Puppeteerでログインページ内のPDFをダウンロードする
Puppeteerは非常に優れたChrome自動化のツールなのですが、ひとつ厄介なのが「PDFファイルのダウンロード」です。特に事務系の自動化を実現する場合、とあるサイトにログインして、請求日付を指定し、クリックをすると「新しいタブでPDFが表示される」といったパターンが結構遭遇します。
問題はこのURLを取得して、ページ内に要素を追加しクリックさせてダウンロード出来るのか?といったら出来ません(また、いわゆる名前を付けてリンク先を保存といったものも現在サポートされていません)。リンクをクリックすると、Chrome内でビューアとして開かれてしまい、ファイルのダウンロードが出来ないのです(サーバ側で.htaccessなどでダウンロードするように仕掛けている場合には別ですが)
そこで、今回このやっかいなPDFファイルのダウンロードを実現してみたいと思います。日経メディアマーケティングのサイトのPDFをダウンロードしてる事例になります。
目次
今回使用するモジュール
今回、Chromeのダウンロード機能を使わずに、requestモジュールにてファイルダウンロードを行わせるようにしています。また、取得したデータは完成品フォルダの中に直接fs.writeFileSyncにて指定のファイル名で生成してしまいます。request-promiseのインストールは以下のコマンドにて。
npm install --save request-promise
今回のダウンロード上の問題点
今回対象としているサイトでは、以下のような問題点があるため、そのまま素直にボタンクリックでダウンロードができません。また、ログインした内部にあるファイルを取得するため、cookieを使用してrequestで叩かなければなりません。
- PDFファイル直リンクをクリックしても、Chrome内部のビューアで開かれてしまいダウンロードが出来ない
- bufferで取得してfs.writeSyncで書き出そうとしても、PDFではないものが取得されるのでこの手も使えません。
- requestモジュールを使ってHTTPリクエストで取得する場合も、Cookieを使ったログインセッションを使う必要があります。
- 対象のPDFのファイルのURLは毎回変化します。
- 請求書一覧には過去のものが列挙されていますが、指定の月のものだけが必要です。
- requestモジュールのオプションで必要なレスポンスデータは、setRequestInterceptionで横取りさせる必要があります。
- 入力する指定月のファイル名を生成してあげるのが要件の1つ
ソースコード
冒頭部分
冒頭の部分は、今自分が手掛けてる自動化ではもはやテンプレ化させているコードです。生成先フォルダやChromeパスの取得などなど。
//使用するモジュール
const puppeteer = require('puppeteer-core');
const prompts = require("prompts");
var fs = require('fs');
const path = require("path");
var shell = require('child_process').exec;
const makeDir = require("make-dir");
const rp = require('request-promise');
//デスクトップのパスを取得
var dir_home = process.env[process.platform == "win32" ? "USERPROFILE" : "HOME"];
var deskpath = require("path").join(dir_home, "Desktop");
var dir_desktop = deskpath + "\\tmpman\\";
var subfolder = deskpath + "\\完成品\\";
//オープンするURL
var url = "https://wb.cdms.jp/nikkeimm/";
//Chromeのパスを取得(ユーザ権限インストール時)
const userHome = process.env[process.platform == "win32" ? "USERPROFILE" : "HOME"];
var kiteipath = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe";
var temppath = path.join(userHome, "AppData\\Local\\Google\\Chrome\\Application\\chrome.exe");
//chrome場所判定
if(fs.existsSync(kiteipath)){
var chromepath = kiteipath
console.log("プログラムフォルダにChromeみつかったよ");
}else{
if(fs.existsSync(temppath)){
var chromepath = temppath;
console.log("ユーザディレクトリにChrome見つかったよ");
}else{
console.log("chromeのインストールが必要です。");
//IEを起動してChromeのインストールを促す
shell('start "" "iexplore" "https://www.google.co.jp/chrome/"')
return;
}
}
//プロンプト表示
getprompt();
- グローバル変数でデスクトップのパスを取得しておきます。
- つづけて、getprompt()を実行してユーザの入力を受付待ちします。
- chromeはいつもの「C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe」ではなく、「C:\\Users\\ユーザー名\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe」となるため、ユーザ毎のパスを取得して、chromepathに格納する
プロンプト入力受付部分
//プロンプトを表示
async function getprompt(){
// 入力を待ち受ける内容
let question = [
{
type: "text",
name: "userid",
message: "ユーザIDを指定してください(例:XXXXXXXXX)"
