NotebookLMの音声概要をずんだもんに置き換えてみた
先日日本語でのポッドキャスト生成対応したGoogleのNotebookLM。音声概要なのでNotebookLM内の資料を元にサマリー的な内容を男女二人の音声でラジオ番組風に再現してくれる非常に優れた機能です。
この音声概要はWAVファイルでダウンロード出来ますが、このデータを元に男女二人の音声をVoiceVoxを使って、ずんだもんと四国めたんの2名の声に差し替えてみようという試みです。macOSで作成の手順を解説していますが、Windowsでもそこまで変わりません。
目次
今回利用するツール等
- NotebookLM Plus
- Gemini 2.5 Pro(今回はGoogle AI Studioを使っています。文字起こし担当です)
- Node.js(VoiceVox APIにアクセスして音源生成やffmpeg実行に使います)
- VoiceVox(テキストから二人の音声データを生成します)
- Google Vids(空の同じ尺の動画を生成する為に利用)
- ffmpeg(mp4ファイルにwavを差し込みえんコードに利用)
色々なツールを使っていますが、環境を整えてしまえばそこまで苦にはなりません。NotebookLMについての詳細については、以下のエントリーを参照してください。
動画のサムネというか背景画像についてだけは、ChatGPTにて生成してもらっています。事前にNode.js、VoiceVoxおよび、ffmpegのインストールが必要になります。自分の場合macOSなのでNode.jsとffmpegはhomebrewからインストールしています。VoiceVoxでは四国めたんとずんだもんはダウンロードしておき使えるようにしておきます。
今回のサンプルとなる音声ファイルは、こちらにアップロードされています。
事前準備
NotebookLMにて音声概要を作成する
NotebookLMにて資料を追加し、右上の音声概要にて「生成」をクリックするとおよそ6分程度のサマリー音声が生成されます。これをダウンロードして保存しておきます。
現在は日本語で生成がデフォルトになっているハズなので一応再生して、おかしな点がないかをチェックしておきましょう。ダウンロード音声はWAV形式ですが、自分の場合はこれをQuickTime PlayerにてM4A形式に変換して書き出しておきました。書き出す際にカスタマイズで、色々と指示をしておく事が出来るので、喋り方やスピードなどを調整可能ですが今回はカスタマイズ無しで出力しています。
※今回のこの元ネタはGemini AdvancedのDeep Researchの結果を読み込ませています。
※Gemini APIはwavのままでもアップロード出来るので、M4Aにわざわざ変換せずとも大丈夫です。対応フォーマットリファレンスはこちらにあります。(何故かM4Aがありませんが、対応しています)。Gemini Advanced上ではWAVは何故かアップロード出来ませんが・・・
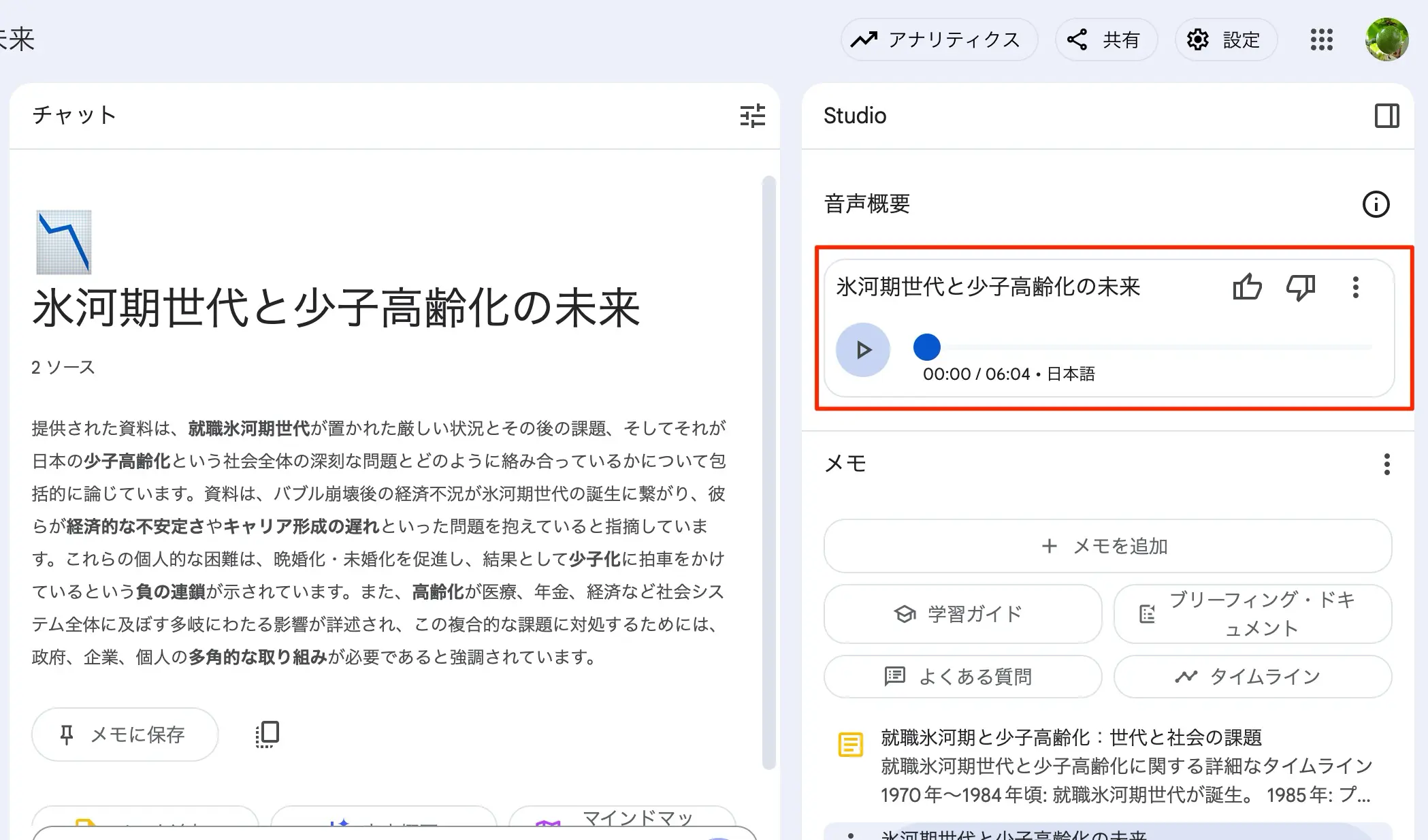
図:音声概要が生成された様子
Geminiにて文字起こしを作成する
前述で書き出した音声概要のファイル。男女二名のラジオ番組風になっています。この音声ファイルを以下の手順でGemini 2.5 Proにて文字起こしをしてもらいます。Node.jsでAPIリクエストとデータを得る部分も構築可能です(後述のtranscribe.jsで紹介しています)。
