海外進出の第一歩!YouTube動画の多言語字幕の簡単作成術
近年、Youtuberの間でYoutubeで数字が取れなくなった収益が減ったという話題を結構耳にします。しかし自分が見ている海外系CHでは日本の有名Youtuberよりも遥かに数字をコンスタントに取り続けてます。簡単な話、国内に対する内向きな動画ばかり作っていて、視聴者層の絶対的なパイが単純に日本でだけ減ってるに過ぎません。
しかし、日本国内の動画を海外に発信するには、戦略が必要になります。その第一歩が字幕ファイルの作成。そこで今回、過去ネタも踏まえて、動画の字幕の自動作成を実現し、労力を掛けずに多言語展開出来る体制を作ってみたいと思います。
目次
今回利用する素材
- Youtube字幕ジェネレーター - Google Spreadsheet
- Gemini API
- 生成された日本語のYTT形式の字幕ファイル
- 生成された英語翻訳のYTT形式の字幕ファイル
Youtubeの音楽系などは最近ちょくちょく見かける色のついたテロップのようなキレイな字幕。あれどうやって作ってるのか?ということで前回の記事でも音声から字幕生成の流れについては取り上げました。単純な字幕の場合、味気もないものになってしまうのですが、YTTという特殊な形式の字幕を作ることで、カラフルな字幕を低コスト・低時間で作ることが可能です。もちろん、外注コストを支払う必要はありません。
今回はさらに一歩推し進めて、これを自動化し尚且つ多言語対応できるようにすることで、自身の動画を海外向けにアピールするだ一歩とし、脱内向き動画を目指す足がかりにしてもらえたらと思います。
この為に高価なソフトや高度な技術習得は不要です。GeminiとGASを使えば無償で今すぐ取り掛かることが可能になっています。Google Apps ScriptとGemini APIのみを使って実現しています。
多言語字幕について
なぜ国内動画は数字を落としてるのか?
とりわけ日本国内で数字が落ちてるという話が聞こえてきている理由は、海外でも起きてる一般的な数字が落ちてる原因とは別の要因が既に起こり始めている為です。
世界的に起きてるCHの数字の下落原因は一般的には以下のような内容です。
- Youtubeの動画のTV化を嫌って、特に若い層がTiktokなどに流出している
- GoogleのYoutubeに対する行き過ぎた広告表示を嫌って、広告ブロッカーの利用が一般に普及するやぶ蛇を突いてしまった。いくら再生されても広告費は入ってきません。
- 新規参集者の激増により競争激化。可処分時間の奪い合いになっている
- 発信内容のニッチ化。メジャー処は先行者に押さえられてる為、ニッチを狙うしかなくなってきてる。
- 同時に、各チャンネルの専門化が進行。内容の薄いチープなCHは淘汰が始まってる。
- 同じ若い人でも世代が違えば嗜好は違う。しかし、演者が古い思考のままで世代交代で視聴者を失ってる。
一方、国内動画についてはこれに加えて以下の要因が大きく影響しています。
- 超少子高齢化の進行でそもそも視聴者層が減っていっている
- エンタメ系などは視聴者の世代交代により、年月が進めば進むほど数字を確実に落とすことになる
- 日本国内向けの内向きなCHばかりなので、海外の人に刺さる内容になっていない。
- そして海外の人向けに刺さるような努力もしていない(自動翻訳で十分だと思ってる)。
海外CHなのに、多言語対応な上に多言語音声対応までした上に、音声も専門の声優さんを採用までしているMr.Beastの動画などはそういった意味では急先鋒。こういう猛者と戦う必要があります。しかし、国内動画でそういったアクションを起こしてるCHは殆ど見かけません。
英語という言語の壁が無い海外勢はそうでなくても有利なのに、このままでは少子高齢化進行で国内動画の数字ジリ貧は当然の結果でしかありません。