},
{
type: 'password',
name: "password",
message: "パスワードを入力してください"
},
{
type: 'text',
name: "seikyu",
message: "請求月を入れてください(例:202003)"
},
];
// promptsの起動
let response = await prompts(question);
//回答を取得
var uid = String(response.userid);
var pw = String(response.password);
var seikyu = String(response.seikyu);
//一時フォルダを作成する
await makeDir(dir_desktop).then(path => {
makeDir(subfolder).then(path => {
//main関数に引き渡す
main(uid,pw,seikyu);
});
});
}
- promptsを使って、3つの質問を受け付けるようにします。
- useridとpassword、指定の年度月の3つを質問し、それぞれの形式で受け付けます。passwordを指定しておくと****と隠した状態で表示されるようになります。
- 取得した数値を引数にmain()を実行します。
- この段階で完成品フォルダをmakeDirにて作成してしまいます。
- promptsのtypeがnumberは数値入力なのですが、バグで5桁以上入れようとすると(特に0の連続)入力がクリアされてしまうので、今回はtextにしています。
Puppeteer部分
//ブラウザ操作メイン関数
async function main(uid,pw,seikyu) {
const browser = await puppeteer.launch({
headless: false,
executablePath: chromepath,
ignoreDefaultArgs: ["--guest",'--disable-extensions','--start-fullscreen','--incognito',],
slowMo:100,
});
//ブラウザのダウンロード先をすべて統一する
await browser.on('targetcreated', async () =>{
const pageList = await browser.pages();
pageList.forEach((page) => {
page._client.send('Page.setDownloadBehavior', {
behavior: 'allow',
downloadPath: dir_desktop,
});
});
});
//pageを定義
const page = await browser.newPage()
const navigationPromise = page.waitForNavigation()
//ログインページを開く
await page.goto(url)
await page.setViewport({ width: 1536, height: 714 })
await navigationPromise
//IDとパスワードを入力してログイン
await page.waitForSelector('.form-table #ctl00_ctl00_ctl00_body_BodyMain_TxtUserId')
await page.click('.form-table #ctl00_ctl00_ctl00_body_BodyMain_TxtUserId')
await page.waitForSelector('.form-table #ctl00_ctl00_ctl00_body_BodyMain_TxtUserId')
await page.click('.form-table #ctl00_ctl00_ctl00_body_BodyMain_TxtUserId')
await page.type('.form-table #ctl00_ctl00_ctl00_body_BodyMain_TxtUserId', '')
await page.type('.form-table #ctl00_ctl00_ctl00_body_BodyMain_TxtPassword', '')
await page.type('.form-table #ctl00_ctl00_ctl00_body_BodyMain_TxtUserId', uid)
await page.type('.form-table #ctl00_ctl00_ctl00_body_BodyMain_TxtPassword', pw)
await page.waitForSelector('#aspnetForm #ctl00_ctl00_ctl00_body_BodyMain_BtnLogin')
await page.click('#aspnetForm #ctl00_ctl00_ctl00_body_BodyMain_BtnLogin')
await navigationPromise
//検索条件指定(チェックボックスをオン)
await page.waitForSelector('.main #ctl00_ctl00_ctl00_body_BodyMain_chkShowInfo')
await page.click('.main #ctl00_ctl00_ctl00_body_BodyMain_chkShowInfo')
await navigationPromise
//ダウンロード対象の年度月を指定する
await page.waitForSelector('.main > .section > #ctl00_ctl00_ctl00_body_BodyMain_PnlSearchCondition > #ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition > tbody')
await page.click('.main > .section > #ctl00_ctl00_ctl00_body_BodyMain_PnlSearchCondition > #ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition > tbody')