- Google AI Studioを開く
- 右上のRun SettingsにてモデルがGemini 2.5 Proになっているかを確認
- プロンプト欄に前述で用意した音声ファイルをアップロードする
- プロンプトとして以下のような内容を指示してRunを実行
アップロードされたM4Aファイルを文字起こしし、以下の形式のJSON形式でデータを返してください。 音声ファイルの言語: 日本語 話者: A, B (対話形式) 音声ファイルの形式: m4a 話者A,Bを聞き分けて、以下フォーマットのように誰の発言か?わかるようにしてください。 JSONフォーマットは以下の通りです。 [ { human:"A", talk : "文字起こしの内容", starttime : "開始時間" } ] タイムレコードはミリ秒単位で正確に出力してください。0:00:25.51ならば、25510という具合に。 1つの発言内容の文字数は可能な限り30文字以内にしてください。また発言内容の中身は改行しないでください。 文字起こし内容は一度文章校正してから出力してください。ただ、このプロンプトは字幕生成用のプロンプトなので、30字以内という制限は、50字以内などのもうちょっと緩和したほうが、会話がナチュラルになりぶつ切りになりません。
- JSON化された結果だけが下の欄に生成されるので、これをテキストとして保存する(ファイル名はmoji.jsonとしました)
A, Bにわけている理由はこれを基準に、ずんだもんと四国めたんそれぞれの音声を生成するためです。starttimeはffmpegで差し込む時の時間でミリセカンドで指定する必要があります。
※wavの場合は、音声ファイルの形式はwavで指定すると良いです。
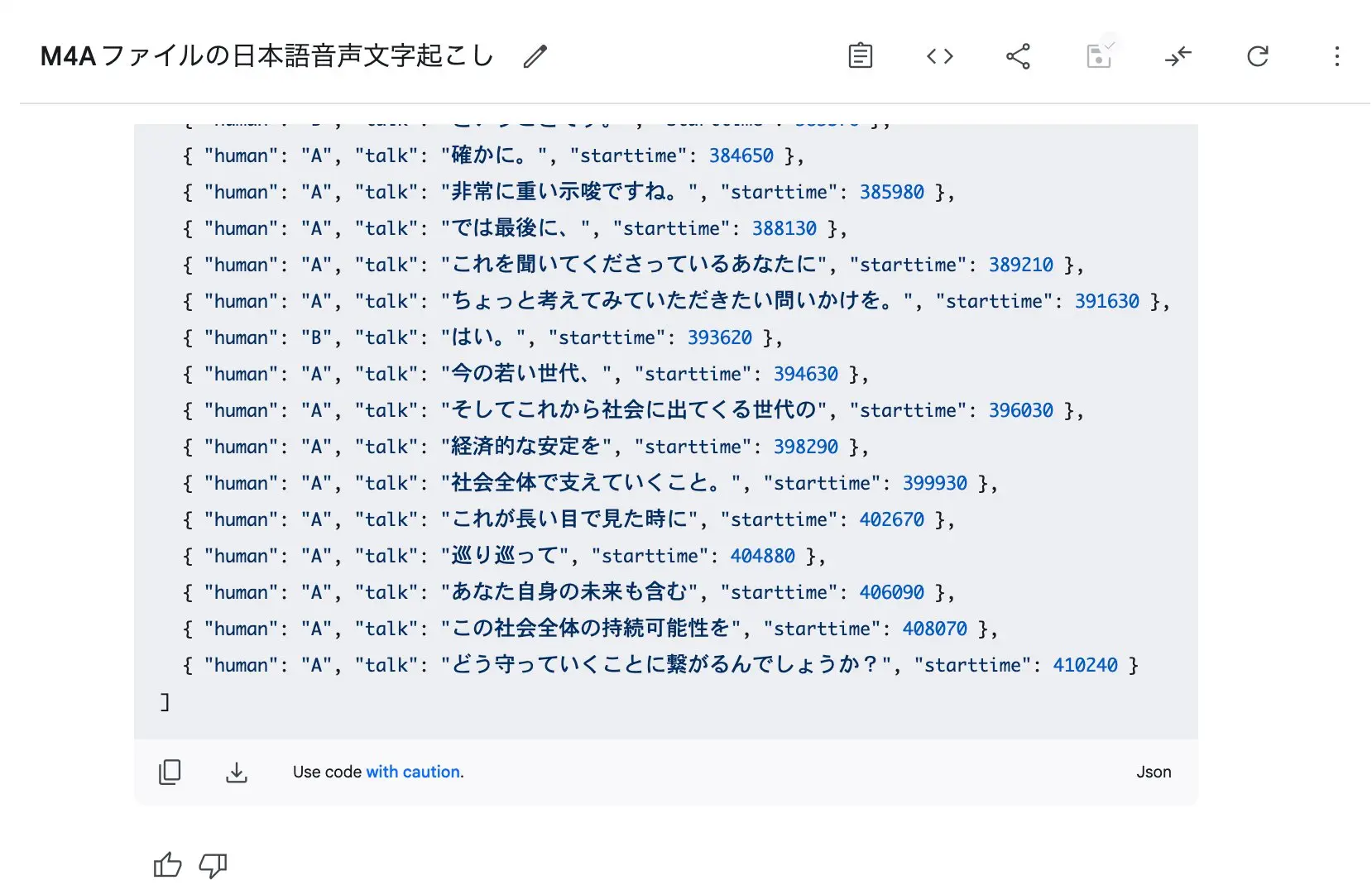
図:無事にJSON形式で文字起こしがされました。
Google Vidsで空の動画を作成する
生成された音声ファイルの尺を元に、Google Vidsで空っぽの動画を作ります。今回は空というのもアレなので、画像を1枚生成しておき、貼り付けてあります。
タイムラインに音声ファイルを差し込み、その長さに合わせて貼り付けた画像のシーンをぴったりの長さまで広げます。今回は音声が6:52.8の長さだったのでそこまで広げられたら、音声は削除し、ダウンロードを実行します。
音声なしのMP4動画がこれで入手出来ました(ファイル名はnotebook.mp4とでもしました)
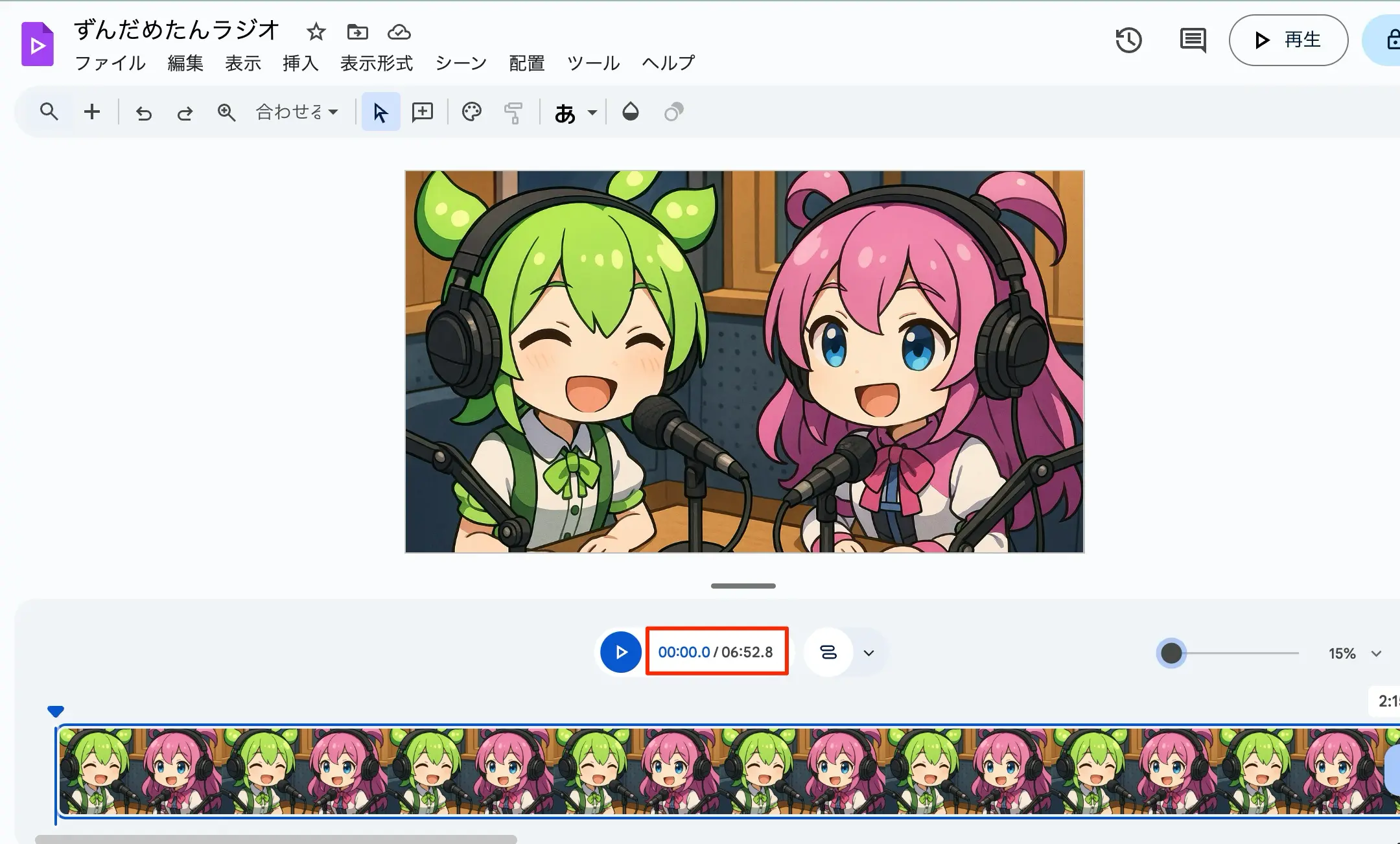
図:Vidsで音声なしMP4を作っておく
Node.jsのプロジェクトを作成しておく
今回の音声差し替えはNode.jsを使って入手した文字起こしデータ、空の動画ファイルを利用して、一括でWAVファイルを生成し、MP4動画に対して差し込みをしていきます。
以下の手順でプロジェクトを作ってファイルを格納していきます。
- ターミナルを開いて以下のコマンドを実行しプロジェクトを作ります。
cd Documents mkdir zunda npm init -y
zundaというフォルダを作成し、初期化実行でpackage.jsonが生成されます。
- 作成したzundaというフォルダに、Google AI Studioで作成した文字起こしデータおよび空の動画データを格納しておきます。
