Google SpreadsheetでBigQueryを操る最初の一歩【GAS】
Google Spreadsheetは2024年現在、2022年の上限引き上げによって1000万セルまで上限が引き上げられています。これにより多くのデータを格納することが出来るようになり、Google Apps Scriptなどを使った分析ツールを作る上でも相当量のデータを蓄えておくことが可能になり可能性が広がりました。
しかし、データ量が増えてもスプレッドシートではSQL言語が使えるわけじゃなく、またアクセス速度も遅い。上限が拡大したといっても、年間10万レコード(列数30列)といったデータでは、わずか3年分しかプールしておく事が出来ません。この問題を解決する手段がBigQueryです。今回はスプレッドシートから扱ってみたいと思います。
目次
今回利用するサービス
- BigQuery
- コネクテッドシート
- BigQuery分析 - Google Spreadsheet
BigQueryはGoogle Workspaceのサービスではなく、Google Cloudのサービスとなります。よって、利用するためには事前にGCP側で利用できる状況にしておく必要性と課金サービスであるため課金のアカウント整備も済ませておく必要があります。
Googleスプレッドシートからは専用の接続用データコネクタの機能が用意されており、利用する前にどれくらいのコストが掛かるのか?またそのためにどんな準備をしておくべきなのか?といった事前準備がとても大切です(でないと、課金地獄に陥る可能性があります)
今回は医薬品の卸からの仕入れデータを分析するという想定で使い方をまとめてみたいと思います。
※コネクテッドシート機能は2022年5月より全プランで利用が可能になりました。
BigQueryとは?
データ分析用のDWH
通常のデータベースは、日々様々なデータを蓄積し現業(販売管理や経理、人事などなど)するためのソフトウェアでありデータの蓄積場所です。故に日々小さなデータの入出力が頻繁にあり、またデータの分析などにも使われることがあります。
一方、BigQueryはデータウェアハウスと呼ばれる「主に分析を行うためのビッグデータを蓄えて分析に利用する」という明確な目的の為にある、どちらかというとマーケティングやコスト分析など経営層向けのソフトウェアとなります。
よって、この機能を利用する人というのは企業の中でも割と限られてくると思います。通常のRDBでも分析はこれまでも普通に行われてきていますが、そこには大きな機能面での違いがあります。となると、大企業のビッグデータ解析にしか使われず、中小規模の企業では不要?というのは早計で、その解析する目的によっては、人間のカンや経験に頼るのではなく、問題点の洗い出しやコスト削減の根っこを見つける為に大いに役に立つツールです。
通常のRDBとはちょっと異なる
BigQueryは通常のRDBとはちょっと異なります。一見するとデータの保存場所という点では似ているのですが、問題はその処理の中身にあります。Cloud SQL(MySQL)を基準に比較してみようと思います。
- 読み取り速度に関しては、BigQueryのほうが断然早い
- 書き込み速度に関しては、BigQueryは遅い
- 集計速度に関しては、BigQueryは非常に早い
- 処理量に関しては、BigQueryのほうが断然高い
書き込みの速度が遅いため、日々の業務用のDBとして使うには向かない反面、解析に掛かる処理周りが断然早いため、この点が大きな差となっています。日々利用するCloud SQL⇒BigQueryへ差分のデータを転送する為に、Datastream for BigQueryなども合わせて利用すると手間が減り良いかもしれません。
ただ、1つ大きな特徴として、BigQueryはデータベース内の全てのデータを「フルスキャンする」という特徴があり、RDBのようにWhere条件をつけたからと言って速度が早くなったり、課金額が変動することがありません。逆を言えばWhere条件でフィルタしても全量データ分だけ課金は発生するため、雑な使い方の場合、コスト面でかなり問題になる可能性があります。
コストが結構シビア
高速に大量のデータを処理できる反面、フルスキャンが故に大量の列がある莫大なデータ量を毎回リクエストしていると、前述の通り課金額も莫大になってしまい、分析の為とは言え必要以上のコスト支払いをするとなるとシステムとしては少々困った存在になってしまいます。
後述の利用料金にもあるように、データは従量課金であるためはじめの一歩の段階でどう設計するか?でだいぶ変わってきてしまいます。設計をする上で重要なポイントは
- BigQueryにインポートするデータの列は、本当に必要なものだけを用意しておく。保存するストレージでも課金されるため。(インポート作業自体は無料だけれど、保存した場合はストレージに対して課金が発生する)
- BigQueryからのデータ抽出(SELECT文)のクエリ実行に於いて、select * のようなアスタリスクで全カラム抽出といったような読み出し方ではなく、列を限定して呼び出すこと(クエリ辺りの処理量を減らせればその分だけ課金額も低くなる):WhereやLimitで絞っても課金額は低くならない。
- BigQueryのバックアップはCloud StorageなどにCSVなどの形で出力しておく。テーブルのまま置いておくと課金が継続してしまう。
- 設計や解析以外の理由(費用見積もり等)でデータを見たい場合には、クエリを実行するのではなく、プレビュー機能を使ってテストする(プレビュー自体は課金されない)
- BigQueryをお試しする場合には、毎月10GBまでのストレージ&1TBまでクエリ処理枠を使うサンドボックス環境でテストを行う。
- BigQueryは同じクエリを投げた場合には、事前に実行されたキャッシュから払い出されます。但しこのキャッシュは約24時間が期限です。同じデータで変動がなく、集計された結果などを複数名で後日閲覧といったケースが多いならば、Google Spreadsheetに吐き出して於いてそれを分析すると良いでしょう。
- BigQueryは90日間変更がないテーブルは、長期保存という枠組みになり保存コストが半分になります。頻繁にテーブルデータを書き換えるのではなく、一度確定で出力したらそのテーブルは見るだけのものとし、出力先としては使わないほうがコスト面では優れています。