字幕を用意するメリット
後述の自動字幕のデメリットにその内容を列挙していますが、多言語字幕を用意することで以下のようなメリットがあります。
- スラングや文化を考慮したニュアンスで言語を置き換える事ができる
- あからさまな自動字幕は読み手にとっては結構苦痛であるので、ナチュラルな抵抗感の無い字幕を用意して抵抗感を無くせる
- 口語と文語は表現が異なるので、テロップのように説明を短くして伝えられる
- 自動字幕と違って見やすい読みやすいデザインを適用する事が可能である
- 読み手の言語が用意されていることでユーザーとの距離感を縮められる
多言語音声機能は現在一部のトップYoutuberにのみ提供されている機能ですが、これも将来開放された場合には、多言語対応の一つとしてCHに求められてくる項目になるかと思います。
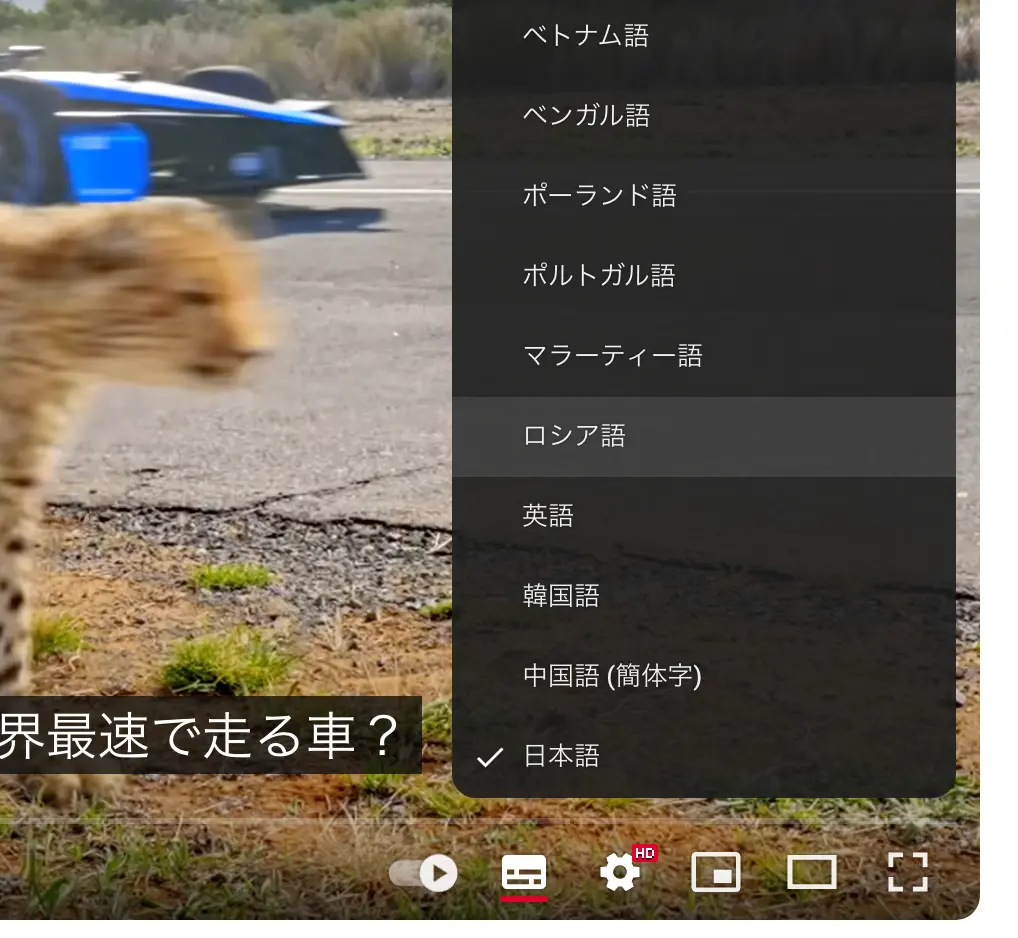
図:用意されてる字幕は抵抗感を和らげる
自動字幕のデメリット
Youtubeの自動字幕機能は確かに便利とは言えます。しかしだから自前で字幕なんて用意しなくて良いと考えるCHは多いですが、これ大きな過ちで、あの機能は便利とは言えますが使えるとは言えません。この自動字幕の問題点は以下の通り。
- 専門分野や日本独自の文化などのニュアンスが全く伝わらない機械翻訳に過ぎない
- 結果、専門用語などはその翻訳結果が大きく間違ってるケースがある(特にスラングは酷い)。
- 字幕が味気のない、本当に黒背景の白文字デカ文字で、美しくない
- 字幕タイミングが結構な割合でズレが生じてる。
- そもそも文字起こしが間違っていて校正されていない。する手段も存在しない。
これは、GoogleやMicrosoftのサービスのマニュアルなどでもよく見られる光景で、あからさまな機械翻訳で非常に読みにくい(苦痛を伴う)。これが動画の自動字幕で起きています。同じ自動字幕でも別のサービスを使うであったり、Geminiに翻訳させるであったり、ナチュラルな表現にする手段を、自作ツールでは使えます。Microsoftも最近機械翻訳でヤラカシをやっています。
自動字幕に頼った動画提供では、海外の人には到底刺さらないでしょう。
事前準備
ツール依存のデメリット
前回のGeminiで音声から文字起こしの記事では、字幕作成にAegisubやYTSubConverterといったツールも使っていました。しかし、いくつもツールを使う事や依存することになるため、以下のような問題点を抱えることになります。
- ツールのメンテナンスがされなくなり消滅する可能性
- いくつものツールを使うための学習コストが掛かるので時間が掛かる
- 結果誰でも簡単に文字起こしから字幕作成までを手軽に出来るとは言い難い
- ローカルPCにアプリを追加する必要があるのでウェブで完結しない
ツールは確かに優秀なのですが、そのたびに毎回この一連の作業を手作業で行う必要がありました。これを今回は自動化することで無くしてしまおうというのが大きな目的になります。
字幕を作るおおまかな流れ
今回の仕組みを入れることで実現できる字幕作成の流れは非常にシンプルになります。
- 動画ファイルの音声部分を取り出す(M4AやMP3といった音源)
- 今回作成のツールに1.のファイルを読み込み、Geminiを使って文字起こし
- 文字起こしデータを元に多言語に翻訳実行
- 規定のフォーマットでYTT形式の字幕ファイルをドライブに生成
- Youtubeに字幕ファイルを適用
1.や5.は人力が必要ですが手間が掛かる作業ではありません。2〜4までの作業が今回のターゲット。これまでここの作業が非常に時間の掛かる作業で、手間が掛かり、手抜きしがちなポイントでした。
Gemini のAPIキーを取得する