- index.jsおよびffmpeg.js, transcribe.jsという空のテキストデータを同じフォルダに作成しておきます。
作成方法
話者一覧を取得する
次項のindex.jsではmoji.jsonのhumanがAならばずんだもん、Bならば四国めたんを生成キャラとして条件分岐しています。この時speakeridというのを指定してるのですが、この一覧を取得することが可能です。ささやき声バージョンなどでIDが異なりますし、ずんだもんや四国めたん以外も導入していて使いたい場合にはこのIDを知る必要があります。
- VoiceVoxを起動する
- こちらのURLを開く
- /SpeakersのTry it outボタンをクリックする
- executeボタンをクリックする
- Response Bodyに答えが返ってくる
すると、IDが3はずんだもんのノーマル、IDが2は四国めたんのノーマルだということがわかります。
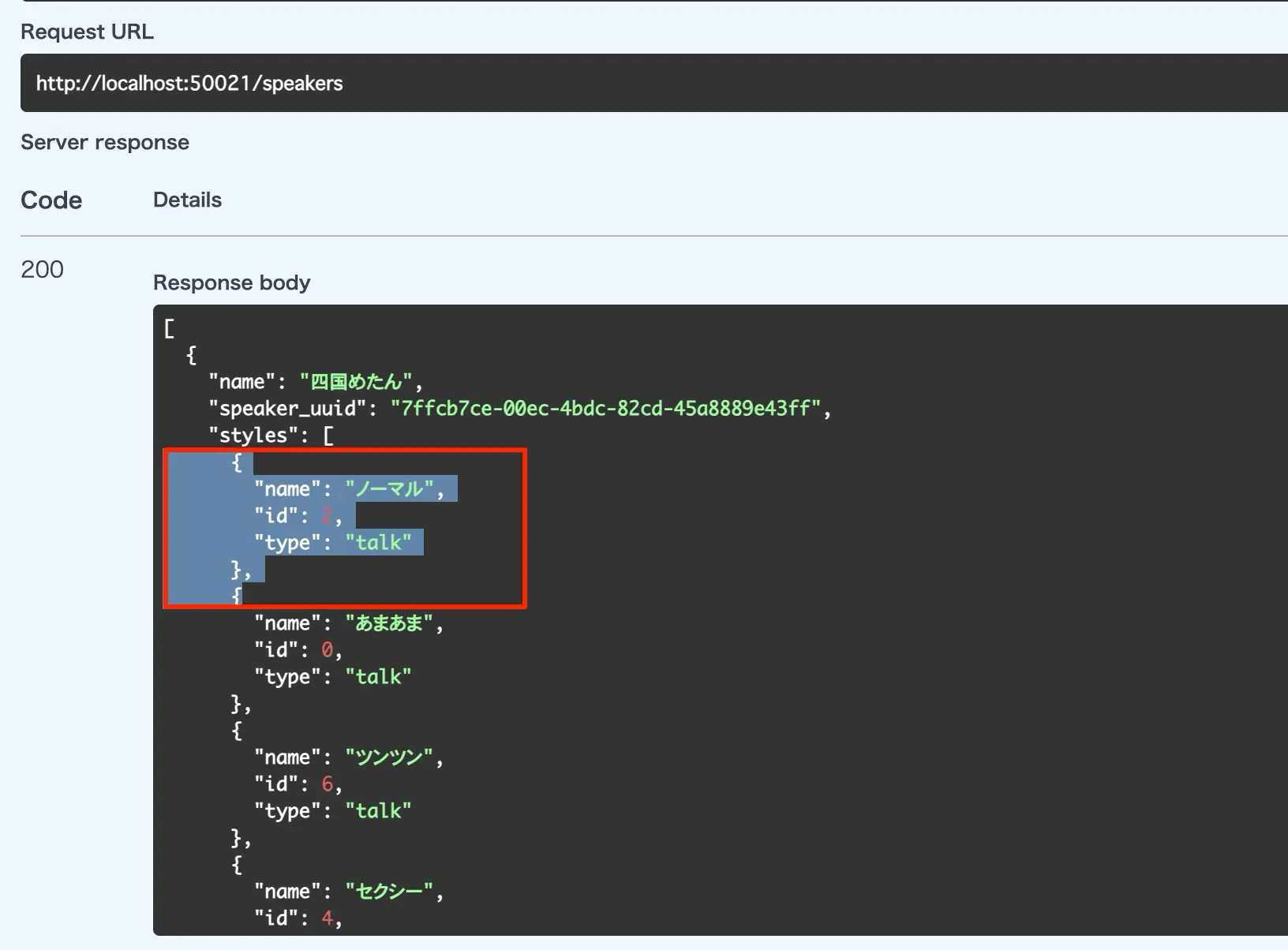
図:演者のIDを調べる方法
変換用のソースコード
Gemini 2.5 Proで生成
実は今回の取組の裏テーマとして、いつもは自身で書いてるNode.jsやffmpegのコマンドをGemini 2.5 Proで生成できないか?ということで作成しています。ChatGPTでも同様に作成することが可能です。
故に今回掲載してるソースコードは、自身はわずかしか手直ししていません。ほぼノーコード状態でこの変換を実現することが出来ました。多少追い込みが必要ですが、極めて短い時間で変換用のソースコードの開発が出来ています。
Node.jsは少々癖の強い言語で自分も結構長い間付き合っていますが、それでも生成AIでここまで短時間に仕上げられるというのは驚きでした。積極的にNode.jsでの開発に使えそうです。
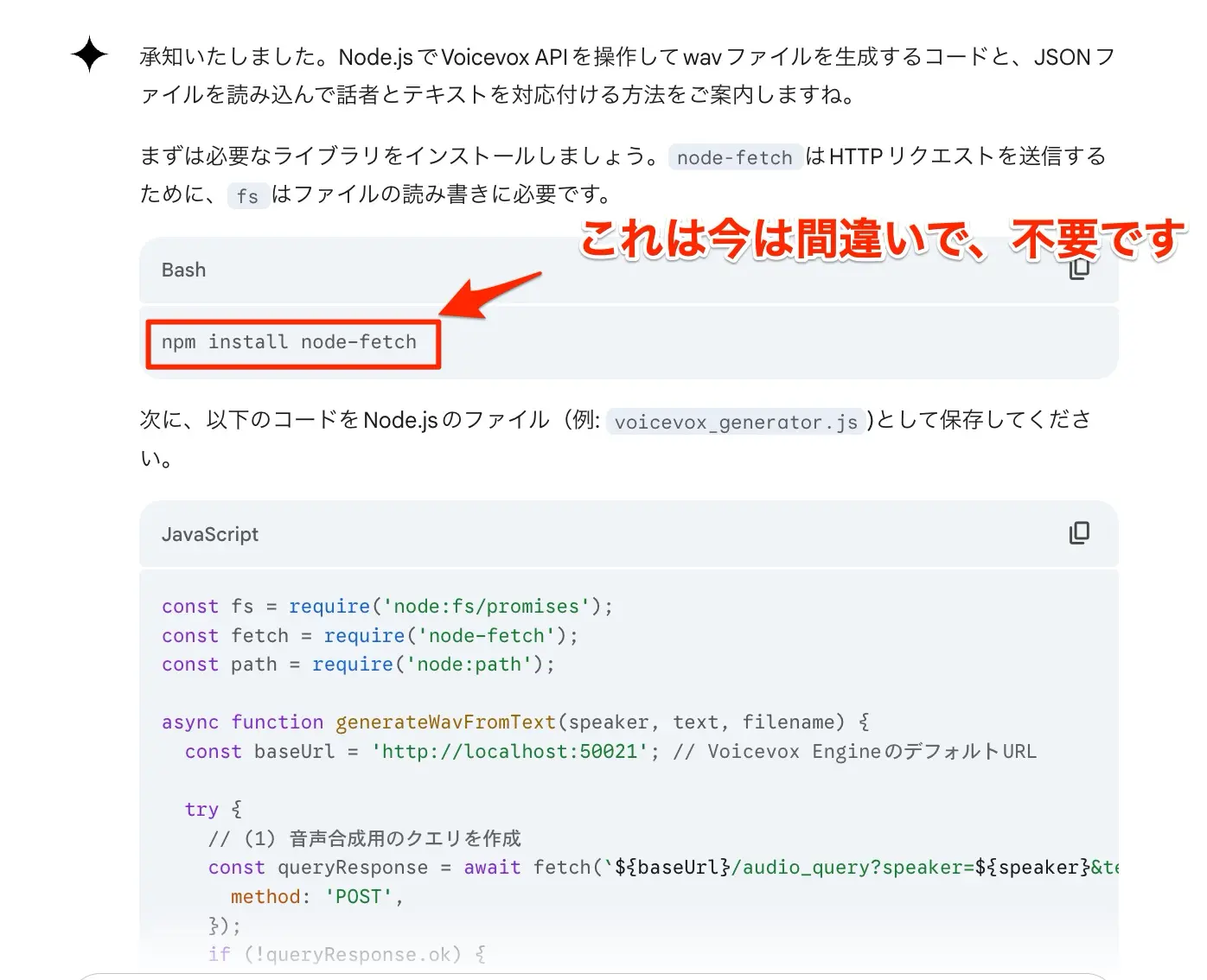
図:超短時間で開発出来ました
transcribe.js
ローカルにあるNotebookLMの音声概要から出力したファイルを自分の場合はQuickTime PlayerにてM4Aに変換しています。そのファイルを読み込ませて、VoiceVox APIリクエストやffmpeg変換用のJSONファイルを生成するための文字起こし用スクリプトです。事前に、Google AI StudioにてAPIキーの取得が必要です。
前述のGoogle AI Studioでのリクエスト結果と同じものが取得できますが、こちらはそれをNode.jsにてGemini 2.5 Pro APIにリクエストを投げて取得しています。タイムアウトは300秒(5分)以上でセットしないと、デフォルトで30秒でfetch APIのリクエストが止まってしまうようなので、調整しました。
target.m4aを読み込み、moji.jsonとしてローカルに生成します。
※wavの場合はプロンプト内の音声ファイルの形式はwavとし、payload内のmimeTypeはaudio/wavとすると良いです。
const fs = require('node:fs').promises;
const path = require('node:path');
const { Buffer } = require('node:buffer');
// 環境変数からAPIキーを取得
const geminiApiKey = "ここにGeminiのAPIキーを入れる";