- BigQueryでデータを操作する前に、パーティションやクラスタリングというテクニックを使って参照範囲を絞りつつパフォーマンスが向上するかもしれません。特に日付別などでパーティションを区切っておくと良いです。有効期限がデフォルトで60日で設定されているので要注意。
- BigQueryの列のデータ型によって入れられるデータが異なりますが、無駄に大きなデータ型を指定しておくとクエリ時にそれだけ無駄に課金額が増えることになるのでなるべく小さいデータ型にしておく。
- BigQueryを使う前にかならず想定外の費用の計上を防ぐ為に、Cloud Billingにて予算枠上限とアラートを設定し、超えないように監視する体制を作っておきましょう(カスタムコスト管理を併用し、ユーザ辺りの使用量を制限を併用するのも良いでしょう。)
利用方法と料金
BigQueryの料金体系
料金体系は大きく2つ。ストレージ料金とクエリ実行などのデータ操作料金です。
ストレージ料金
ストレージ料金は毎月10GBまでは無料枠が設定されています。それ以上になった場合に課金されますが、2種類の区分が用意されています(無圧縮の論理ストレージの場合)。
- アクティブストレージ:90日間に変更のあったテーブルやパーティション($0.02/1GB)
- 長期保存ストレージ:90日間変更のなかったテーブルやパーティション($0.01/1GB)
また、上記のストレージにそれぞれPhysical Storage(物理ストレージ)というのものがあり、データ圧縮されているの場合のストレージとなり、それぞれ2倍の料金が設定されています。これはどちらを選ぶか?というオプションとなっており、単価だけ見ると高く設定されてるように見えても、実際には数倍に圧縮されてる為、GB単位辺りは安くなります。
必ずしも物理ストレージのほうが有利ということではないものの、殆どのケースでは物理ストレージのほうがお得になるようです。
データ操作料金
データ操作、つまりクエリ辺りの従量課金で、毎月1TBまでの無料枠が設定されています。それ以上になった場合に課金されますが、2種類の区分が用意されています。
- オンデマンド:スポットで処理した都度データ量に応じて課金($6.25/TB)
- 定額料金:あらかじめスロットという単位で購入しておき利用する課金(月次の場合は、$2400/100スロット/1ヶ月)
オンデマンドは最大2000スロットを使って演算をしてるそうな。対して月額料金は自分でスロットを予約して指定期間内で使うタイプとなるため、購入するスロット数によって処理能力も変わる。年次契約やフレキシブルでまた料金が変わってくるのと、指定期間が終わらないとキャンセルやプラン変更が出来ない制約がある。
また、スロット枠は他の組織やリージョンと共有することはできない。
利用するシーンや使い方によってオンデマンドが良いのか?それとも定額料金で必要な分のスロットを購入したほうが良いのか?が分かれるため、一概にどちらが良いということではなく、Slot Recommenderなどで一度オンデマンドで分析してみて、定額料金のほうがよいのかどうか?を判定するのが望ましいです。モニタリングについては、管理リソースグラフなどのツールを使って行います。
モニタリングを開いて、リージョンを選択すると現在までの処理されたクエリの量がわかるようになっています。
BigQueryを利用できるようにする
BigQueryを使うに当たっては設定や事前準備が必要ですが、課金アカウントを利用せずに始めることも可能です。(前述に出ていたサンドボックス環境)。公式の入門ガイドはこちらに掲載されています。
今回はサンドボックスでまず作ってみると良いでしょう。既に課金アカウントがある場合は、別のプロジェクトを作成してからサンドボックスでテストするのが良い選択肢です。
データセットを作成する
今回新規にプロジェクトを作成してからBigQuery Studioにアクセスしています。そのため、サンドボックス環境となっています。課金する場合には右上のアップグレードをクリックして、料金プランを選択する必要があります。
新規プロジェクトにてBigQuery Studioにアクセスしたら以下の手順でデータセット等を作成します。
- エクスプローラ内にあるプロジェクトの名称横にある「︙」をクリックし、データセットを作成をクリック
- 右サイドバーが開くので、データセットIDに適当な名称を入れ(今回はBigQueryという名前にしました。)、ロケーションタイプを選択後にリージョンを選択します。(この時にしかセット出来ない)。今回はasia-northeast1(東京)を選んでみました。
- テーブルの有効期限を設定できます。何も入れない場合無期限となり、期限をセットした場合その日をもってテーブルが自動削除されます。
- データセット作成をクリックする
- 次に作成したデータセット内にテーブルを作成します。SQLで作成したり、ローカルデータを読み込ませることも可能です。
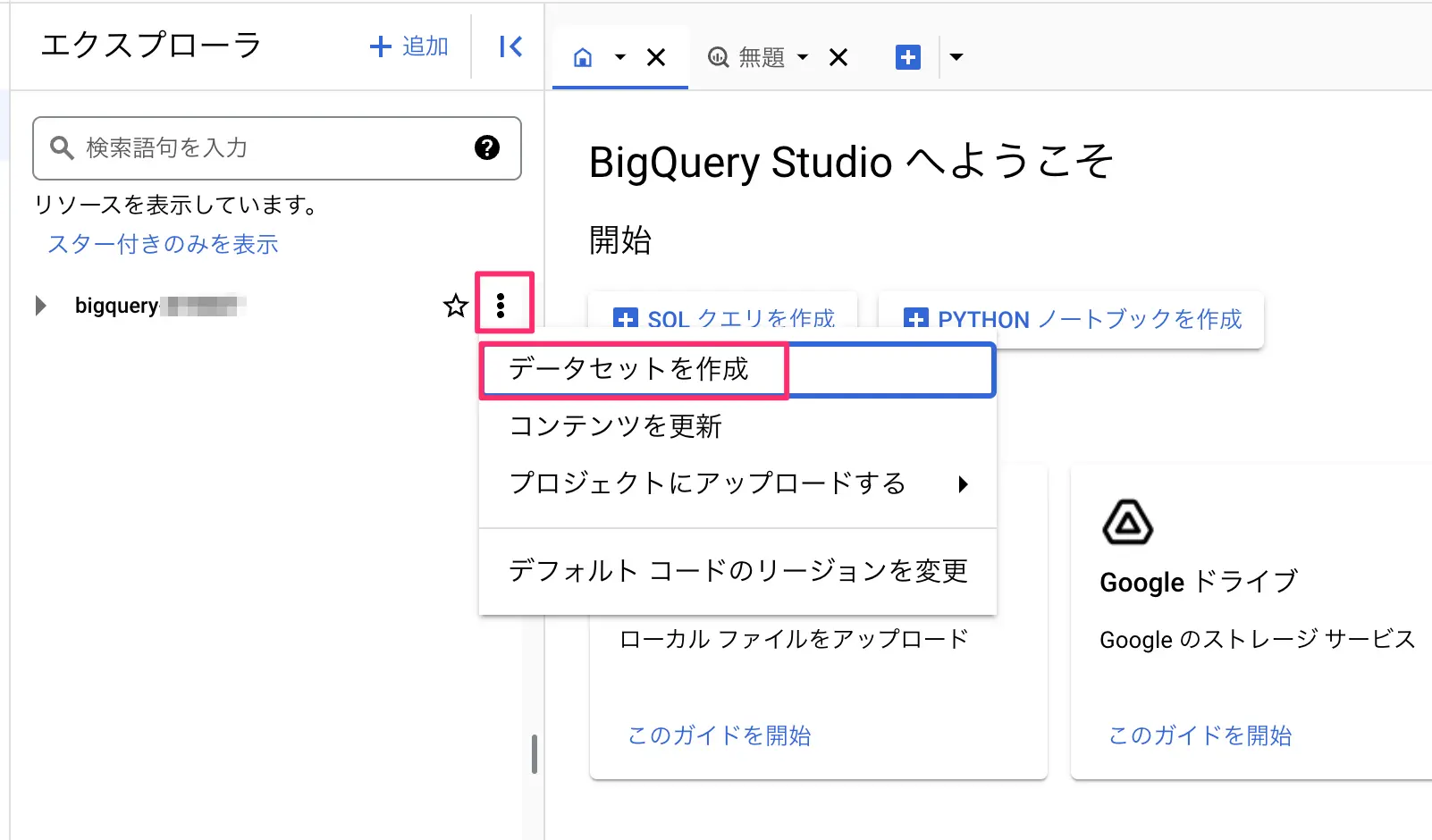
図:データセットの新規作成
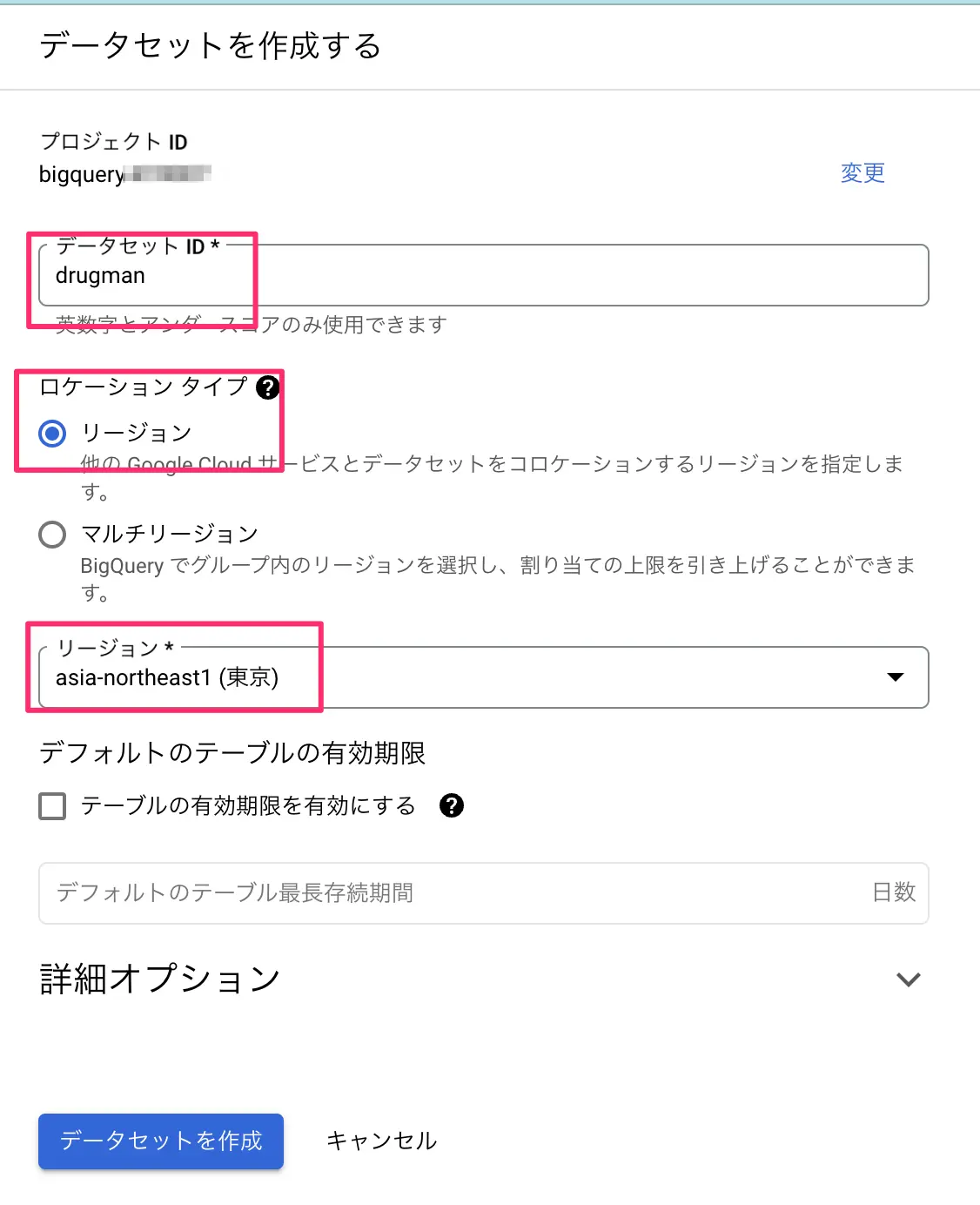
図:データセットの設定中
テーブルを手動で作成する
CSV(Shift-JISは非サポート)やGoogle Spreadsheetなどから初期データも含めてテーブルを作成できますが、今回は敢えて手動でテーブルを作成しようと思います。
- 左サイドバーのエクスプローラに於いて先ほど作成したデータセット横の「︙」をクリックして、テーブルを作成をクリックします。
- テーブルに適当な名前を入力する(この回はdruglistとしました)
- スキーマにて列を定義します。フィールドを編集をクリックします。
- 今回は医薬品卸データに於いて分析で使う必要な列を作ってみました。
jancode : JANコード(INTEGER) gs1code : GS1コード(INTEGER) oroshi : 卸名(STRING) unit : 購入単位数量(INTEGER) price : 購入単位金額合計(INTEGER) hospname : 納入先病院名(STRING) drugname : 医薬品名(STRING) transdate : 取引月(INTEGER)
- パーティションとクラスタの設定にて、「取り込み時間により分割」を選択