GeminiのAPIキーが必要です。以下のエントリーに独立してまとめています。課金されますので利用のしすぎには要注意。また課金されていない場合、学習に利用されてしまう恐れがあるので、きちんとGoogle Cloud上で課金アカウントとの紐付けなどをしておきましょう。
スクリプトプロパティに値を格納
前述までに取得しておいたGeminiのAPIキーについて、GASのスクリプトプロパティに値をセットします。
- apikey : Gemini APIのAPIキー
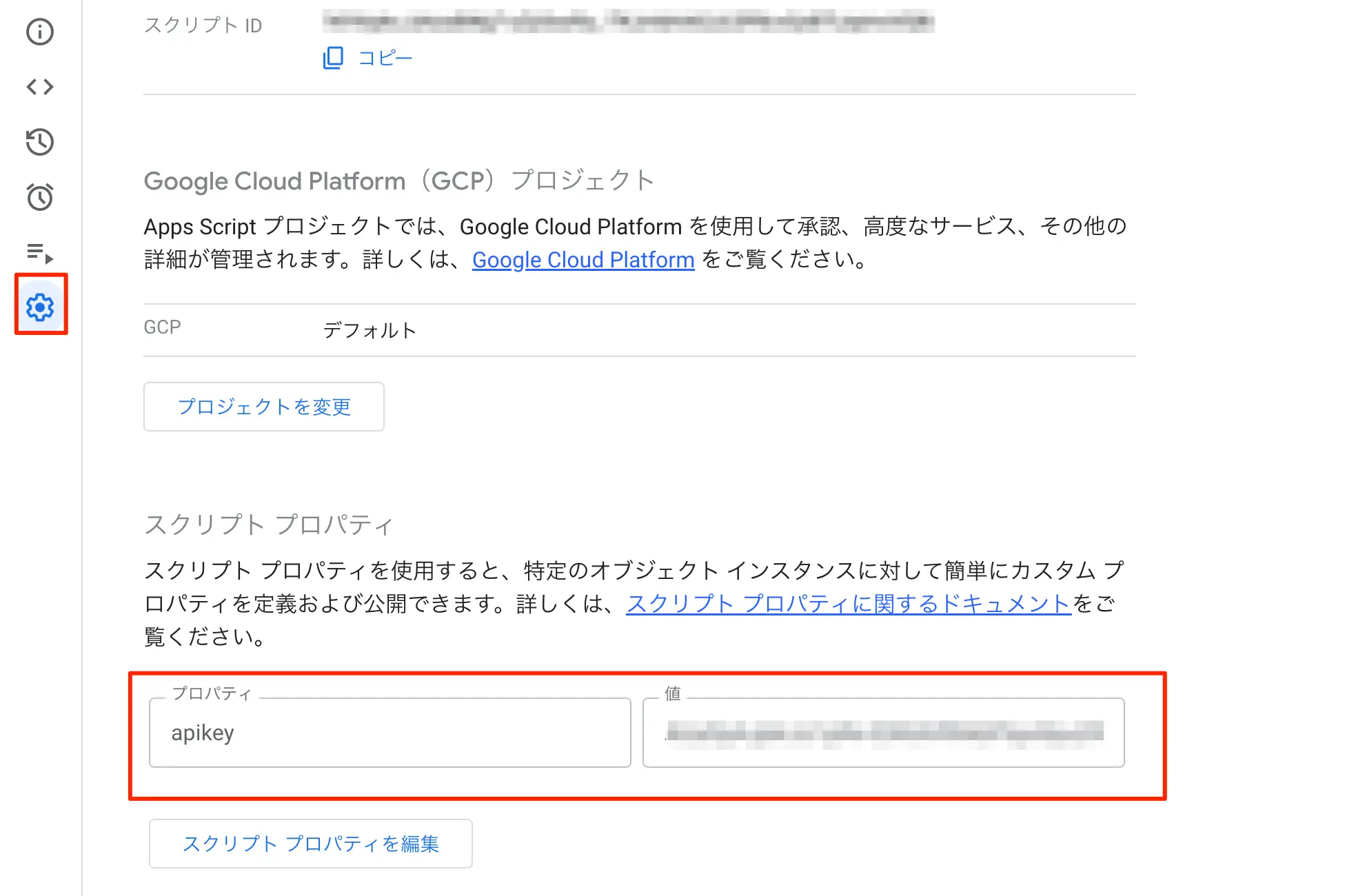
図:スクリプトプロパティに格納する
自動化する為のコード
グローバル設定
ここはプログラム全体で使う共通設定です。YTTファイルを出力先フォルダIDの指定や、文字起こしする音源ファイルのファイルIDを入れておきます。その他、スプシのメニュー表示用のスクリプトが入っています。事前に調べて入れておきましょう。
//出力先ドライブのフォルダのID
const folderid = "出力先のフォルダのIDをココに入れる";
//音声ファイル
var fileId = "M4A音源ファイルのIDをここに入れる"
//リクエストエンドポイント
const model = "gemini-2.5-pro"
const endpoint = `https://generativelanguage.googleapis.com/v1beta/models/${model}:generateContent?key=`;
//メニュー
function onOpen(e) {
let ui = SpreadsheetApp.getUi();
ui.createMenu('🇯🇵 🇺🇸 字幕作成')
.addItem('動画文字起こし', 'generateSRTFromM4A')
.addItem('英語に翻訳', 'convertTranscript')
.addToUi();
}
音声から自動文字起こし
このパートは、音源ファイルからまずは字幕用のデータをスプレッドシートに書き出すプログラムです。今回長めにプロンプトを詳細に指定しているのですが、どうしても開始時間のフォーマットが00:00:00,000という形にならないケースがあるので、フォーマットを整える為のformatTimestampsという関数を用意しています。
generateSRTFromM4Aという関数を実行すると、文字起こしが始まり、次項のパートにてYTT形式のファイルがドライブに生成されます(ここでは日本語用の字幕が生成されます)。
開始時間は喋り始めの時間であり、表示時間は終了時間ではなく喋り終わるまでの間の時間差な点に注意。
//音声ファイルから文字起こし
function generateSRTFromM4A() {
//APIキーと出力先を取得する
let prop = PropertiesService.getScriptProperties();
let apiKey = prop.getProperty("apikey");
//Google DriveからM4Aファイルを取得
const file = DriveApp.getFileById(fileId);
const blob = file.getBlob();
const base64Audio = Utilities.base64Encode(blob.getBytes());
//Gemini API にリクエスト
const transcript = transcribeAudio(base64Audio, apiKey);
if (!transcript) {
console.log("音声認識に失敗しました");
return;
}
//余計な文字を除外する
let ret = transcript.replace("```json","");