const localM4aFilePath = "./target.m4a"; // ローカルのM4Aファイルのパスを設定(今回はtarget.m4aとしました)
const FETCH_TIMEOUT = 300000; //リクエストタイムアウト(5分)
async function generateJsonFromM4A() {
if (!geminiApiKey) {
console.error("環境変数 GEMINI_API_KEY が設定されていません。");
return;
}
try {
// ローカルのM4Aファイルを読み込む
const audioBuffer = await fs.readFile(localM4aFilePath);
const base64Audio = audioBuffer.toString('base64');
// Gemini API にリクエスト
const transcript = await transcribeAudio(base64Audio, geminiApiKey);
if (!transcript) {
console.log("音声認識に失敗しました");
return;
}
// 不要なプレフィックスとサフィックスを削除
let cleanedTranscript = transcript;
cleanedTranscript = cleanedTranscript.replace(/```json\n/g, '');
cleanedTranscript = cleanedTranscript.replace(/```/g, '');
// JSON形式の文字起こし結果をそのまま保存
const jsonFilePath = path.join(__dirname, 'moji.json');
await fs.writeFile(jsonFilePath, cleanedTranscript, 'utf8');
console.log(`JSON形式の文字起こし結果を ${jsonFilePath} に保存しました。`);
} catch (error) {
console.error("エラーが発生しました:", error);
}
}
// 音声認識(Gemini API)
async function transcribeAudio(base64Audio, apiKey) {
const prompt = `アップロードされたM4Aファイルを文字起こしし、以下の形式のJSON形式でデータを返してください。
音声ファイルの言語: 日本語
話者: A, B (対話形式)
音声ファイルの形式: m4a
話者A,Bを聞き分けて、以下フォーマットのように誰の発言か?わかるようにしてください。
JSONフォーマットは以下の通りです。
[
{
human:"A",
talk : "文字起こしの内容",
starttime : "開始時間"
}
]
タイムレコードはミリ秒単位で正確に出力してください。0:00:25.51ならば、25510という具合に。
1つの発言内容の文字数は可能な限り50文字以内にしてください。また発言内容の中身は改行しないでください。
文字起こし内容は一度文章校正してから出力してください。
`;
const url = `https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-pro-exp-03-25:generateContent?key=${apiKey}`;