- パーティショニングのタイプは業務にもよりますが、今回は卸データということなので「1ヶ月ごと」を選択しました。
- 最後にテーブル作成をクリックする
これで空のテーブルが作成されました。Create Table文ならば以下のような感じになります。型に互換性が無いと後から容易に型変換が出来ないので要注意。pj_mysetがデータセット、mytableがテーブル名になります。
CREATE TABLE pj_myset.mytable ( `jancode` INT64, `gs1code` INT64, `oroshi` STRING, `unit` INT64, `price` INT64, `hospname` STRING, `drugname` STRING, `transdate` STRING, );kata
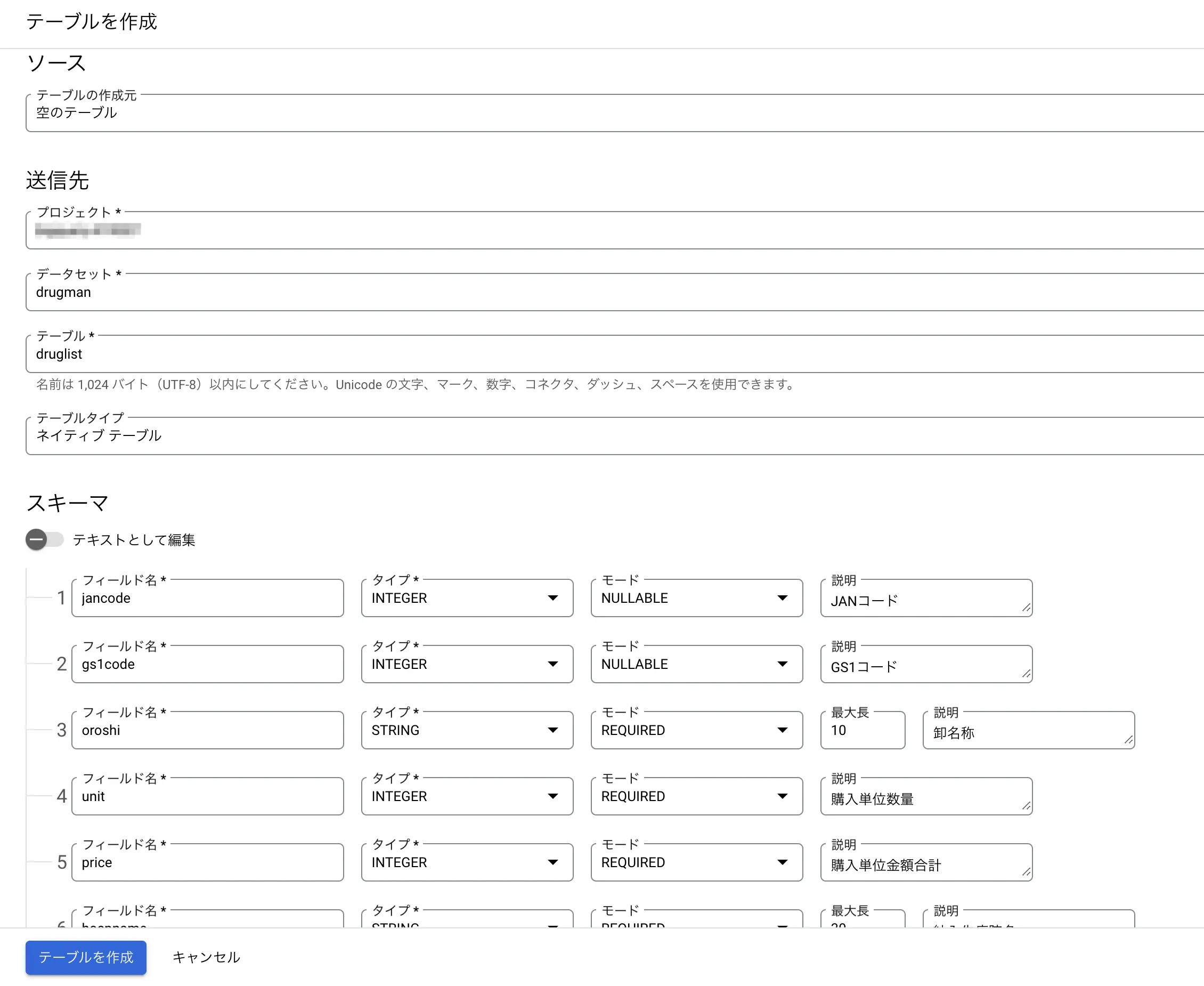
図:テーブル作成画面
STRING型の規則
何でも入れられそうなSTRING型ですが、MySQLなどと違って結構規則があります。
- カンマ区切り文字は入れられません
- 改行コードはNGです。スプレッドシートでセル内改行してる場合は注意。
故にこれらの文字については、変換や削除するようなコードが必要になります。
//カンマ区切りを置き換える
function checkcomma(checkvalue){
let tempcheck = String(checkvalue);
if(tempcheck == "" || tempcheck == undefined){
return null;
}
tempcheck = tempcheck.replace(",", "|");
return tempcheck;
}
//改行コードを削除する
function deletelinecode(checkvalue){
let templine = String(checkvalue)
templine = templine.replace(/(\r\n|\r|\n)/g, "");
return templine;
}
DATE型の規則
日付を入れるDATE型という列を用意した場合、そこには規則があります。
- YYYY-MM-DDというハイフンで区切った日付の形式だけ入れることが可能です。
- nullは入れることは出来ますが、""といった空文字では入れることは出来ません。
日付のデータを変換する場合には、上記の点を注意する必要があります。GASで変換する場合は以下のような関数を用意して変換してあげます。
//現在日付データを整形して返す関数(YYYY-MM-DDの形式でなければならない)
function getDateman(datekun){
//値が空の場合は空で返す
if(datekun == undefined || datekun == ""){
return null; //nullじゃないとエラーになる
}
//日付を生成
let newdate = new Date(datekun);
let year = newdate.getFullYear();
let month = paddingZero(newdate.getMonth() + 1);
let date = paddingZero(newdate.getDate());
//日付時刻を成形して返す
let strDate = year + "-" + month + "-" + date;
return strDate;
}
//頭に0をつける
let paddingZero = function(n) {
return (n < 10) ? '0' + n : n;
};
Interval型は手動では作れない
BigQueryの型としてTIME型があるのですが、最大24時間までの値しか格納できません。ソレ以上の場合にはString型にでもして、ローカルで使う側で型変換する必要があります。
これとは別にInterval型という型があるのですが、これが一定の期間という値を格納するちょっと特殊な型です。2021年に追加されたもので、型に入れる値もちょっと特殊でこちらにドキュメントがありますが、例えばH:M:Sだけを見た場合には、
- 0-0 0 11:30:1.25という値で、11時間30分1秒の25ミリセカンドという指定になります。
- 但し24時間を超えるならば、0-0 2 11:00:00という指定で、2日と11時間という指定となり入れることが可能です。
- 元のHH:MM:SSの値が24時間を超える場合には、日まで含めて計算して変換してからフィールドに入れる必要があります。
故にちょっとスプシやGASなどからは扱うのが厄介な数値になっています(入ってる数値を戻すのは楽なんですけれどね)。また、この型なんですが、Google CloudのConsoleにおいてUI上からは型指定出来ません。利用する場合にはクエリを構築してテーブルを作る時に型指定として追加可能です。例えば以下のようなクエリを実行します。
CREATE TABLE your_dataset.your_table (
`ID` INT64,
`名前` STRING,
`期間` INTERVAL,
);
データの追加
ここまでで、BigQueryのデータの入れ物までを準備が完了しました。しかしデータが空っぽの状態です。ここに毎月データを追記していくことになりますが、データの追記がちょっと分かりにくいです。また、毎回GCPの画面を開いて手動でファイルを指定して取り込むというのも煩雑です。ということでデータの追記の体制を作ります。
なお、BigQueryはその性質上、通常のDBにあるようなユニークキーの制約が無いので、間違えても重複してデータがインサートされてしまいます。慎重にデータの追加作業を行う必要性があります。
手動でインポート
手動でファイルをインポートする手法ですが、CSVやJSONといったデータに対応していても、Googleスプレッドシートには対応していません。また、GCPの画面上から行う必要があるため、毎月の作業としてはちょっと煩雑です。
以下の手順でインポートを行います。
- 左サイドバーのエクスプローラに於いて先ほど作成したデータセット横の「︙」をクリックして、テーブルを作成をクリックします。
- テーブルの作成元をアップロードに変更する
- ファイルの参照で、CSVファイルを指定する
- ファイル形式ではCSVを選択する