await page.select('#ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition #ctl00_ctl00_ctl00_body_BodyMain_DDLChohyoName', '1')
await page.waitForSelector('#ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition #ctl00_ctl00_ctl00_body_BodyMain_DDLChohyoName')
await page.click('#ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition #ctl00_ctl00_ctl00_body_BodyMain_DDLChohyoName')
await page.waitForSelector('#ctl00_ctl00_ctl00_body_BodyMain_PnlSearchCondition > #ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition > tbody > #ctl00_ctl00_ctl00_body_BodyMain_TrKidokuMidoku > .srchCond_value')
await page.click('#ctl00_ctl00_ctl00_body_BodyMain_PnlSearchCondition > #ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition > tbody > #ctl00_ctl00_ctl00_body_BodyMain_TrKidokuMidoku > .srchCond_value')
await page.waitForSelector('#ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition #ctl00_ctl00_ctl00_body_BodyMain_CtrlKeyItem05From')
await page.click('#ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition #ctl00_ctl00_ctl00_body_BodyMain_CtrlKeyItem05From')
await page.type('#ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition #ctl00_ctl00_ctl00_body_BodyMain_CtrlKeyItem05From', seikyu)
await page.type('#ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition #ctl00_ctl00_ctl00_body_BodyMain_CtrlKeyItem05To', seikyu)
await page.waitForSelector('#ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition #ctl00_ctl00_ctl00_body_BodyMain_BtnSearch')
await page.click('#ctl00_ctl00_ctl00_body_BodyMain_tblSearchCondition #ctl00_ctl00_ctl00_body_BodyMain_BtnSearch')
await navigationPromise
//PDF閲覧をクリック
const newPagePromise = new Promise(x => page.once('popup', x));
await page.waitForSelector('.default_table #ctl00_ctl00_ctl00_body_BodyMain_ListViewSearchResultList_ctrl0_BtnBrowse')
await page.click('.default_table #ctl00_ctl00_ctl00_body_BodyMain_ListViewSearchResultList_ctrl0_BtnBrowse')
//ポップアップページ(PDF)のURLを取得する
const newPage = await newPagePromise;
var pdfurl = newPage.url();
const fileName = subfolder + seikyu + ".pdf"
- 今回はWindowsで実行してるので、executablePathはChromeがインストールされているパスを指定
- Page.setDownloadBehaviorにてChromeに対してダウンロード先フォルダを指定しています。今回はデスクトップを指定。
- PDFのページはポップアップで新しいタブで開かれる為、newPageにてそのurlを取得しておく。これをrequestで使用します。
- fileNameはこの段階で作成しておきます。年度月のpdfとしました。
requestでファイルをダウンロード
一番やっかいな問題点はここです。
//ページアクセス中のデータを横取り
await newPage.setRequestInterception(true);
//newPage.onはreloadよりも前に記述が必要です
newPage.on('request', async (request) => {
if (request.url().startsWith(pdfurl)) {
//リクエストオプション
options = {
method: request._method,
uri: request._url,
body: request._postData,
headers: request._headers,
encoding: "binary"
}
//クッキーを取得してオプションに追加
let cookies = await page.cookies();
options.headers.Cookie = cookies.map(ck => ck.name + '=' + ck.value).join(';');
//requestモジュールでPDF直リンクにダウンロード要求