//リクエストタイムアウト用の設定
const controller = new AbortController();
const id = setTimeout(() => controller.abort(), FETCH_TIMEOUT);
const payload = {
contents: [{
role: "user",
parts: [{
inlineData: {
mimeType: "audio/m4a",
data: base64Audio
}
}]
}],
"systemInstruction": {
"parts": [
{
"text": prompt
}
]
}
};
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(payload),
signal: controller.signal, // AbortController の signal を渡す
});
clearTimeout(id);
const jsonResponse = await response.json();
return jsonResponse.candidates && jsonResponse.candidates[0] ? jsonResponse.candidates[0].content.parts[0].text : null;
} catch (error) {
clearTimeout(id);
if (error.name === 'AbortError') {
console.error(`Fetchリクエストが ${FETCH_TIMEOUT / 1000} 秒でタイムアウトしました。`);
return null;
}
console.error("Gemini API リクエストエラー:", error);
return null;
}
}
// スクリプトの実行
generateJsonFromM4A();
index.js
index.jsをVSCodeなどで開いて以下のソースコードを記述。ずんだもんの喋りがデフォルトだとちょっとゆっくり過ぎるので、1.5倍速で指定し、四国めたんも1.2倍速で調整しています。
会話ボリュームが小さすぎるのでここも3.0にしていますが、ここもYoutubeにアップすると小さく聞こえるので6.0くらい指定しても良いかもです。
zundaフォルダ内に音声ファイルが文字起こしデータにしたがって生成されて、moji.jsonにfileという要素でファイル名が追記されていきます。speakerIdがずんだもんや四国めたんなどのキャラクター指定が可能になります。
const fs = require('node:fs/promises');
const path = require('node:path');
//会話スピード倍増
const zunda = 1.5;
const metan = 1.2;
//会話ボリューム倍増
const volumeman = 3.0;
async function generateWavFromText(speaker, text, filename) {
const baseUrl = 'http://localhost:50021'; // Voicevox EngineのデフォルトURL
try {