- テーブルでは、既に作成済みのテーブル名を入力する
- スキーマはテーブル作成時と同じ値をセットする
- パーティションとクラスタの設定はテーブル作成時と同じ値をセットする
- 詳細オプションを開く
- 書き込み設定にて、「テーブルに追加する」を選択する
- CSVにヘッダー行があるならばスキップするヘッダー行に1といった値をいれてヘッダーをスルーする
- テーブル作成をクリックする
すると既存のテーブルに対して、CSVデータをスキーマに従って追記でインサートしてくれます。しかし、毎回これを行うのはかなりの手間です。

図:CSVを手動インポートするオプション
スプレッドシート連携でインポート
卸データがスプレッドシートとしてGoogle Driveに存在するならば、そのまま活用したほうが同じ手動でインポートよりも遥かに手間がありません。毎月データをスプレッドシートに用意して、インサート用のクエリを実行するだけで、対象のテーブルに入れることが可能です。
以下の手順で対象のスプレッドシートを外部テーブルとして登録します。
- 左サイドバーのエクスプローラに於いて先ほど作成したデータセット横の「︙」をクリックして、テーブルを作成をクリックします。
- テーブルの作成元をドライブに変更する
- GoogleスプレッドシートのURLをドライブのURIに入れる(例:https://docs.google.com/spreadsheets/d/xxxx/)
- ファイルの形式を「Googleスプレッドシート」に変更する
- シート範囲はオプションですが、ここでは「シート名」を入力します。(シート名!A1:G100といったような指定も可能)
- テーブルは新規に登録するので適当な名前を入力する(今回はbasedataと命名しました。)
- スキーマは自動検出とします。
- 詳細オプションを開く
- スプレッドシートにヘッダー行があるならばスキップするヘッダー行に1といった値をいれてヘッダーをスルーする
- テーブル作成をクリックする
これで、外部テーブルとしてテーブルが追加されました。Accessのリンクテーブルのような仕組みですので、スプレッドシート側を編集して、BigQuery側でSELECT文で中身を見てみると、きちんと更新されています(当たり前ですがアクセス権がないとエラーになります)
ただこれではインサート先のdruglistテーブルに値が追加されているわけじゃありません。そこで、以下の手順でクエリを実行して、インサートします。但しこの処理は「課金アカウントでないとクエリが実行できない」とエラーが出ます。サンドボックス環境では実行が出来ないようです。
- basedataのテーブル横の「︙」をクリックして、クエリをクリック
- 以下のようなSELECT文の入ったクエリが出てくるので、それに加えて以下のようなクエリを構築する
INSERT `xxxx.BigQuery.druglist` (jancode,gs1code,oroshi,unit,price,hospname,drugname,transdate) SELECT * FROM `xxxx.BigQuery.basedata`
BigQueryデータセットの中のbasedataをSELECTで全部抜き出し、INSERTでdruglistに追加する構文です。druglist側は列を指定する必要性があります。
- クエリを保存をクリックして名前をつけておき、アクセス範囲を指定する(次回以降はこのクエリを叩くだけでオッケー)
実際にクエリを実行して、druglistのテーブルの「プレビュー」を見てみたらきちんとデータが挿入されていました。ただすぐにプレビューを開いてもデータが無いと言われ一度リロードしたら出てきました。
なお、どれくらいのデータ量が処理されたのか?また課金対象バイト数などは、クエリタブの下の方にあるジョブ履歴から対象のクエリ実行ジョブ履歴をクリックすると確認することが出来ます。
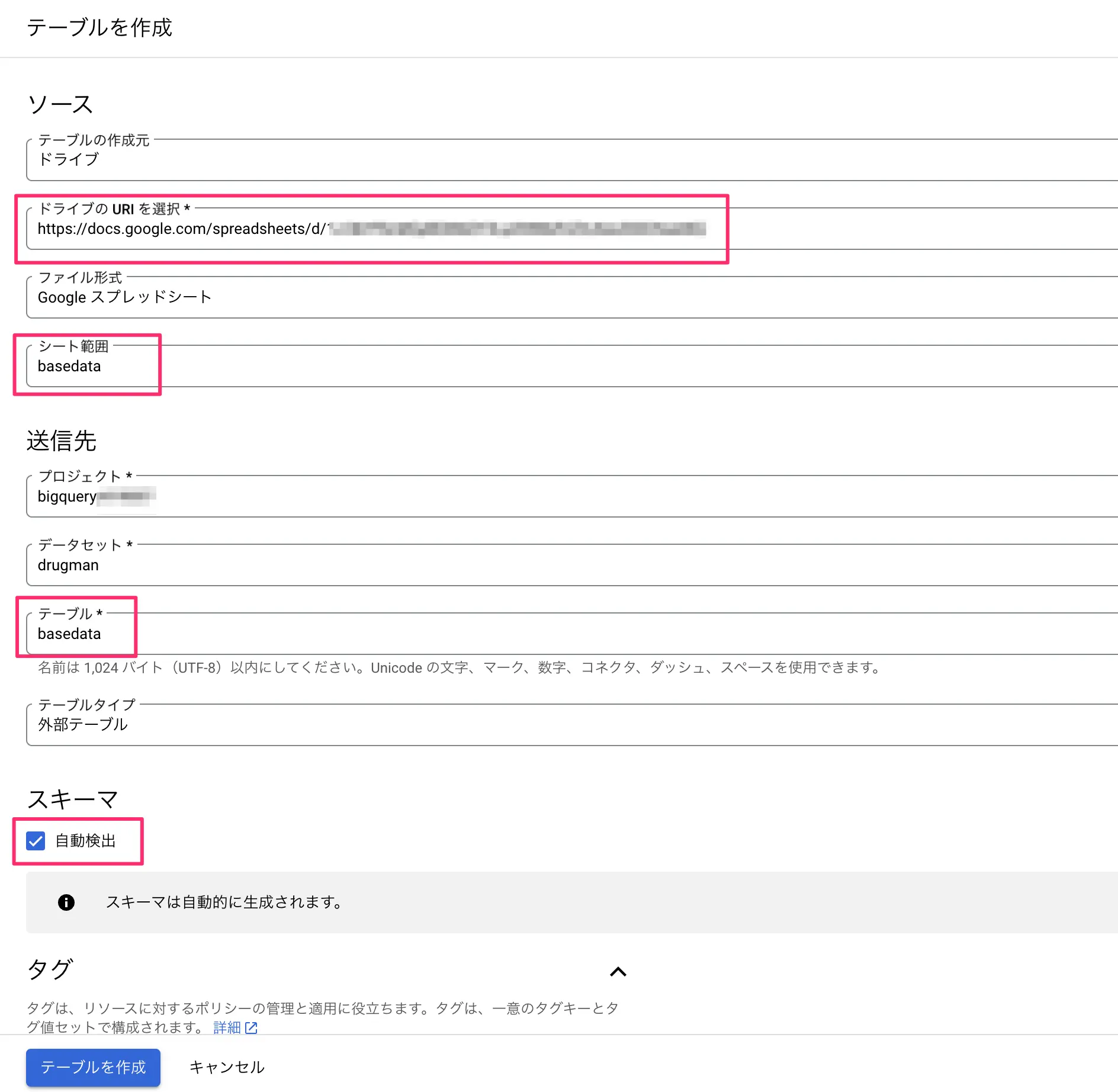
図:外部テーブルとして登録する
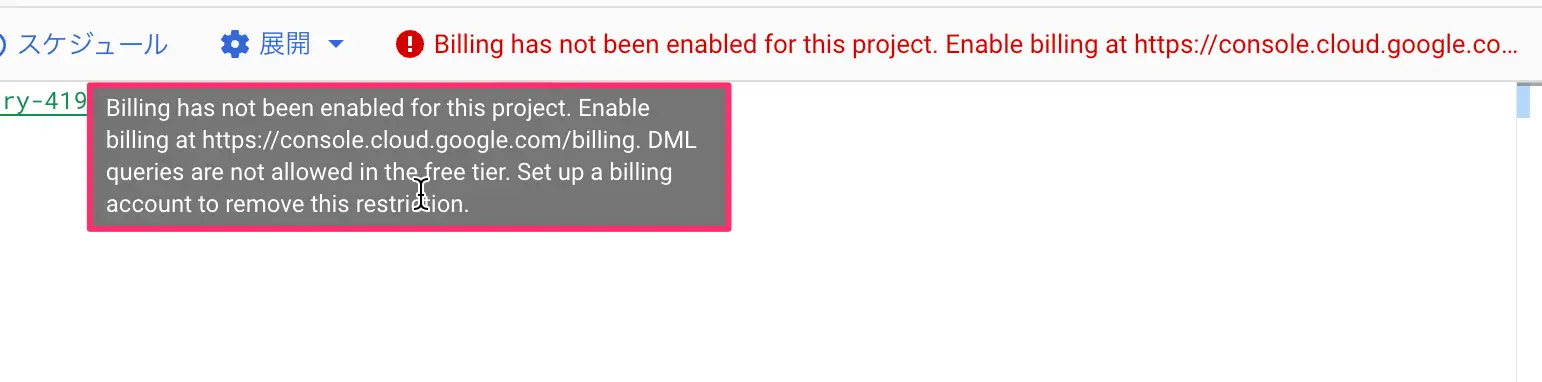
図:課金アカウントでないと使えない

図:作ったクエリを保存しておける
クエリの設定でインポート
前述の方法は、SQL文を構築してデータを追加する方法でした。他にもSELECT文の結果を設定から追加するように仕向けることが可能です。
- basedataのテーブル横の「︙」をクリックして、クエリをクリック
- 展開をクリックし、クエリを設定をクリックする
- 右サイドバーが開くので、クエリ結果の宛先テーブルを設定するを選択する
- データセットは初期ではリストに出てこないので、データセット名の一部を入れて選択する
- 追加先対象のテーブルの名前を入力する
- 宛先テーブルの書き込み設定は「テーブルに追加する」を選択する
- 保存をクリックする
実行をしてみると、SELECT文の結果が対象のテーブルにそのままインサートされました。但しクエリを保存してもこの設定自体は保存されないようで毎回指定が必要です。また、スケジュールとして登録が出来るようです(課金が知らない間に増えることになるのでスケジュール時は要注意)。
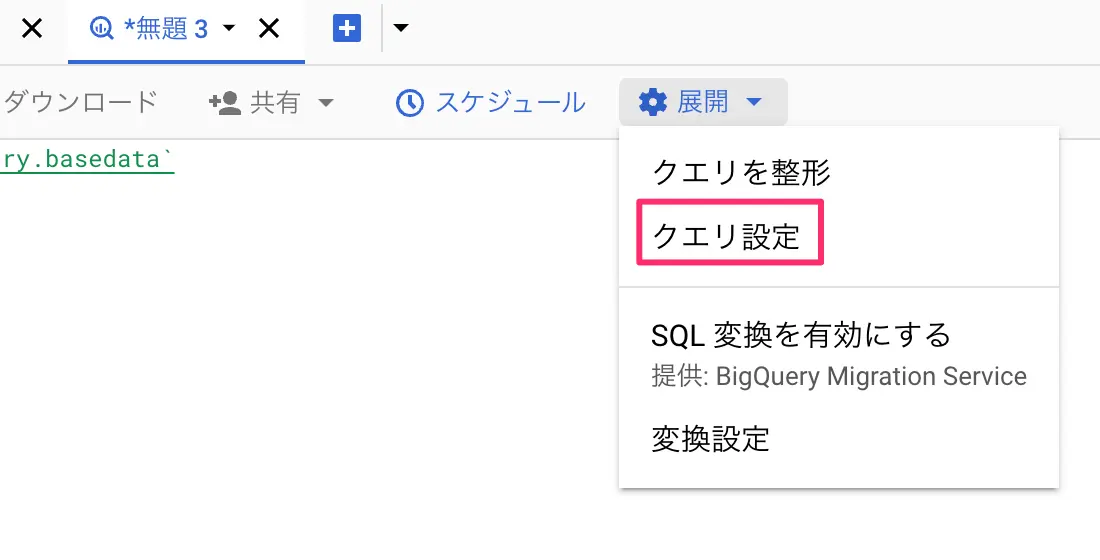
図:クエリ設定を開く
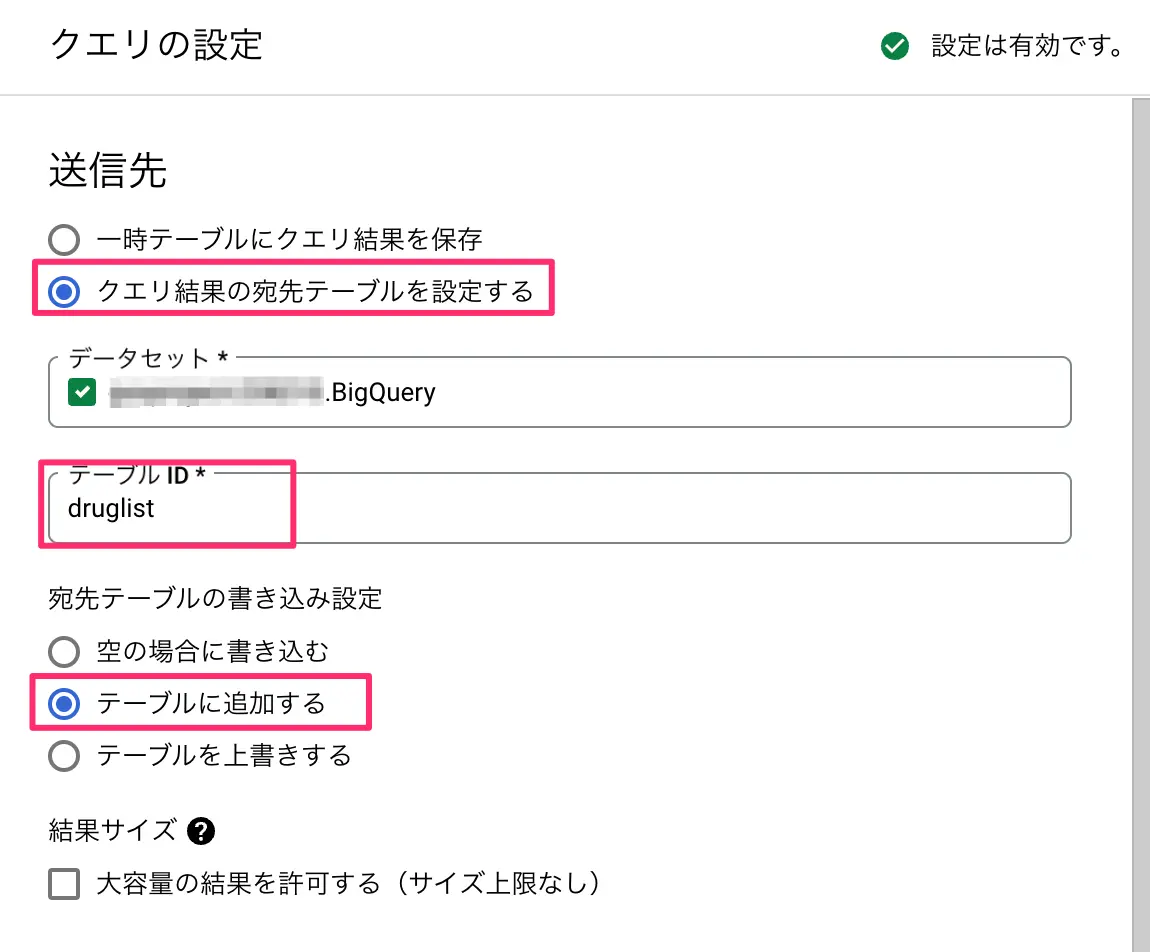
図:追加する設定
Google Apps Scriptでインポート
これまで例示した手法はいずれも、GCP側に入って作業をする必要があり、現場の人間が行うにはちょっと煩雑な手順です。後述のデータコネクタでのインポートも可能ですが、ここではGoogle Apps Scriptを使ってスプレッドシート上から直接インポートする手段を構築してみようと思います。
事前準備
BigQueryのAPIを利用してデータをインポートします。スクリプトエディタで以下の手順で準備をします。
- GCP側の対象プロジェクトのID(数値じゃなく、hogehoge-202020みたいなIDの値)および、データセット名を控えておく
- また、インサート先のテーブルIDを控えておく(いわゆるテーブル名なので今回はdruglistがそれになる)
- インサート先データセットのLocationも控えておく(今回はasia-northeast1)