ret = ret.replace("```","");
ret = ret.replace("\n","");
//配列の値として変換
let temparr = JSON.parse(ret);
//フォーマットを修正する関数を呼び出す
const formattedArray = formatTimestamps(temparr);
//スプシを取得してクリアする
let sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("jimaku");
sheet.getRange("A2:C").clearContent();
//スプシに書き出し
let lastColumn = formattedArray[0].length; //カラムの数を取得する
let lastRow = formattedArray.length; //行の数を取得する
sheet.getRange(2,1,lastRow,lastColumn).setValues(formattedArray);
//YTT出力実行
const final = convertYtt();
}
//音声認識(Gemini API 2.5 Pro)
function transcribeAudio(audioBase64, apiKey) {
//プロンプトを記述する
let prompt = `あなたは、音源から文字起こしをするプロフェッショナルです。
アップロードされた音声ファイルを文字起こしし、配列形式で返してください。制約事項を守り、開始時間と表示時間のフォーマット、
配列の各列の値の仕様に従って出力する配列形式の通りのデータを返してください。
#音声ファイルの仕様
- 音声ファイルの言語: 日本語
- 音声ファイルの形式: m4a
#制約事項
- 出力する配列形式に従ったデータだけを返してください。余計な解説や説明は一切不要です。
- 表示時間は終了時間ではなく、終了時間から開始時間を差し引いた時間差であり、終了時間ではありません。
- 1つの発言内容の文字数は30文字以内にしてください。また発言内容の中身は改行しないでください。
#タイムスタンプの厳格なフォーマット
- 全てのタイムスタンプ(開始時間、表示時間)は、必ず hh:mm:ss,ms という形式に従ってください。
- hh (時)、mm (分)、ss (秒) は、常に2桁の数字でなければなりません。値が10未満の場合は、必ず先頭を0で埋めてください(ゼロパディング)。
- ms (ミリ秒) は、常に3桁の数字でなければなりません。値が100未満の場合は、先頭を0で埋めてください。
- このルールは絶対であり、いかなる場合も省略は許可されません。
#厳格なフォーマットの具体例
- 良い例: 00:00:05,500
- 良い例: 00:01:32,080
- 良い例: 01:15:45,123
- 悪い例: 1:32,080 (hhの省略とmmのゼロパディング不足)
- 悪い例: 00:01:32,80 (msの桁数不足)
#配列の各列の値
- 開始時間: 発言の開始時刻。上記の厳格なフォーマットに従ってください。(例: 00:01:34,689)
- 表示時間: 発言の継続時間(終了時間 - 開始時間)。上記の厳格なフォーマットに従ってください。(例: 00:00:04,400)
- 字幕: 発言内容のテキスト。
#出力する配列形式
[
["00:00:02,300","00:00:04,000", "北海道は素晴らしい場所です"],
["00:01:06,300","00:00:06,500", "厚岸駅で売ってる牡蠣飯弁当は最高の一品"],
]
#最終指示
以上の全てのルール、特に「タイムスタンプの厳格なフォーマット」を完璧に守り、JSON配列のデータのみを出力してください。他のテキストは一切不要です。