// (1) 音声合成用のクエリを作成
const queryResponse = await fetch(`${baseUrl}/audio_query?speaker=${speaker}&text=${encodeURIComponent(text)}`, {
method: 'POST',
});
if (!queryResponse.ok) {
console.error(`Error creating audio query for "${text}": ${queryResponse.status} ${queryResponse.statusText}`);
return null;
}
const queryData = await queryResponse.json();
// 🔧 ずんだもん(speakerId: 3)のとき、喋る速度を上げる
if (speaker === 3) {
queryData.speedScale = zunda;
}else if(speaker === 2){
queryData.speedScale = metan;
}
// 🔊 全キャラ共通で音量を上げる
queryData.volumeScale = volumeman;
// (2) 音声合成を実行し、WAVデータを取得
const synthesisResponse = await fetch(`${baseUrl}/synthesis?speaker=${speaker}`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(queryData),
});
if (!synthesisResponse.ok) {
console.error(`Error synthesizing audio for "${text}": ${synthesisResponse.status} ${synthesisResponse.statusText}`);
return null;
}
const buffer = await synthesisResponse.arrayBuffer();
// (3) WAVファイルを保存
const filePath = path.join(__dirname, `${filename}.wav`);
await fs.writeFile(filePath, Buffer.from(buffer));
console.log(`Successfully generated: ${filename}.wav`);
return `${filename}.wav`;
} catch (error) {
console.error(`An error occurred: ${error}`);
return null;
}
}
async function processMojiJsonAndUpdate() {
try {
const jsonData = await fs.readFile('moji.json', 'utf-8');
const mojiData = JSON.parse(jsonData);
for (const item of mojiData) {
let speakerId;
if (item.human === 'A') {
speakerId = 3; // ずんだもん(ノーマル)
} else if (item.human === 'B') {