- スクリプトエディタのサービスの+をクリックする
- BigQuery APIを探して追加をクリックする
これでコードを書く前段階の準備は完了しました。今回はbasedataというシート8つのカラムでデータを用意し(前述までで使っていたシートと同じもの)、これを次項のコードでインポートします。
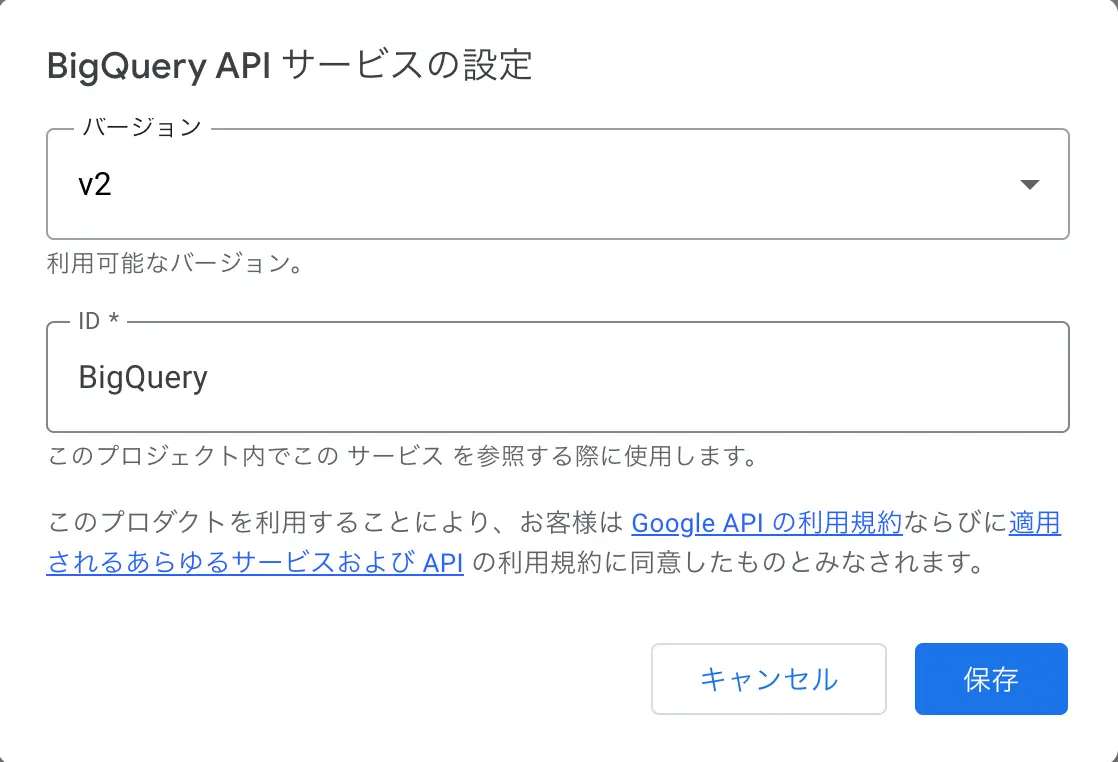
図:サービスを追加する
スプレッドシートからデータを追加
既にdruglistというテーブルは前述までに用意しているので、そこにGASからデータを送り込んでInsertする事が可能です。クエリを実行してるわけではなく、データをCSVでアップロードしてるだけなので課金されることなく、データを送れるメリットがあります。
basedataシートのA2:Hというデータ部分だけを指定してCSVに変換してるので、skipLeadingRowsは0のままにしてあります。getDataRangeで取得してる場合には値は1にしてタイトル行はスキップする必要があります。
//GCP側の必要なパラメータ
var projectId = "ここにBigQueryのプロジェクトIDを入れる";
var datasetId = "ここにデータセットのIDを入れる"
var location = "ここに利用してるリージョン名を入れる";
let tableId = "テーブル名を入れる。シート名と一致させてあります。"
//シートデータをBigQueryにインポートするコード
function importBigQuery() {
//スプレッドシートのデータを取得する
let ss = SpreadsheetApp.getActiveSpreadsheet();
let sheet = ss.getSheetByName(tableId);
let range = sheet.getRange("A2:H").getValues();
//rangeで取得したデータを加工する
for(let i = 0;i<range.length;i++){
//レコードを一個取り出す
let rec = range[i];
//日付型データを変換する
rec[16] = getDateman(rec[16]);
}
//CSVに変換
let result = csvchange(range);
//Blobに変換する
let blob = Utilities.newBlob(result).setContentType('application/octet-stream');
let job = {
configuration: {
load: {
destinationTable: {
projectId: projectId,
datasetId: datasetId,
tableId: tableId
},
skipLeadingRows: 0
}
}
};
//BigQueryにインサート実行
let ret = BigQuery.Jobs.insert(job, projectId, blob);
//ジョブのIDを取得する
let jobid = ret.jobReference.jobId;
//5秒間待ってJOBの結果を受け取る
Utilities.sleep(5000);
const jobresult = BigQuery.Jobs.get(projectId, jobid, { "location": location });
//エラーを捕捉する
if (jobresult.status.errorResult != null) {
console.log('ジョブの実行は失敗しました.');
console.log('エラーコード:' + jobresult.status.errorResult.reason);
console.log('メッセージ:' + jobresult.status.errorResult.message);
console.log(jobresult.status.errors)
} else {
//ジョブが成功したとき
console.log('ジョブの実行は成功しました。');
}
}
//CSVデータ形式に整える関数
function csvchange(data){
let rowlength = data.length;
let csvdata = "";
for(let i = 0;i<rowlength;i++){
//データが空の場合はスルーする
if(data[i][0] == "" || data[i][0] == undefined){
continue;
}
//データをCSV形式に整形
if (i < rowlength-1) {
csvdata += data[i].join(",") + "\r\n";
}else{
csvdata += data[i];
}
}
//CSVデータを返す
return csvdata;
}
- ジョブに送るためのデータはスプレッドシートのデータをCSVの形で構築し直します。コードは以下のエントリーを参考にしてみてください。
- BigQuery.Jobs.insertにてジョブを登録します。この時点ではまだ実行中のまま
- BigQuery.Jobs.getでジョブの実行結果を受け取りますがそのために、sleepで5秒間待機させています。
- Jobのstatusを見てerrorResultがNullじゃない場合はエラーであるのでエラーメッセージを表示する
- GASの制限で一度に送れるデータサイズは、50MBまでなので巨大すぎるデータは難しい。小分けにしてインサートが必要
クエリを叩いてデータを追加
前述のようにスプレッドシートのCSVを構築して送るのではなく、予め外部テーブルでスプレッドシートをテーブルとして追加している場合、クエリを投げることで目的のテーブルにインポートすることが可能です。こちらの手法の場合、データ容量の制限もなく、速度面でも不利にならずに大量のデータを高速でインサートが可能になりますが、反面SELECT文を叩いてる為、課金対象になってしまいます。
//クエリを叩いてインポートするコード
function importInsertQuery(){
//ベーステーブル名を構築する
let basetable = projectId + "." + dataset + "."