`
//リクエストエンドポイントの構築
const url = endpoint + apiKey;
//リクエストのpayloadを構築
const payload = {
contents: [{
role: "user",
parts: [
// 指示プロンプト
{
"text": prompt
},
// 音声データ
{
inlineData: {
mimeType: "audio/m4a",
data: audioBase64
}
}
]
}]
};
//リクエストオプションを指定
const options = {
method: 'post',
contentType: 'application/json',
payload: JSON.stringify(payload)
};
//Geminiにリクエストと解答を取得
const response = UrlFetchApp.fetch(url, options);
const json = JSON.parse(response.getContentText());
//結果を返す
return json.candidates && json.candidates[0] ? json.candidates[0].content.parts[0].text : null;
}
//タイムスタンプの形式を修正する関数
function formatTimestamps(data) {
return data.map(row => {
// row[0]は開始時間, row[1]は表示時間
const startTime = ensureTimestampFormat(row[0]);
const displayTime = ensureTimestampFormat(row[1]);
const text = row[2];
return [startTime, displayTime, text];
});
}
//タイムスタンプのゼロ埋め用の補助関数
function ensureTimestampFormat(timestamp) {
const parts = timestamp.split(':');
// parts.lengthが2の場合、"mm:ss,ms" 形式だと判断
if (parts.length === 2) {
return `00:${timestamp}`;
}
// すでに"hh:mm:ss,ms"形式ならそのまま返す
return timestamp;
}
YTT形式の生成
概要
スプレッドシートに書き出した字幕用元データを元に、Youtube用字幕ファイルを作成するパートです。今回使ってる手法は、前回RSSを生成する時にも利用したHTMLの文字差し込み生成テクを利用したもので、XMLファイルの中に字幕データや開始時間、表示時間のデータを差し込みして、ファイルを作っています。
GAS側コード
Google Apps Script側ではスプシのデータを元にYTT形式ファイルを作る為の具体的な作業をしています。convertYtt関数を実行すると指定の言語での字幕ファイルが作成されます。
ポイントはHTML生成し、HTML側から呼び出されるgetRecordData関数にてデータを整形した結果を受取、ドライブにファイルを作る所。翻訳実行時にも呼び出されるのでデフォルト引数としてlang = "jpn"を入れてあります(英語の場合はengが入る)。
YTT形式の時間はミリ秒で指定が必要であるので、00:00:00,000形式のデータをミリ秒変換するtimeToMilliseconds関数という補助関数を用意してあります。
//YTT形式出力
function convertYtt(lang = "jpn") {
//翻訳するかどうか?