speakerId = 2; // めたん(ノーマル)
} else {
console.warn(`Unknown human type "${item.human}". Skipping.`);
continue;
}
const filename = `${item.human}_${item.starttime}`;
const generatedFilename = await generateWavFromText(speakerId, item.talk, filename);
if (generatedFilename) {
item.file = generatedFilename;
}
}
const outputJson = JSON.stringify(mojiData, null, 2);
await fs.writeFile('moji.json', outputJson, 'utf-8');
console.log('Finished processing moji.json and updated it.');
} catch (error) {
console.error(`Error reading or processing moji.json: ${error}`);
}
}
// メイン処理
async function main() {
await processMojiJsonAndUpdate();
}
main();
ffmpeg.js
こちらは、moji.jsonの値に基づいて、VoiceVoxで生成されたファイルを一括でffmpegを用いて空の動画ファイルに差し込んでエンコードまで実行します。output.mp4というファイルが出来上がります。
starttimeが差し込み時間、fileが差し込む音声ファイルとなっています。ffmpeg側でも音声倍増指定が出来ます。
const fs = require('fs');
const { exec } = require('child_process');
//音量倍増
const volumeman = 5.0;
// 1. moji.jsonを読み込む
const moji = JSON.parse(fs.readFileSync('moji.json', 'utf8'));
// 2. ffmpegの入力・filter・amix部分を構築
let inputArgs = ['-i notebook.mp4'];
let filterLines = [];
let mapInputs = [];
moji.forEach((item, i) => {
const idx = i + 1;
inputArgs.push(`-i "${item.file}"`);
const label = `a${idx}`;
filterLines.push(`[${idx}:a]adelay=${item.starttime}|${item.starttime}[${label}]`);
mapInputs.push(`[${label}]`);
});
// 音量ブースト付きのfilter_complex
const filterComplex = `${filterLines.join('; ')}; ${mapInputs.join('')}amix=inputs=${moji.length}:duration=longest[mixed]; [mixed]volume=${volumeman}[aout]`;