rp(options).then(function (body) {
//完成品フォルダに直接バイナリファイル書き出し
fs.writeFileSync(fileName, body, "binary", (err) => { console.log(err) })
}).catch(err => {
console.log(err);
})
request.abort();
} else {
request.continue()
}
});
//ポップアップページをリロードして、newPage.onを作動させる
await newPage.reload();
//終了メッセージを表示
await newPage.close(); //タブを閉じる
const script = `window.alert('処理が完了しました')`;
await page.addScriptTag({ content: script });
//ブラウザを閉じる
await browser.close()
}
- ポップアップが表示された後にsetRequestInterceptionをnewPageに対してtrueでセットする。これで移行のhttp通信を横取り
- newPage.onイベントをまずは先に用意しておく。こうしておかないとreloadした時にページがフリーズしてしまいます。
- newPage.reload()にて、ポップアップされたPDFのURLをリロードします。
- newPage.onが発動すると、リロード時にリクエストされた内、必要なヘッダやリクエストボディの値をオプションに取得しておきます。
- page.cookies()にてログインセッションのクッキーを取得し、リクエストオプションに追加します。
- 最後にrequestモジュールでオプション付きでPDFの直リンクURLを叩く。ファイルがbodyで取得されるので、fs.writeSyncにて指定のフォルダに指定のファイル名で書き出します。
- 完了したら、newPageのタブを閉じ、alertを出してあげて終了。
社内プロキシーを超える
社内業務用として作成した場合、requestを使ってるとプロキシーで阻まれることがあります。ChromeはOSのプロキシ設定を使うので必要ないのですが、Node.jsの部分であるrequestモジュールは対策が必要になります。以下にその部分だけをピックアップします。
//requestモジュールにプロキシ設定を追加
var proxyuri = "ここにプロキシーアドレスとポート番号";
var proxy = rp.defaults({'proxy':proxyuri})
//rpで接続する。proxyはプロキシーサーバ使用時に使う
proxy(options).then(function (body) {
fs.writeFileSync(fileName, body, "binary", (err) => { console.log(err) })
sleep(5000);
var newname = choiceday + "日経請求書.pdf";
//完成品フォルダに移動
fs.copyFile(fileName, nendoman + "\\" + newname, (err) => {
if (err) throw err;
console.log('ファイルを移動しました');
});
//コマンドを組み立てて実行
var child = spawnSync('explorer.exe', [subfolder + choiceday] );
}).catch(err => {
console.log(err);
}).finally(()=>{
//一時フォルダ内のファイルを削除
fs.unlinkSync(fileName);
//tmpmanフォルダを削除
fs.rmdirSync(dir_desktop);
});
- 冒頭でrp.defaultにてプロキシーを使うように設定を追加。proxy変数に格納する
- proxyでアクセスさせるので、proxy(options).then(function (body) {としてrequestモジュールを呼び出し実行
- optionsにて、proxy: proxyuriを追加してもエラーになります。
- Node.js部分はOSのプロキシ設定をデフォルトで使うようになっていないのでこのような指定が必要になります。
Chromeの設定を変更してダウンロード
Puppeteer自体に右クリックで名前を付けて保存は2022年現在も装備はされていないのですが、Chrome自体には以下の場所に、PDFドキュメントを内蔵ビューアで開くのではなく、直接ダウンロードするという設定が増えています。
- chrome://settings/content/pdfDocumentsを入力して実行
- 「PDF をダウンロードする」にチェックを入れる
- クリックすると内蔵ビューアじゃなく、直接ダウンロードされるようになる
PuppeteerにはCDPSessionというクラスにChromeの各種設定を変更する手段が用意されています。ダウンロード先を変更するといったようなケースでも利用しています。
StackOverFlowにこのCDPSessionを使って上記のセッティングを一時的に変更して、リンクをクリックしたらダウンロードという仕組みを使う事でrequestモジュールやCookieを使わず単純ダウンロードを実現する手段が掲載されていました。コードは以下のようなものになります。
//Chromeのフルパス
var chromepath = '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome';
//開くページ
var startpage = 'https://officeforest.org/test/test.html';
//デスクトップのパスを取得
var dir_home = process.env[process.platform == "win32" ? "USERPROFILE" : "HOME"];
var dir_desktop = require("path").join(dir_home, "Desktop");
//ライブラリのロード
const puppeteer = require('puppeteer-core');
(async () => {
//puppeteer起動
const browser = await puppeteer.launch({