let output = HtmlService.createTemplateFromFile('ytt.html');
//引数を一時プロパティに格納
let prop = PropertiesService.getScriptProperties();
prop.setProperty("lang",lang);
//HTML出力
let result = output.evaluate();
//変換結果を受け取る
let ytt = ContentService.createTextOutput(result.getContent()).setMimeType(ContentService.MimeType.XML);
//現在の日時を 'yyyyMMddHHmmss' 形式の文字列にフォーマット
const timestamp = Utilities.formatDate(new Date(), Session.getScriptTimeZone(), 'yyyyMMddHHmmss');
//フォーマットした日時をファイル名に使用
const fileName = `${timestamp}_${lang}.ytt`;
//ドライブにYTT形式のファイルを作成する
const fileContent = ytt.getContent();
DriveApp.getFolderById(folderid).createFile(fileName, fileContent);
//終了処理
return true;
}
//指定言語を取得
function langget(){
let prop = PropertiesService.getScriptProperties();
return prop.getProperty("lang")
}
//字幕データ元を取得する
function getRecordData(lang = "jpn"){
// スプレッドシート取得
let sheet = SpreadsheetApp.getActiveSpreadsheet();
let ss = "";
//翻訳出力するかどうか
let selectsheet = ""
if(lang == "jpn"){
selectsheet = "jimaku";
}else{
selectsheet = "translation";
}
//シートデータを取得する
ss = sheet.getSheetByName(selectsheet).getRange("A2:C").getValues();
//取得データを回して空行はスルーする
let array = [];
for(let i = 0;i < ss.length; i++){
//レコードを一個取り出す
let rec = ss[i];
//空だった場合スルーする
if(rec[0] == "" || rec[0] == undefined){
continue;
}
//時間データをミリ秒変換して配列に加える
const temparr = [
timeToMilliseconds(rec[0]),
timeToMilliseconds(rec[1]),
rec[2]
]
//配列に加える
array.push(temparr);
}
//値をHTML側に返却する
return array;
}
//時間形式をミリ秒に変換する関数
function timeToMilliseconds(timeString) {
//時間データを時、分、秒、ミリ秒に分割します
const [time, milliseconds] = timeString.split(',');
const [hours, minutes, seconds] = time.split(':');
//全てをミリ秒に変換して合計します
const totalMilliseconds =
parseInt(hours, 10) * 60 * 60 * 1000 +
parseInt(minutes, 10) * 60 * 1000 +
parseInt(seconds, 10) * 1000 +
parseInt(milliseconds, 10);
return totalMilliseconds;
}
HTML側コード
ytt.htmlというファイルの中身です。この中にもループでGASのコードが入っています。
Head部分は字幕のフォント、装飾、色などを指定しています。body以下で、ループで実際の字幕データを差し込みしています。t=の部分が表示開始の時間、d=が表示している時間の値が入り、rec[2]の部分が字幕の文字列が入ります。
このHTML部分ですが、字幕部分に変な改行やスペースを入れるとゼロ幅スペースという、字幕表示した時に黒い■が表示される原因となることがあるので要注意ポイントです。
<xml version="1.0" encoding="utf-8">
<timedtext format="3">
<head>
<wp id="0" ap="7" ah="0" av="0" />
<wp id="1" ap="7" ah="50" av="100" />
<ws id="0" ju="2" pd="0" sd="0" />
<ws id="1" ju="2" pd="0" sd="0" />
<pen id="0" sz="100" fc="#000000" fo="0" bo="0" fs="2" />
<pen id="1" sz="0" fc="#A0AAB4" fo="0" bo="0" fs="2" />
<pen id="2" sz="100" b="1" fc="#FEFEFE" fo="254" bo="0" et="4" ec="#433939" fs="2" />
<pen id="3" sz="100" b="1" fc="#FEFEFE" fo="254" bo="0" et="3" ec="#0022FF" fs="2" />
</head>
<body>
<?