// ffmpegコマンド
const ffmpegCmd = `ffmpeg ${inputArgs.join(' ')} -filter_complex "${filterComplex}" -map 0:v -map "[aout]" -c:v copy -shortest output.mp4`;
// 実行
console.log('⏳ ffmpegコマンドを実行します(音量ブーストあり)...');
console.log(ffmpegCmd);
exec(ffmpegCmd, (err, stdout, stderr) => {
if (err) {
console.error('❌ エラー:', err);
return;
}
console.log('✅ 完了しました。output.mp4 が生成されました(音量アップ済)');
});
変換手順
ここまでですべての準備が整い、あとはターミナルから順番にプログラムを実行するだけです。
- VoiceVoxを起動しておきます(ローカルの50021番ポートにアクセスします)。起動しておかないと、「An error occurred: TypeError: fetch failed」というエラーが出てしまいます。
- ターミナルを起動して、zundaフォルダまで移動しておきます。
- まずは、index.jsを実行してmoji.jsonを元にVoiceVoxにて一括で音声ファイルを生成し、moji.jsonにファイル名を追記します。
node index.js
- 次に、moji.jsonと生成された音声ファイルを元にffmpeg.jsを実行してnotebook.mp4ファイルに音声ファイルを指定msにて差込エンコード
node ffmpeg.js
- output.mp4が出来上がるので再生してみて、ズレや発言の被りなどが無いか?音量は十分か?をチェックして完成。
実際に環境を整えてからの、音声概要ファイルの準備等含めて、動画完成までおよそ30分程度で簡単に作成が出来ます。
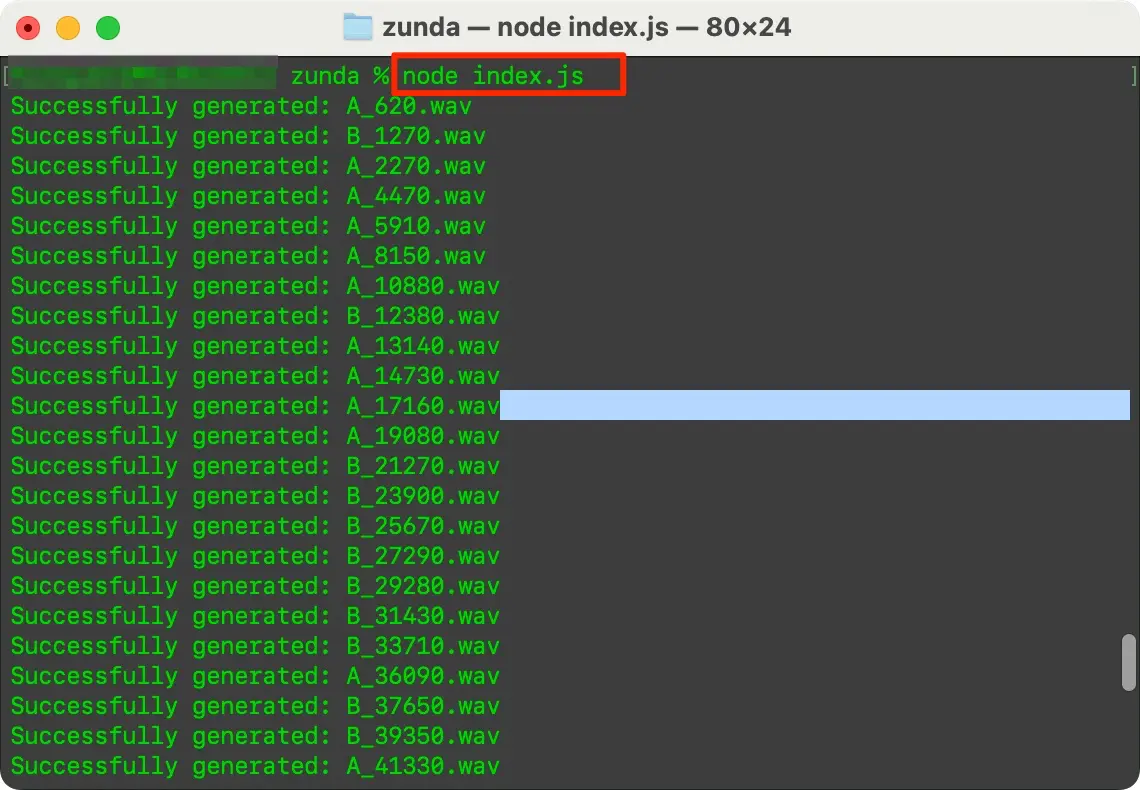
図:2名の音声ファイルがmsを名前にして生成されます
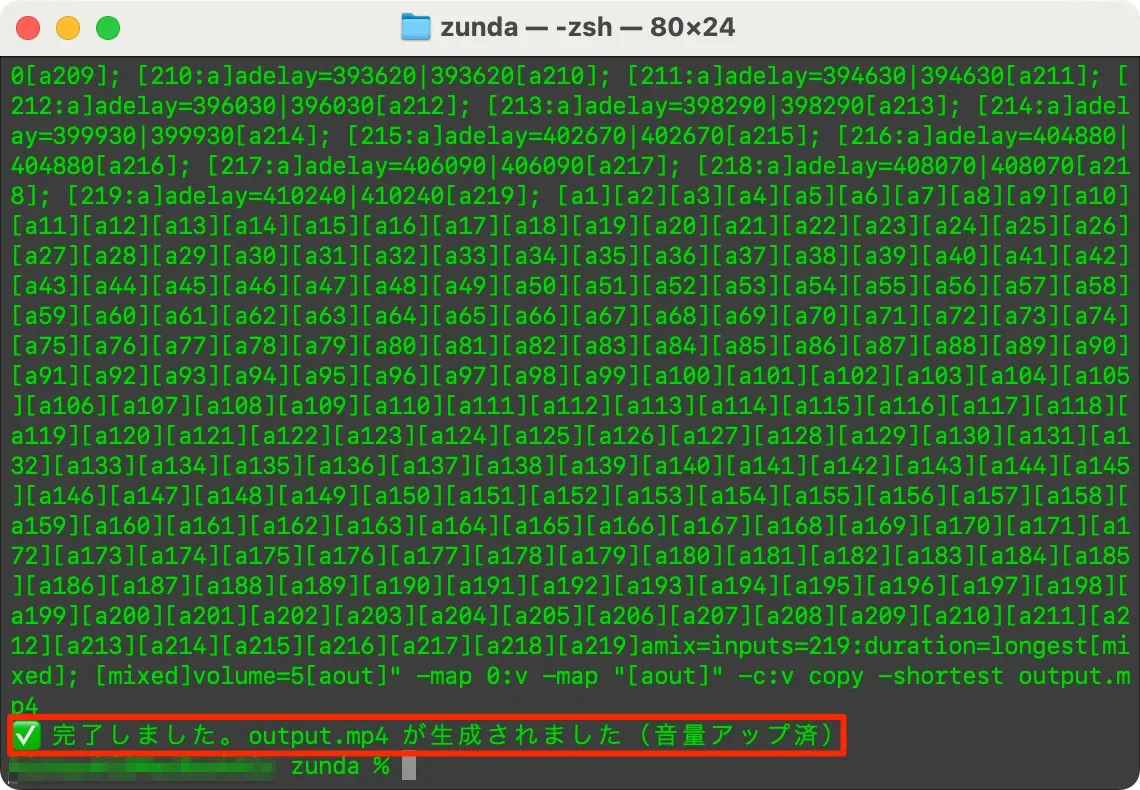
図:ffmpegのコマンドライン生成と実行結果
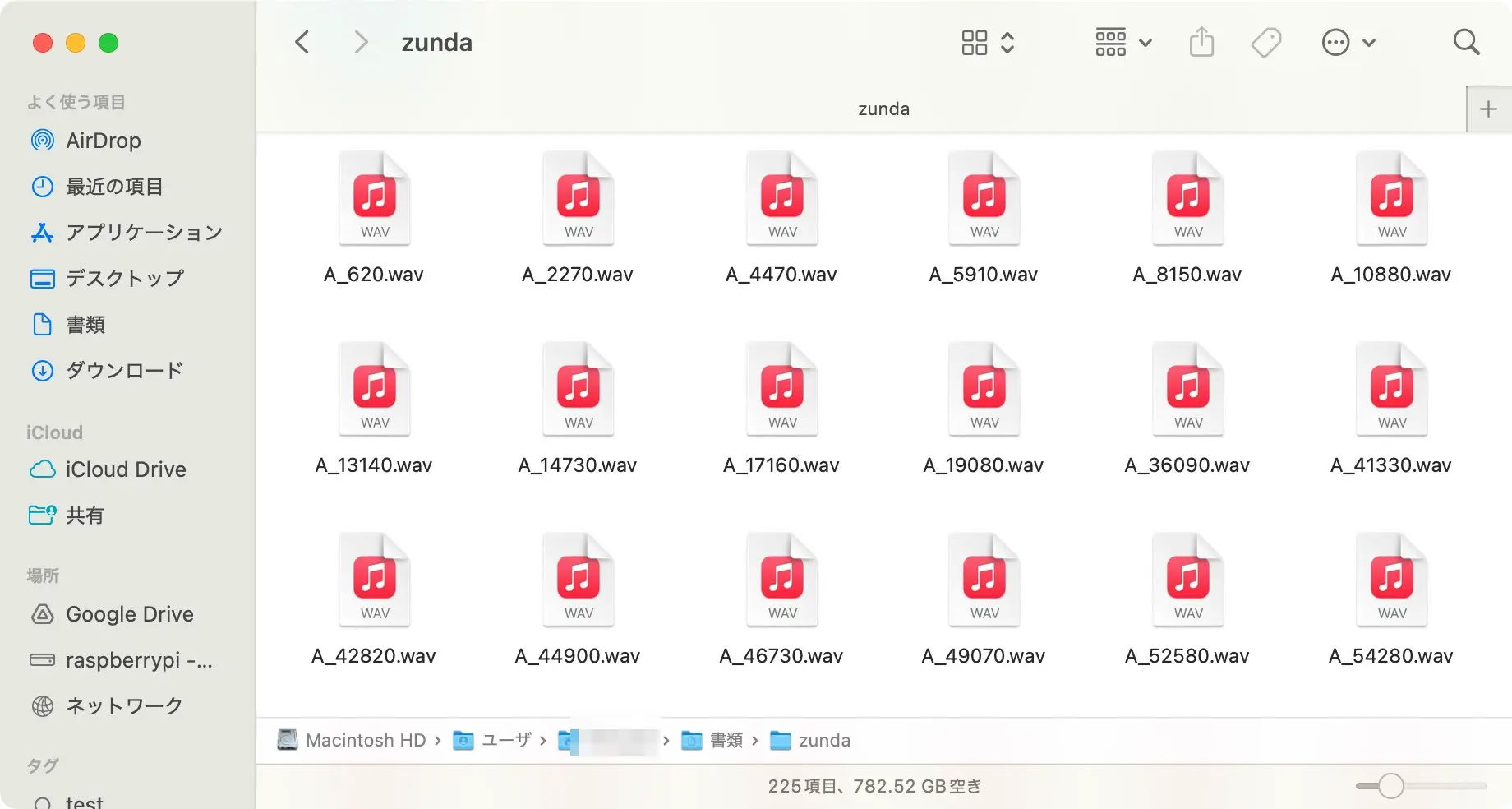
図:音声が一括で生成されました
図:moji.jsonにfile項目が追記されました
YMM4でアプローチしてる事例
似たような発想で音声概要のデータをもとにずんだもん音声に置き換えてYMM4で動画作成をチャレンジしている方がいらっしゃいます。YMM4にて、字幕追加やキャラクターのアクションなども付与しているので、自分の方法よりもかなり理想的な姿になっています。
喋り方の癖や感情表現などを全てコントロールできるので、この手法はYoutubeの新たなコンテンツの作成手法の1つにもなっていくのではないでしょうか?ただポン出しの動画をそのままアップしてるような手抜き動画は結局淘汰されちゃうと思うので、この辺りは緻密に作り込みは必要になってくると思います。

サンプル動画
少し音量を抑えすぎてマックスにしないと聞こえない・・・もうちょっとvolumeの値をあげておけばよかった・・・

