then(path => {
makeDir(nendoman).then(path => {
//main関数に引き渡す
main(userid,pw,nendo,month);
});
});
}
- promptsを使って、4つの質問を受け付けるようにします。
- useridとpassword、指定の年度月の4つを質問し、それぞれの形式で受け付けます。passwordを指定しておくと****と隠した状態で表示されるようになります。
- 取得した数値を引数にmain()を実行します。
- この段階で完成品フォルダをmakeDirにて作成してしまいます。
- promptsのtypeがnumberは数値入力なのですが、バグで5桁以上入れようとすると(特に0の連続)入力がクリアされてしまうので、今回はtextにしています。
Puppeteer部分
//ブラウザ操作メイン関数
async function main(userid,pw) {
const browser = await puppeteer.launch({
headless: false,
executablePath: chromepath,
ignoreDefaultArgs: ["--guest",'--disable-extensions','--start-fullscreen','--incognito',],
slowMo:100,
});
//ブラウザのダウンロード先をすべて統一する
await browser.on('targetcreated', async () =>{
const pageList = await browser.pages();
pageList.forEach((page) => {
page._client.send('Page.setDownloadBehavior', {
behavior: 'allow',
downloadPath: dir_desktop,
});
});
});
//pageを定義
const page = await browser.newPage()
const navigationPromise = page.waitForNavigation()
//ログインページを開く
await page.goto(url)
await page.setViewport({ width: 1300, height: 900 })
await navigationPromise
//IDとパスワードを入力してログイン
await page.waitForSelector('form > .lyt-form-customer-code > dl > .nav-login-btn > a')
await page.type('.lyt-form-customer-code #code1', userid)
await page.type('form #password', pw)
await page.type('.lyt-form-customer-code #quickLoginCheck', '1')
await page.click('form > .lyt-form-customer-code > dl > .nav-login-btn > a')
await navigationPromise
//Web請求書ページへ移動する
await page.waitForSelector('.list-service-container > .list-service > li:nth-child(2) > a > span')
await page.click('.list-service-container > .list-service > li:nth-child(2) > a > span')
await navigationPromise
await page.waitForSelector('tbody > tr:nth-child(1) > .btn > a > .imgover')
await page.click('tbody > tr:nth-child(1) > .btn > a > .imgover')
await navigationPromise
//テーブルを二次元配列でスクレイピング
const result = await page.evaluate(() => {
const rows = document.querySelectorAll('#contents > table tr');
return Array.from(rows, row => {
const columns = row.querySelectorAll('td');
return Array.from(columns, column => column.innerHTML);
});
});
//配列データを解析する
var targetid = "";
for(let i in result) {
//空のデータはスルーする
if(result[i] == ""){
continue;
}
//inputのIDを取得する
var ele = result[i][0]
//cheerioに食わせる
var $ = await cheerio.load(ele);
//inputのIDを取得する
let eleid = $('input[type="radio"]').prop("id");
//日付データを取得する
var $ = await cheerio.load(result[i][2]);
let seikyuday = $('a').text();
//日付が空の場合は配列から直接取る
if(seikyuday == ""){
seikyuday = result[i][2];
}
//6桁の数値に変換する
seikyuday = seikyuday.substr( 0, 4 ) + seikyuday.substr( 5, 2 );
//入力年月と比較する
if(choiceday == seikyuday){
targetid = "#" + eleid;
break;
}
}
//指定のIDのラジオボタンをクリックする
await page.click(targetid)
//請求書ダウンロード
await page.waitForSelector('#content > #main > .submit > #BILL_DOWNLOAD > .imgover')
await page.click('#content > #main > .submit > #BILL_DOWNLOAD > .imgover')
//ダウンロードが完了するまでウェイト
var filename = await ((async () => {
var filename;
while ( ! filename || filename.endsWith('.crdownload')) {