//ダミーでDriveAppの認証をしておく
//DriveApp.addFile("test");
//クエリ文を指定する
const query = "INSERT `" + basetable + tableId + "` (jancode,gs1code,oroshi,unit,price,hospname,drugname,transdate) SELECT * FROM `" + basetable + "basedata`";
//クエリを実行する
let result = BigQuery.Jobs.query(
{
useLegacySql: false,
query: query,
timeoutMs: 20000
},
projectId
);
//ジョブのIDを取得する
let jobId = result.jobReference.jobId;
//jobが完了するまで無限ループ
while(!result.jobComplete){
//1秒間待機する
console.log('ジョブ完了まで待機中');
Utilities.sleep(1000)
}
//ジョブ完了結果を取得する
if (result.errors != null) {
console.log('クエリの実行は失敗しました.');
console.log('エラー理由:' + result.reason);
console.log('メッセージ:' + result.message);
return;
} else {
//ジョブが成功したとき
const queryresult = BigQuery.Jobs.getQueryResults(
projectId,
jobId,
{
location: location
}
);
console.log('クエリの実行は成功しました。');
}
}
- このスクリプトを実行するにはDriveAppの権限が必要となるので、メソッドは使いませんがダミーでコメントアウトの状態でDriveApp.addFileを追加しておく必要があります。(Access Denied: BigQuery BigQuery: Permission denied while getting Drive credentials.というエラーが出てしまう)
- BigQuery側でのInsertの構文を構築してクエリを実行します。
- タイムアウトを長めにとって、尚且つクエリが完了するまで無限ループで待機させます。
データを削除する
現状、BigQueryにはテーブル削除のメソッドは用意されていますが、テーブルデータを消去するようなメソッドはありません。よって、テーブルデータを削除する場合には、クエリ文を発行して消すという通常のRDBMSと同じ仕組みで実行します。
ただし注意点があり、単純にDELETEするだけであればqueryに入れた内容をBigQuery.Jobs.queryで実行するだけで良いのですが、削除完了を待って次に処理がある場合には、ポーリングの処理が必要になります。以下は処理が完了するまで待機するようコードを組んでいます。
また、最初の実行時にデータ量が少ないと、ジョブIDを取る前にジョブが完了してしまいIDが取れずにエラーとなるので、initialWaitMsにて初回のみ短めのSleepを入れています。また、その場合の処理も完了したとみなしてループを抜けるようにしています。(2ループ目以降は5秒間待機してから処理状況を確認しています)。
//GCP側の必要なパラメータ
var projectId = "テーブル名を入れる";
var datasetId = "データセット名を入れる"
//テーブルデータをDeleteする関数
function clearBigQueryTableData(tableId, pollingIntervalMs = 5000, initialWaitMs = 1000, timeoutMinutes = 10){
//クエリ文を構築する
const query = `DELETE FROM \`${projectId}.${datasetId}.${tableId}\` WHERE true`;
try {
//クエリ文を実行する
const job = BigQuery.Jobs.query(
{
query: query,
useLegacySql: false // 標準 SQL を使用
},
projectId
);
// 2. ジョブの完了を待機
// ジョブ開始後、最初のポーリングの前に短い待ち時間を設ける
// これにより、非常に高速に完了するジョブで "Not found: Job" エラーを防ぐ
Utilities.sleep(initialWaitMs);
//ジョブのIDを取得する
const jobId = job.jobReference.jobId;
console.log('BigQuery テーブルデータクリアジョブが正常に開始されました。ジョブID: ' + jobId);
// 2. ジョブの完了を待機
const startTime = new Date().getTime();
const timeoutMs = timeoutMinutes * 60 * 1000;
while (true) {
//現在時刻を取得
const currentTime = new Date().getTime();
//タイムアウト時の処理