var arg = langget();
var rowdata = getRecordData(arg);
for(let i = 0; i < rowdata.length; i++){
let rec = rowdata[i];
?>
<p t=<?=rec[0]?> d=<?=rec[1]?> wp="1" ws="1"><s p="2"><?= rec[2] ?></s></p>
<p t=<?=rec[0]?> d=<?=rec[1]?> wp="1" ws="1"><s p="3"><?= rec[2] ?></s></p>
<? } ?>
</body>
</timedtext>
</xml>
英語に翻訳実行
今回、機械翻訳に精度の低いLanguageAppを利用せずに、Geminiに対して日本語字幕部分をナチュラルな英語として翻訳して返すように指示しています。
convertTranscript関数を実行すると生成済みのjimakuシートのデータを元に、英訳した内容をtranslationシートに出力。前述のYTT形式の出力用関数に引き継いで英語版の字幕ファイルの生成まで一気に行っています。
文字数を押さえる目的と機械翻訳臭を低減する為に、プロンプトでは文字数制限や言い回しの置き換え、フレンドリーな表現といった指定を加えて、ナチュラルな英訳に作り変えてもらっています。文字数制限をする理由は、字幕表示した時に画面からはみ出してしまうのを防ぐため。
英語と日本語では日本語のほうが短い単語で表現でき、英語だと冗長になる傾向があるので、このような変換指定をしています。
//字幕データを英語に翻訳する
function convertTranscript() {
//スプレッドシートを取得する
let sheet = SpreadsheetApp.getActiveSpreadsheet();
//シートを取得する
let ss = sheet.getSheetByName("jimaku").getRange("A2:C").getValues();
let trans = sheet.getSheetByName("translation");
//APIキーと出力先を取得する
let prop = PropertiesService.getScriptProperties();
let apiKey = prop.getProperty("apikey");
//Gemini API にリクエスト
const transcript = translationNaturalEng(ss, apiKey);
if (!transcript) {
console.log("音声認識に失敗しました");
return;
}
//余計な文字を除外する
let ret = transcript.replace("```json","");
ret = transcript.replace("```javascript","");
ret = ret.replace("```","");
ret = ret.replace("\n","");
//配列の値として変換
let temparr = JSON.parse(ret);
//スプシを取得してクリアする
trans.getRange("A2:C").clearContent();
//スプシに書き出し
let lastColumn = temparr[0].length; //カラムの数を取得する
let lastRow = temparr.length; //行の数を取得する
trans.getRange(2,1,lastRow,lastColumn).setValues(temparr);
//YTT出力実行(英語出力)
const final = convertYtt("eng");
}
//Geminiにナチュラルな翻訳をしてもらう
function translationNaturalEng(ss,apiKey){
//プロンプトを記述する