filename = fs.readdirSync(dir_desktop)[0];
if(filename == undefined){
//何もしない
await sleep(2000);
}else{
//ファイルの拡張子がcrdownloadの場合スルーする
console.log(filename)
var ext = filename.slice( -10 );
if(ext == "crdownload"){
//何もしない
await sleep(2000);
}else{
//ファイルのフルパスを構築する
let fullname = dir_desktop + filename;
//ファイル名を新たに構築
var newname = choiceday + "ヤマト請求書.pdf";
//完成品フォルダに移動
fs.copyFile(fullname, subfolder + choiceday + "\\" + newname, (err) => {
if (err) throw err;
console.log('ファイルを移動しました');
//一時フォルダ内のファイルを削除
fs.unlinkSync(fullname);
});
await sleep(2000);
}
}
}
return filename
})());
//請求明細書ダウンロード
await page.waitForSelector('#content > #main > .submit > #DETAIL_DOWNLOAD > .imgover')
await page.click('#content > #main > .submit > #DETAIL_DOWNLOAD > .imgover')
//ダウンロードが完了するまでウェイト
var filename = await ((async () => {
var filename;
while ( ! filename || filename.endsWith('.crdownload')) {
filename = fs.readdirSync(dir_desktop)[0];
if(filename == undefined){
//何もしない
await sleep(2000);
}else{
//ファイルの拡張子がcrdownloadの場合スルーする
console.log(filename)
var ext = filename.slice( -10 );
if(ext == "crdownload"){
//何もしない
await sleep(2000);
}else{
//ファイルのフルパスを構築する
let fullname = dir_desktop + filename;
//ファイル名を新たに構築
var newname = choiceday + "ヤマト請求明細書.pdf";
//完成品フォルダに移動
fs.copyFile(fullname, subfolder + choiceday + "\\" + newname, (err) => {
if (err) throw err;
console.log('ファイルを移動しました');
//一時フォルダ内のファイルを削除
fs.unlinkSync(fullname);
//tmpmanフォルダを削除
fs.rmdirSync(dir_desktop);
//コマンドを組み立てて実行
var child = spawnSync('explorer.exe', [subfolder + choiceday] );
});
await sleep(2000);
}
}
}
return filename
})());
//終了メッセージを表示
const script = `window.alert('処理が完了しました')`;
await page.addScriptTag({ content: script });
//ブラウザを閉じる
await browser.close()
}
//スリープ用関数
function sleep(milliSeconds) {
return new Promise((resolve, reject) => {
setTimeout(resolve, milliSeconds);
});
}
- 前半部分は前回のエントリーとほぼ同じ。
- 今回の1番目の肝は、Table要素を取得して二次元配列データに変換する部分です。#contentsの部分がTableのIDなのでこれに対してTD要素内を二次元配列化してあげる。値はtextではなくinnerHTMLで取得する。
- ヤマトの場合、配列内に空っぽのものが含まれているので、これはスルーします。
- forループ内でcheerioに食わせてまず、radioボタンのIDをprop("id")にてIDを取得します
- 日付データですが、aタグのあるものとタダの値の2つが混在するので、条件判定しながら、202003といった年月数値を取り出し、入力したchoicedayと比較。
- 比較結果が一致したら取得済みのIDをtargetidに格納(頭に#を追加する)して次の処理。
- await page.clickにて、targetidをクリックさせる。
- 後は2つのボタンをクリックして、請求書と請求明細書をダウンロードさせる。
- 完了したら、newPageのタブを閉じ、alertを出してあげて終了。
- 最後に保存先フォルダをspawnsyncにてexplorerを使ってオープンしています。
単一実行ファイルを作成する
Node.js 18よりSingle executable applicationsという機能が装備され、標準で単独実行ファイルが作成できるようになりました。結果pkgはプロジェクト終了となっています。よって、以下のエントリーの単一実行ファイルを作成するを参考に、Node18以降はexeファイルを作成することが可能です。
関連リンク
- Want to scrape table using Puppeteer. How can I get all rows, iterate through rows, and then get “td's” for each row?
- [JavaScript]table-to-jsonを使ってテーブル内容をJSONにする
- How to output proper json from a pupeteer scraped table?
- Using Puppeteer to Transform HTML content into JSON
- Table to JSON - npm
- Puppeteerのクローリングで、Tableタグの表のデータをCSV出力する方法
- Node.jsのHTMLパーサ「cheerio」
- Node.jsのスクレイピングモジュール「cheerio-httpcli」が第3形態に進化したようです
- Using proxy #130