if (currentTime - startTime > timeoutMs) {
//エラーメッセージ
let msg = `BigQuery ジョブ ${jobId} が ${timeoutMinutes} 分以内に完了しませんでした。タイムアウトしました。`;
//エラーを返す
let msgarr = [false,msg];
return msgarr;
}
//ジョブステータスを取得
let jobStatus;
try {
// ジョブのステータスを取得
jobStatus = BigQuery.Jobs.get(projectId, jobId);
} catch (e) {
// "Not found" エラーが発生した場合、ジョブがすでに完了している可能性を考慮
// 特に、クリーンアップされたジョブの場合
if (e.message && e.message.includes("Not found: Job")) {
let msg = `BigQuery ジョブ ${jobId} が無事に完了しました。`;
//メッセージを返す
let msgarr = [true,msg];
return msgarr;
}
// その他のエラーの場合は再スロー
throw e;
}
const state = jobStatus.status.state;
console.log(`ジョブID: ${jobId}, 現在の状態: ${state}`);
//ジョブが完了したら返す
if (state === 'DONE') {
// ジョブが完了した場合
if (jobStatus.status.errorResult) {
// エラーがあった場合
let msg = `BigQuery ジョブ ${jobId} が ${timeoutMinutes} 分以内に完了しませんでした。タイムアウトしました。`;
//エラーを返す
let msgarr = [false,msg];
return msgarr;
} else {
// 成功した場合
let msg = `BigQuery ジョブ ${jobId} が無事に完了しました。`;
//メッセージを返す
let msgarr = [true,msg];
return msgarr;
}
}
// ジョブが完了していない場合は少し待ってから再度確認
Utilities.sleep(pollingIntervalMs);
}
} catch (e) {
//エラーメッセージ
let msg = 'BigQuery テーブルデータクリア中にエラーが発生しました: ' + e.toString();
console.log(msg)
//エラーを返す
let msgarr = [false,msg];
return msgarr
}
}
ODBCドライバで接続してみる
Google BigQueryにはWindows, Linux, macOS用のODBCドライバがリリースされており、このドライバ経由でローカルのDBと接続させることが可能です。ただし、このドライバは
- テーブルは読み取り専用としてリンクされます。
- Access2013のリンクテーブルでは全ての列が文字列型として認識されます。
- なぜか、システムDSNだとアカウントログインしてもlocalhostのerrorが出てトークンを取得できず設定が作れなかった
- ARM版Windows11では動作しません
といった具合なので、通常のMySQLと接続して自由に入出力というわけには行きません。なので、BigQueryからのデータの取り出しに特化して利用することになるかと思います。
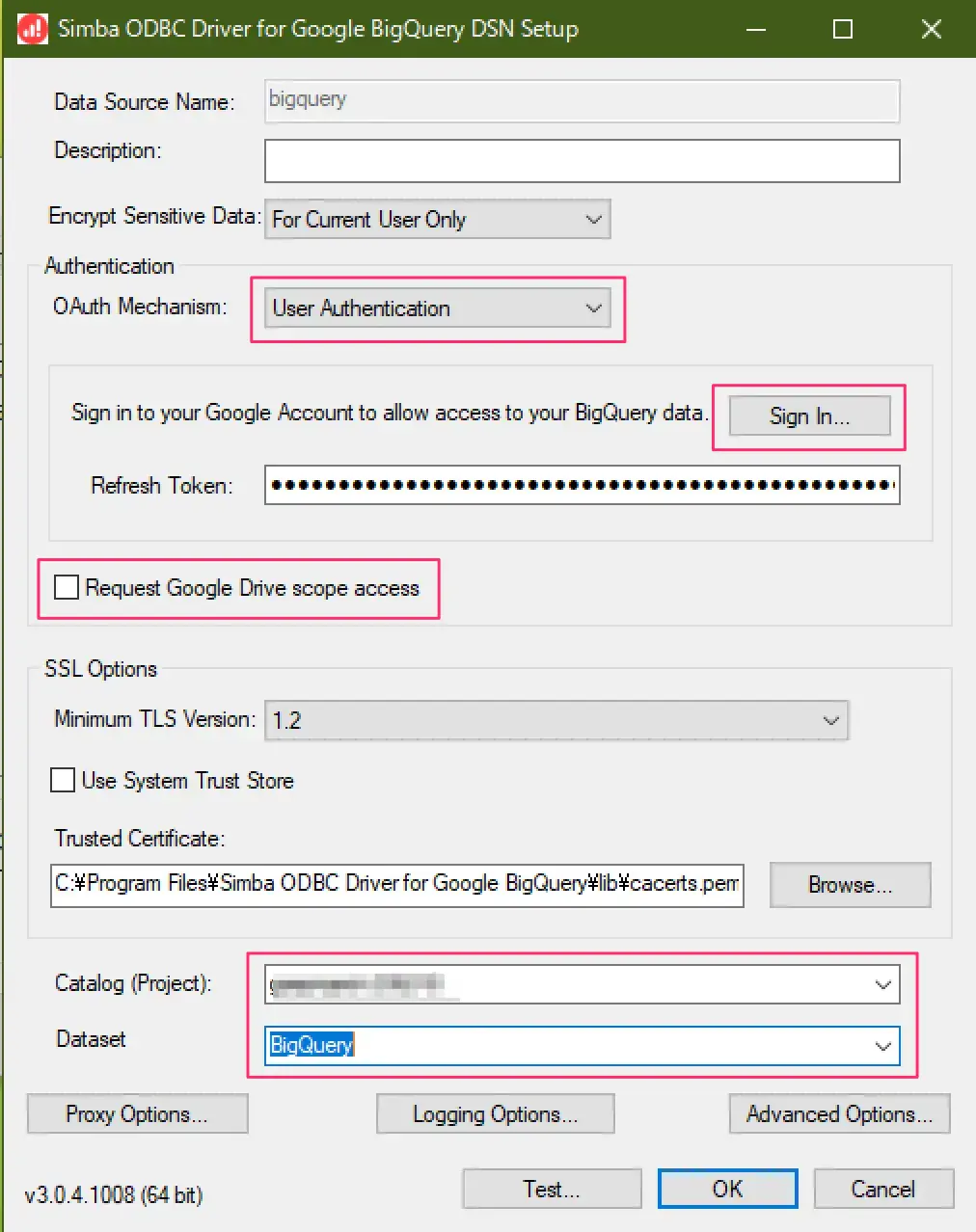
図:ユーザDSNで設定を作ってる様子
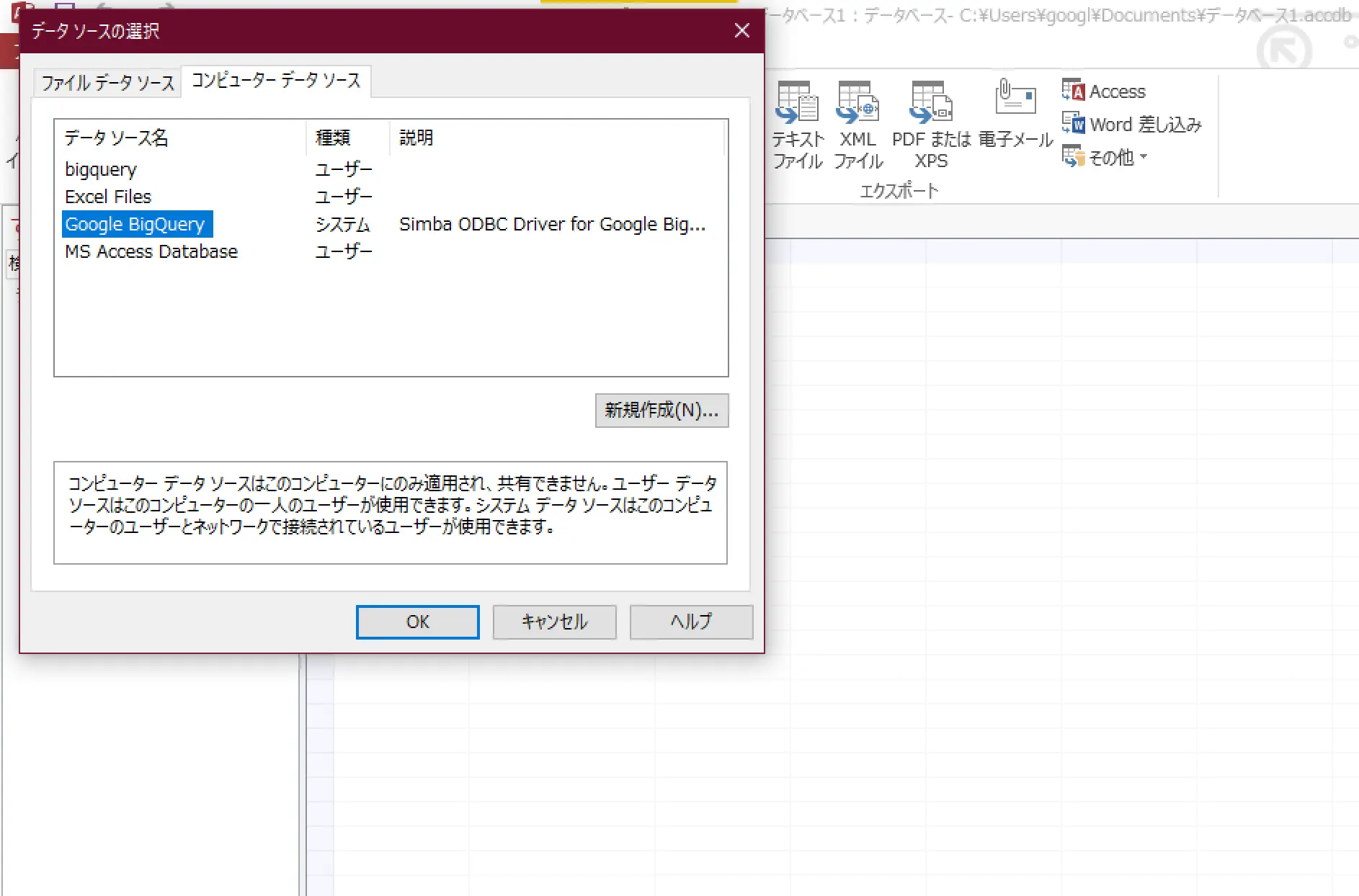
図:データソースはユーザを指定する
図:接続できた様子
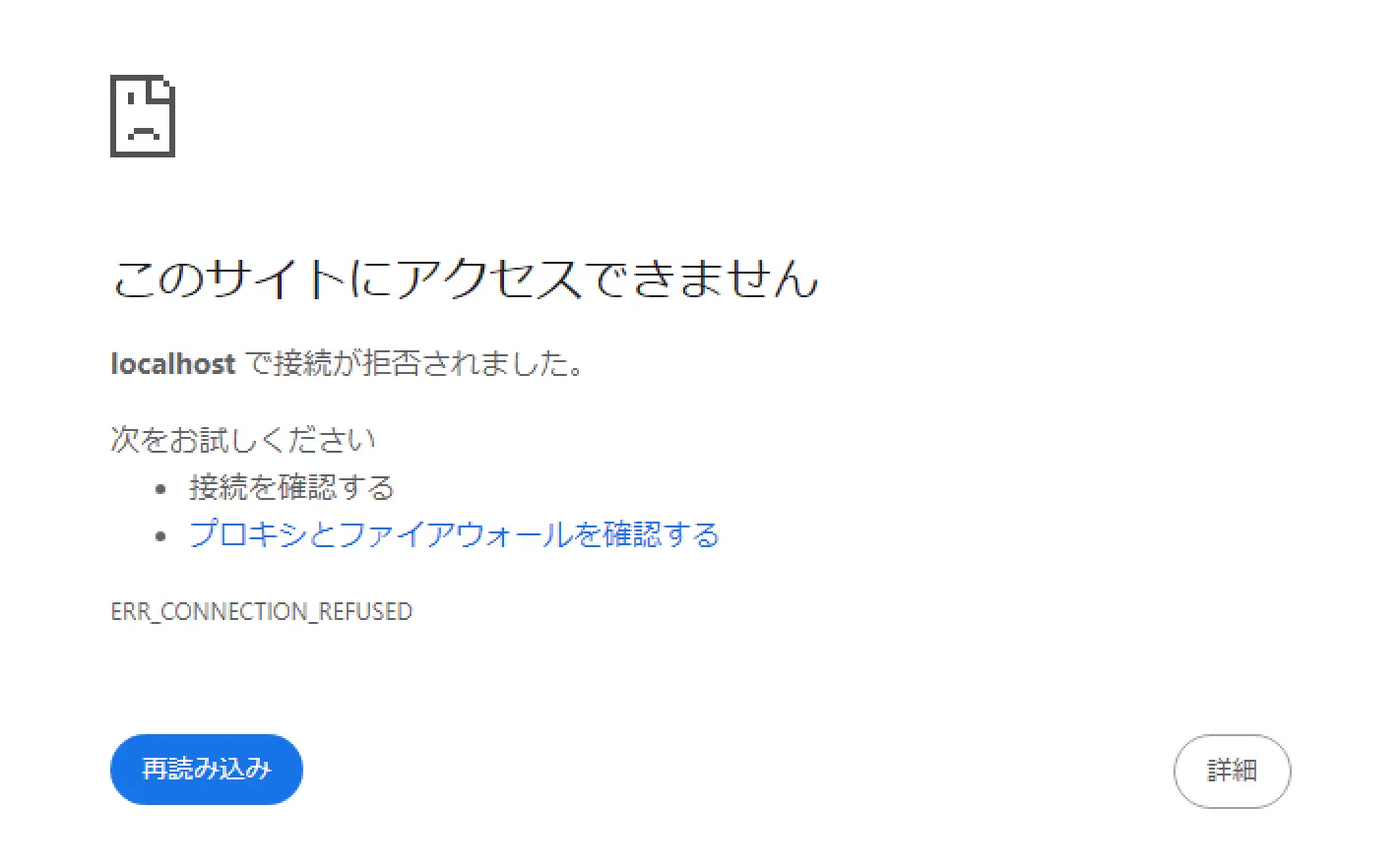
図:システムDSNだとエラーになる
データコネクタで分析する
ここまでで、テーブルの準備とインポートの体制が整いました。Googleスプレッドシートのデータコネクト機能を利用して、テーブルに格納されたデータを取得し、分析を行うことが出来るようになります。
分析結果をスプレッドシートに書き出して、それをもとにLooker Studioなどで読み込ませるようにしておけば、最新のレポートを自動で生成することが可能になります(Google Sitesに埋め込めば分析結果を必要とする人は手間なく見られるようになります)。
データを抽出する
まずはデータコネクタにてBigQueryに接続し、SQL文を書いてスプレッドシートに出力してみたいと思います。
- スプレッドシートを開いて、メニューよりデータ⇒データコネクタ⇒BigQueryに接続をクリックする
- 接続ボタンをクリックする
- GCP側プロジェクト選択画面が出てくるので、対象のプロジェクトをクリックする
- 自分が用意したデータセットが出てくるのでクリックする
- テーブル一覧が出てきますが、クリックするとテーブルデータが出てきます(接続をクリック時)。カスタムクエリを作成をクリックするとSQL文構築画面になります。ここではカスタムクエリ作成をクリックします。
- 例えば、jancodeとoroshi、priceの合計で集計して出す場合は以下のような形でクエリを書きます(パーティショニングしてるので、そのためのWHERE条件も必要です。)