headless: false,
executablePath: chromepath,
ignoreDefaultArgs: ["--guest",'--disable-extensions','--start-fullscreen','--incognito',],
slowMo:100,
});
//新しいページを追加
const page = await browser.newPage();
const navigationPromise = page.waitForNavigation()
//CDPSessionを作成
const client = await page.target().createCDPSession();
//ダウンロード先をデスクトップに変更する
await client.send('Browser.setDownloadBehavior', {
behavior:"allow",
downloadPath: dir_desktop
});
//PDFを強制ダウンロードする設定を有効化
await client.send('Fetch.enable', {
patterns: [
{
urlPattern: '*',
requestStage: 'Response',
},
],
});
await client.on('Fetch.requestPaused', async (reqEvent) => {
const { requestId } = reqEvent;
let responseHeaders = reqEvent.responseHeaders || [];
let contentType = '';
for (let elements of responseHeaders) {
if (elements.name.toLowerCase() === 'content-type') {
contentType = elements.value;
}
}
//PDFとXMLは対象とする
if (contentType.endsWith('pdf') || contentType.endsWith('xml')) {
//content-disposition: attachmentヘッダーを追加する
responseHeaders.push({
name: 'content-disposition',
value: 'attachment',
});
const responseObj = await client.send('Fetch.getResponseBody', {
requestId,
});
await client.send('Fetch.fulfillRequest', {
requestId,
responseCode: 200,
responseHeaders,
body: responseObj.body,
});
} else {
await client.send('Fetch.continueRequest', { requestId });
}
});
//ウェブページを開く
await page.goto(startpage)
await page.setViewport({ width: 1536, height: 714 })
await navigationPromise
//リンクをクリックする
await page.waitForSelector('#kiui')
await page.click('#kiui')
//ウェイト
await navigationPromise
//送り込んだ設定を無効化する
await client.send('Fetch.disable');
//ブラウザを閉じる
await browser.close();
})();
- 正確には上記の場合、PDFとXMLファイルを開くのではなくダウンロードするという設定が送られています。
- 最後にFetch.disableにて設定を無効化して元に戻しています。
実際にテストサイトを開きリンクをクリックしただけで、何の設定もなくPDFをダウンロードできました。もちろん手動だと内蔵ビューアで開かれます。
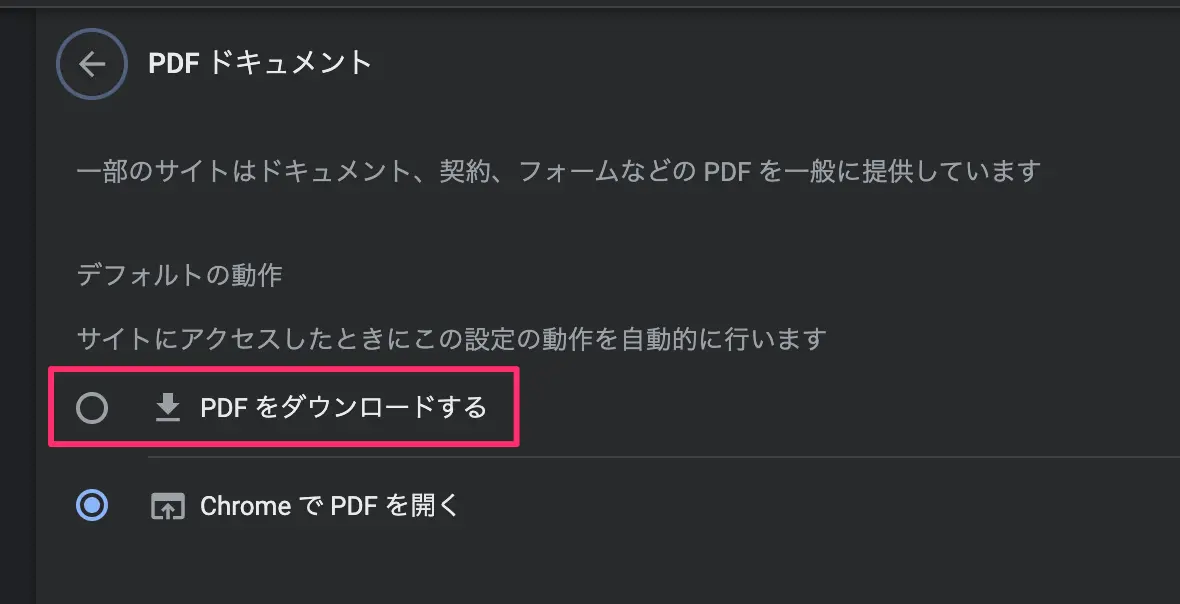
図:この設定をコードから一時的に有効化する
単一実行ファイルを作成する
Node.js 18よりSingle executable applicationsという機能が装備され、標準で単独実行ファイルが作成できるようになりました。結果pkgはプロジェクト終了となっています。よって、以下のエントリーの単一実行ファイルを作成するを参考に、Node18以降はexeファイルを作成することが可能です。
関連リンク
- Question: How do I get puppeteer to download a file?
- Using setRequestInterception causing timeouts on some urls
- Open Puppeteer with specific configuration (download PDF instead of PDF viewer)
- ChromeでPDFを開きたくない! 常に内蔵ビューワーを使わず直接ダウンロードする方法
- Puppeteer popup window and multiple tabs
- window.open is not doing anything in headless mode for a URL that is a PDF.
- Puppeteerのevaluateに引数
- ダウンロード用のリンクを指定する - TAG INDEX
- How to save pdf in proper encoding via nodejs
- Puppeteerでファイルダウンロード
- Download a file with Headless Chrome, Node.js and Puppeteer
- Refer #1248. How to download the PDF in headful mode
- request-promise html request behind proxy
- Save PDF to File using puppeteer
- Puppeteerでファイルをダウンロードする2022
- Content-Typeとattachmentを指定してファイルダウンロードする方法[PHP]