let prompt = `あなたはプロの翻訳家です。以下の翻訳対象データに対して、制約要件、翻訳条件を満たした翻訳結果のデータを返してください。
#翻訳対象データ
翻訳対象データはJavaScriptの配列として、二次元配列で格納されています。以下そのデータ。
${ss}
#制約要件
- 出力する配列形式に従ったデータだけを返してください。余計な解説や説明は一切不要です。
- 1つの発言内容の翻訳結果の文字数は50文字以内にうまく言い回しや単語の置き換えでまとめてください。
#翻訳条件
- 翻訳するのは2次元配列の1レコードのうち、3列目の文字データが対象です。
- 翻訳結果を3列目の文字データと置き換えて返してください。
- 日本語の文字列を英語に翻訳してください
- 字幕として使うので、可能な限り短いセンテンスで置き換えてください(50文字以内)。
- スラング表現であっても構いません。
- フレンドリーでナチュラルな現代の会話の英語として翻訳してください。
#出力する配列形式サンプル
[
["00:00:02,300","00:00:04,000", "Hokkaido is a wonderful place"],
["00:01:06,300","00:00:06,500", "The oyster rice bento sold at Akkeshi Station is the best dish."],
]
`;
//リクエストのpayloadを構築
const payload = {
contents: [{
role: "user",
parts: [
// 指示プロンプト
{
"text": prompt
}
]
}]
};
//リクエストエンドポイントの構築
const url = endpoint + apiKey;
//リクエストオプションを指定
const options = {
method: 'post',
contentType: 'application/json',
payload: JSON.stringify(payload)
};
//Geminiにリクエストと解答を取得
const response = UrlFetchApp.fetch(url, options);
const json = JSON.parse(response.getContentText());
//結果を返す
return json.candidates && json.candidates[0] ? json.candidates[0].content.parts[0].text : null;
}
完成品
字幕ファイルを適用してみた
自身の動画に対して、日本語および英語でのYTT形式の字幕を付けてみました。キレイな明朝体風の字幕が表示されると思います。微調整とかしていないので、本来はここから微調整してytt.htmlの側で調整を加える必要があります。
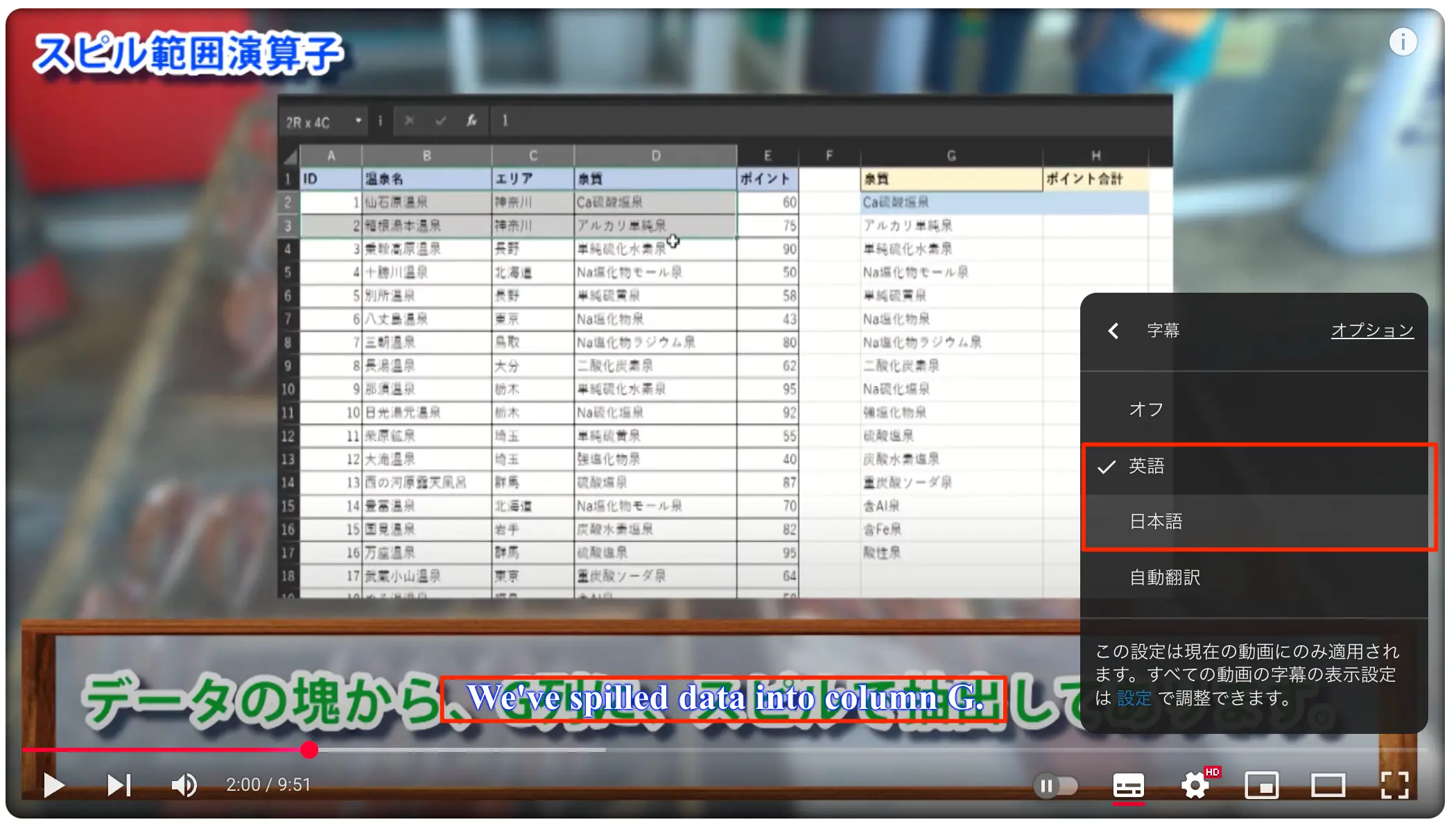
図:2つの字幕を追加し、表示してみた

他の同様の手法を利用してる事例
YTT形式の字幕を使って、カラフルで且つ動きのあるカラオケ風字幕を実現しています。特に音楽系ではこれまで、動画のテロップとしてハードコードしていた字幕は特定言語に限られていたわけですが、YOASOBIのように海外展開を行うようなCHでは、ソフトコードな字幕ファイルで切り替えられるのは、ユーザビリティの一つになります。
ハードコードしてしまうと書き換えも出来ないので、置き換えも出来ずといった不便さもあるため、積極的に字幕ファイルを利用して動画に一手間をいかに低労力で掛けられるか?が成功の分かれ目になるかもしれません。
![にじさんじ - Virtual to LIVE [Official Music Video]](https://officeforest.org/wp/wp-content/plugins/wp-youtube-lyte/lyteCache.php?origThumbUrl=https%3A%2F%2Fi.ytimg.com%2Fvi%2FzPMWAj54Seg%2F0.jpg)