SELECT jancode,oroshi, SUM(price) AS sum_price FROM BigQuery.druglist WHERE TIMESTAMP_TRUNC(_PARTITIONTIME, MONTH) = TIMESTAMP("2024-04-01") GROUP BY GROUPING SETS ( (jancode, oroshi) ) - 接続をクリックする
- 集計結果が新しいシートとして出力される
次回以降は、この新しいシートの「更新オプション」から手動で同じクエリを発行して取得できますし、スケジュールを更新にて定期的に更新を掛けることも可能です(但し課金額に要注意です)
図:単純にテーブルに接続しただけの様子
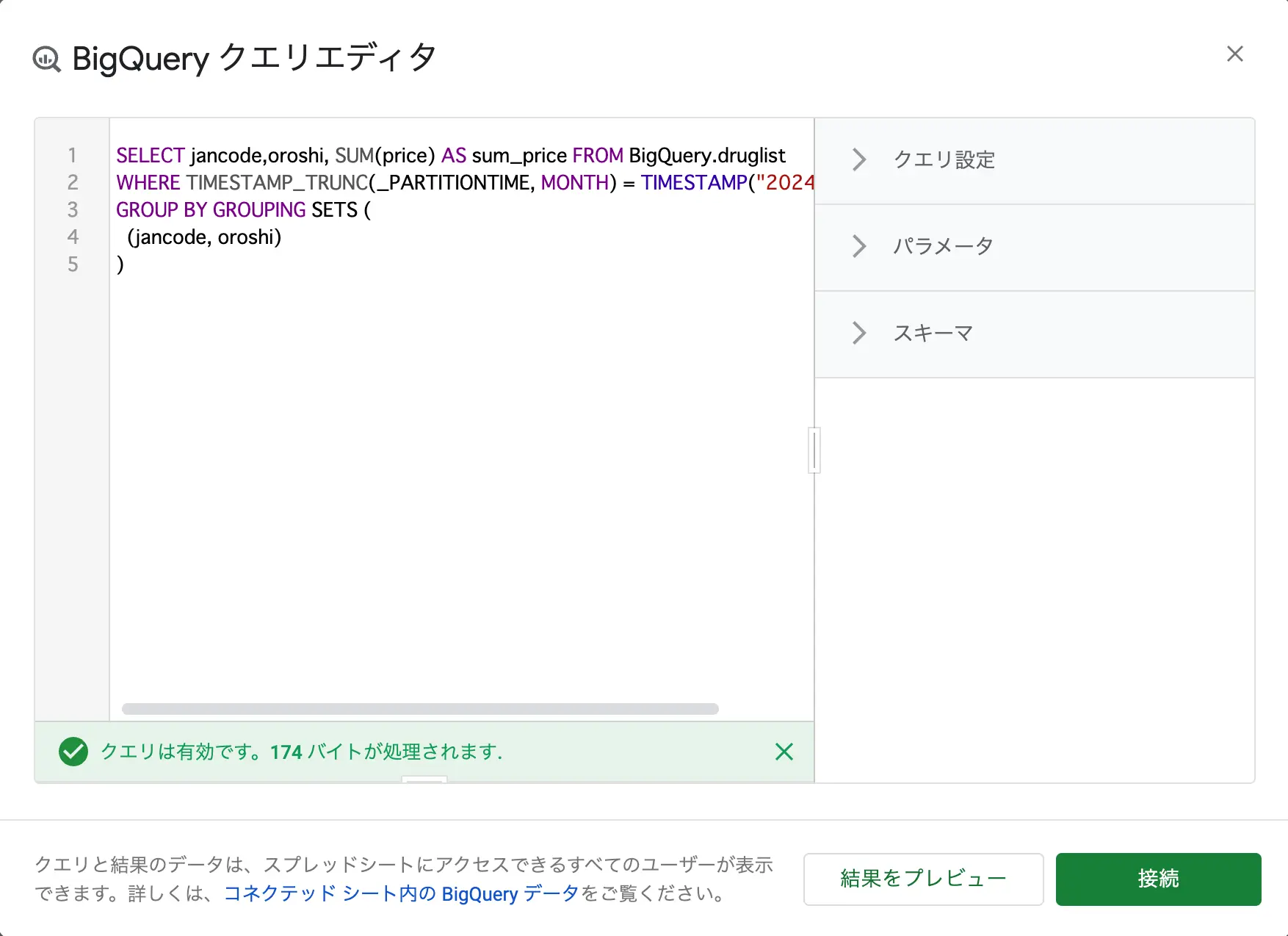
図:集計クエリを実行する
データを二次利用する
接続シートという形で接続データが表示されますが、このままでは他のシートから参照して二次利用等が出来ません。二次利用するためには以下のような手順で抽出しておく必要があります。
- 接続シートを表示する
- 抽出ボタンをクリックする
- 新しいシートを選択して、作成をクリックする
- データ部分だけが新しいシートに切り出されます。
- 更に新しいシートを追加する。
- Filter関数などで4.のシートを参照させて結果を出力させる
Looker Studioで二次利用する場合も、この手順を踏んでから6.の結果であれば参照が可能になる。もともとLooker Studio自体にBigQuery参照機能があるのでスプレッドシートを介さなくても良いのだけれど、毎回SELECT文を発行するとコストが掛かることになる。
また、GASでSELECT文の結果をAPI経由で取得して出力しておく手法もコスト削減に繋がる。
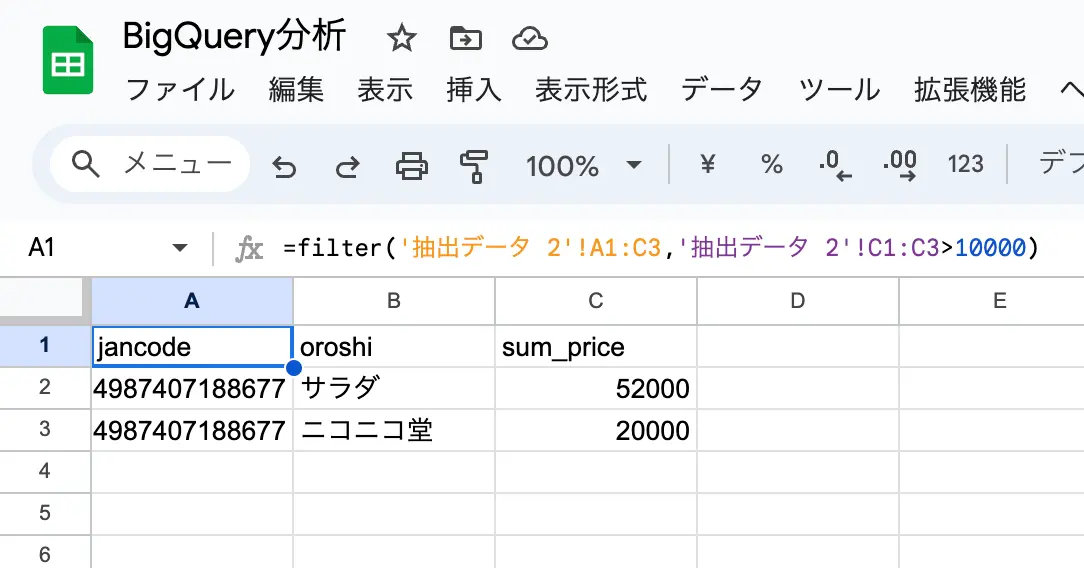
図:二次利用でFilter関数を使ってフィルタしてみた
図:Looker Studioで参照してみた
関連リンク
- BigQueryの料金体系をサクッと解説
- Google BigQuery の料金体系を解説
- BigQueryのコストに対する恐怖心を払拭する
- BigQueryの予算アラート設定
- BigQueryで150万円溶かした人の顔
- BigQueryでのデータ追記処理における冪等化の取り組み
- Microsoft Excel 用の BigQuery コネクタ
- BigQuery 用の ODBC ドライバと JDBC ドライバ
- Connect to BigQuery data in Excel with ODBC (No Code Required!)
- BigQuery 特集: データ操作(DML)
- Google スプレッドシートのデータをBigQueryに連携して分析業務を便利にする方法
- クエリ結果からテーブルを作成する
- Googleスプレッドシート+BigQueryで追加作業が必要なレポーティングを効率化
- Google スプレッドシートで BigQuery データを使ってみる
- クエリ計算の最適化
- BigQuery のコスト削減方法まとめ
- BigQuery スロット需給バランスの改善 〜クエリのパフォーマンス改善の事例から〜
- 安い速い旨い BigQuery の 20 の最適化法
- BigQueryの課金を抑えるために
- 6,000スロットを使うBigQueryのリソース配分最適化への挑戦
- BigQueryのストレージ料金プランを変更して、年間数千万円を節約する
- BigQueryのコスト管理にジョブエクスプローラを活用する方法
- スロットの容量要件の見積もり
- Cloud SQL と BigQuery の違い・選び方(1分でわかる)
- 『BigQuery』とは?3つのメリットや高速処理の仕組みを解説
- BigQueryのサンドボックス環境をつかってみる
- Google Cloudの予算アラートで意図しない課金を予防しよう!
- GASでSpreadSheetのデータをBigQueryに入れてみた
- Googleドライブ上のスプレッドシートのデータをBigQueryに連携する with GoogleAppsScript
- BigQueryのテーブル変更回数の制限対象から、DMLを使用した変更が対象外となりました
- BigQueryではSELECT結果を他テーブルにInsert / テーブル洗い替えなどができる
- BigQuery 使い方(7) 〜レコードの更新、新規登録、削除、マージ
- BigQuery Storage Write APIを利用してBigQueryにインサートする
- BigQueryで再帰クエリを使いこなす
- BigqueryでUNNESTを使いこなせ!クエリ効率100%!!最強!!
- GoogleスプレッドシートをデータソースとするBigQuery外部テーブルをCLIで作成する
- BigQueryのパーティションの有効期限を変更する方法
- How to execute simple query of Big Query table from Google App Script
- BigQueryでGoogleドライブデータへのクエリでエラーが出るときの対処
- BigQueryのデータ型変更が面倒くさかった
