Puppeteerでウェブサイトをスクレイピング
PhantomJSが消えた今(クラウドサービスは生きてる)、ウェブの情報スクレイピングする手段としては、SeleniumとPuppeteerくらいかなぁというのも、最近のウェブは動的に情報を生成しているので、例えばGoogle Apps Scriptで拾いに行っても、JavaScript実行前の骨組みしか取得できないケースがあったりします。
しかし、PuppeteerはただChromeの操作を自動化するだけじゃなく、ウェブスクレイピングでも力を発揮します。ということで、今回世間を騒がせているマスク情報を手に入れるべく、対象のページの商品情報を取得してみたいと思います。実際には、このコードに更にIFTTTのWebhooksを使ってLINEに通知したり、TeamsのIncoming Webhookを叩いたり、また「アイマスク」などのノイズ情報も除去したり、Node-Cronで定期的に自動実行させてやる必要があるので、こんな事も出来るよってサンプルです。
今回使用するモジュール
今回はスクレイピングさせる為の補助として、cheerioと呼ばれるNode.js上でjQueryのようにDOM操作をする事のできるモジュールを入れています。
また、macOS用に作っているので、executablePathは/Applications/Google Chrome.app/Contents/MacOS/Google Chromeとなります。
※スクレイピングは相手のサーバに負荷を掛ける手法です。よって、非常に短いスパンで連続アクセスするような行為はNGです。
事前準備
セレクターの取得
今回のPuppeteerは自動操作というよりは、ウェブスクレイピングの処理なのでほぼほぼNode.jsでコーディングする形になります。しかし、ページのどこの部分をスクレイピングするか?ということで、はじめにセレクターを渡してあげる必要があります(でないと全体取得になってしまう)
このセレクタですが、Chromeデベロッパーツールで簡単に取得が可能です。以下の手順でページの対象部分のセレクタを取得しておきます。
- Chromeで対象のページを表示する
- 商品群の情報が出てるエリアを右クリック⇒検証でデベロッパーツールが起動
- 商品エリアの部分が今回の取得対象となる部分。
- 3.を右クリック⇒Copy⇒Copy Selectorを選択
- 今回のコードのselector変数に入れる。これで完了。
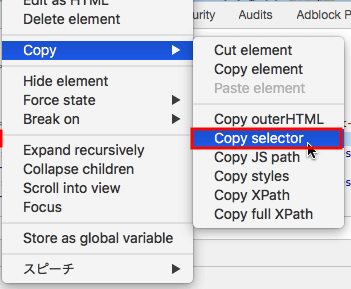
図:セレクタの取得は意外と簡単
モジュールのインストール
これはとても簡単。
- フォルダを作成し、npm init -yを実行
- 以下のコマンドでモジュールをインストール
- index.jsを作成して、node index.jsで実行。これだけ
npm install cheerio npm i puppeteer
ソースコード
スクレイピングするコード
"use strict"
const puppeteer = require('puppeteer-core');
const path = require("path");
const cheerio = require('cheerio');
//Chromeのパスを取得
var chromepath = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome";
//puppeteer発動
main();
//ブラウザ操作メイン関数
async function main() {
const browser = await puppeteer.launch({
headless: false,
executablePath: chromepath,
ignoreDefaultArgs: ["--guest",'--disable-extensions','--start-fullscreen','--incognito',],
slowMo:200,
});
//pageを定義
const page = await browser.newPage()
const navigationPromise = page.waitForNavigation()
//対象のウェブサイトを開く
var url = "ここに対象のURLを入れる"
await page.goto(url, { waitUntil: 'domcontentloaded' }); // domを読み込むまで待機
await page.setViewport({ width: 1536, height: 714 })
await navigationPromise
//メイン部分を取得(Chrome Dev Toolでセレクターをそのまんま貼り付け)
var selector = "ここに対象の取得しておいたセレクターを入れる";
//HTMLデータを取得
var html = await page.$eval(selector, item => {
return item.innerHTML;
});
//cheerioに食わせる
const $ = await cheerio.load(html)
//データ用配列
var amaarray = [];
//data-indexの値を拾っていく
await $('.s-result-item').each((index, element) => {
//配列を用意する
var dataman = {};
// 指定の要素内のdata-index属性の値を取得する
const dataindex = $(element).data("index");
dataman.dataindex = dataindex;
//商品の価格を取得
const itemPrice = $(element).find('商品価格のClassを指定').text();
dataman.itemPrice = itemPrice;
//品名を取得
const itemName = $(element).find('商品名が入ってるClassを指定').text();
dataman.itemName = itemName;
//商品のURL取得してみたり
const itemLink = $(element).find('URLが入ってるclassを指定').attr('href');
let amaurl = "ここにドメイン名を入れる" + itemLink;
dataman.itemLink = amaurl;
//スターを取得する
const itemStar = $(element).find('スター情報のClassを指定').text();
dataman.itemStar = itemStar;
//ポイントを取得する
const itemPoint = $(element).find('ポイント情報のclassを指定').children('span').text();
dataman.itemPoint = itemPoint;
//配列にぶっこむ
amaarray.push(dataman);
});
//データを出力する
await console.log(amaarray)
//ブラウザを閉じる
await browser.close()
}
- 今回はmacOS上で動かしてるので、executablePathは異なります。
- ロードするURLは検索結果画面からのスタートになります。
- selector変数には前項の事前準備で取得した対象のセレクタを指定します。
- html変数にawait page.$evalにてまずは、セレクター内のHTMLを取得させておきます。
- 取得したHTMLはそのままでは扱いが面倒なので、cheerioに渡してjQuery風にDOM操作出来るようにしておきます。
- 最初のクラス以下をforEachで回して各商品の情報を取得させていきますので、配列等を用意しておく
- その中に子要素や孫要素が入ってるのですが1個ずつ掘っていくのは骨が折れるので、class指定でfindで探させます。
- URLの場合には、hrefをattrにて取得するようにします。
- これらの情報は用意しておいた{}にkey名と共に突っ込んでいく
- 最後に配列に情報の塊をぶっこむ。
- 相手のウェブの仕様が変われば作り直しになるのは、ウェブスクレイピングの宿命
関連リンク
- IFTTT(イフト)で、Webhooksを使用した簡単に自動でLineにメッセージを送信する方法
- 【Vue.js】Webhookを使ってMicrosoft Teamsにメッセージを送る
- Puppeteerを使って簡単にWebスクレイピングする
- PuppeteerでCookieを使ってログインする方法
- PuppeteerでKindleのハイライトを自動取得してみた
- PuppeteerでAmazonアフィリエイトのレポートを取得する
- Puppeteerでテキストデータを取得する(スクレイピング)
- Cheerio で Web ページをスクレイピングする
- cheerioの主なAPI(1)属性
- cheerioを使ってスクレイピングする時に大文字のタグや属性が使われている場合の対処
- puppeteerで駿河屋の商品情報を取得する
- 【jQuery入門】find()で子要素を取得する手法まとめ!
- data属性の値が取得できない
- jQueryのeach()で複数の要素、配列、オブジェクトをループ処理
- 複数クラスがある場合のセレクタの指定方法
- puppeteerで最初以外の要素を指定するにはどうすればいいですか?
- Google Apps Script(GAS)を利用したスクレイピングを使うメリットと利用方法まとめ
- Amazonの商品を注文するLINEbotを作ろうとしてうまく行かなかった話
