Google Apps ScriptでPDFを結合する方法【GAS】
以前紹介したStackOverFlowのmergePdfs関数がうまく動作しないという報告がありましたので、調べてみた所、一部だけ日本語文字化け等の問題が生じるケースがあることが判明。最近のGoogle系のサービスの更新によるものなのか?うまく動きませんでした。
ということで、前回PDFフォームを操作するで利用したライブラリで今度は結合を実現してみました。
目次
今回利用するスプレッドシート等
以前、PDFフォームを操作するでも同様のライブラリを利用していますが、今回は同じライブラリで結合を実現してみようと思います。サンプルはPDF 1.7の規格のものを利用しています。
以前紹介したスクリプトについて
実は以前にStackOverFlowにて紹介されていた簡単なPDF結合用のコードを紹介したことがあります。しかし、こちらのコード現在では以下のような問題があります。
- PDF 1.4以降のものを結合しようとすると一部で文字化けが生じる
- 同様になぜか偶数ページに白紙のページが増えてオカシナ結合PDFが生成されるようになる
とりわけこの現象は最近になってから生じるようになったため、GoogleでのPDFの生成バージョンが変わったのが理由かもしれません。故に、日本語環境で使うにはちょっと問題がありました。
Googleの生成するPDFについて
Google Apps ScriptでPDFを生成する手法は複数あります。しかし、どの手法で生成しても2024年4月時点ではすべてVersion1.4規格のものが出力されるようになっています。
今回のスクリプトはPDFLibにてこれらを結合する検証もしてみました。PDFLibは1.7規格のものでも結合ができますが、1.4規格のものを結合したらどうなるのか?
結論から言えば全く問題なく結合でき日本語で文字化け等もありませんでした。
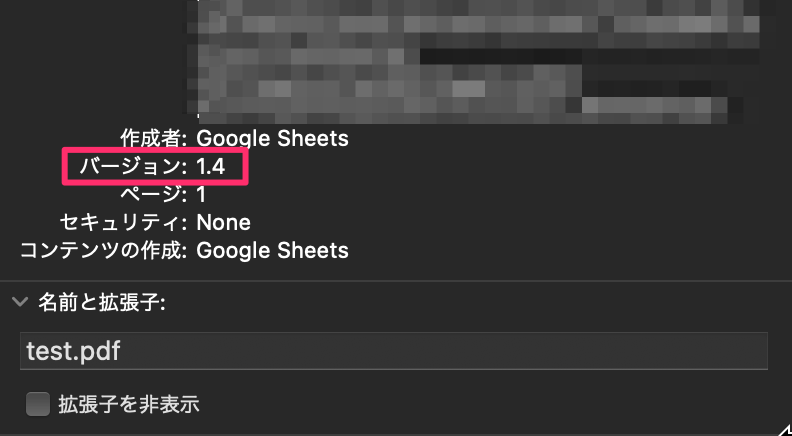
図:v1.4規格のPDFが出力される
ソースコードと結果
2枚のPDFを単純結合コード
JS用ライブラリを利用するため、少々手順が必要なのと、その為に対策が必要です。
以下のようにJSライブラリを外部から直接ロードしています。JSライブラリをgsファイルとして貼り付けると毎回読み込みに時間が掛かるのと、セーブする度に時間が掛かるのでこのようにしています。またJSライブラリ内でsleepを使ってしまってるため、これをGASのUtilities.sleepに置き換えていま(でないとエラーが出てしまう)。
あとは、出力先フォルダおよび今回のサンプルファイル1と2のファイルIDを指定しています。mergePdfsを実行すると2つのPDFを読み取って結合し、1枚の結合PDFとして出力します。
※但しライブラリはgsに貼り付けておいたほうが初期のロード時間は短くなる。
※結合とありますが、実際には空のPDFを作成し、複数のPDFのデータをそこへ順番に足していって実現しています。
※1行目のevalの内容はUrlfetchAppへのリクエストが含まれてるので、手動で初回認証をしないとonOpenなどのメニューが開かれないことがあります。その場合は、mergePdfsの関数内の1行目に記述するようにしましょう。
//eval関数で外部JSを取得させると導入できる
eval(UrlFetchApp.fetch("https://unpkg.com/pdf-lib/dist/pdf-lib.js").getContentText());
//setTimeoutをUtilities.sleepに置き換えてしまう
setTimeout = (func, sleep) => (Utilities.sleep(sleep),func())
//保存先フォルダID
var driveman = "ここに生成先PDFファイルを格納するフォルダのIDを入れる" //生成先フォルダID
//サンプルPDFファイル
var pdf1 = "1vrT3YTg-rQFhjNOIN6S3dH8jHsFc9RnX"
var pdf2 = "1lGNNjLHF4I2iJsTejxcbekPSeyz-Dc1Z"
//PDFを結合するメインルーチン
async function mergePdfs() {
// マージ用の空PDF空を作成
const mergedPdf = await PDFLib.PDFDocument.create();
// マージ元のファイル情報取得
var blob = DriveApp.getFileById(pdf1).getBlob();
var bytes = blob.getBytes();
//pdf1を読み込み
var bytesMine = Utilities.base64Encode(bytes);
var pdfdocs1 = await PDFLib.PDFDocument.load(bytesMine);
//マージするファイルの情報を取得
var blob2 = DriveApp.getFileById(pdf2).getBlob();
var bytes2 = blob2.getBytes();
//pdf1を読み込み
var bytesMine2 = Utilities.base64Encode(bytes2);
var pdfdocs2 = await PDFLib.PDFDocument.load(bytesMine2);
// マージ対象のファイルの全てのページ情報取得
const targetPdfPages = await mergedPdf.copyPages(
pdfdocs1,
pdfdocs1.getPageIndices(),
);
//pdfdocs1を結合
for(const page of targetPdfPages) {
mergedPdf.addPage(page);
}
// マージ対象のファイルの全てのページ情報取得
const targetPdfPages2 = await mergedPdf.copyPages(
pdfdocs2,
pdfdocs2.getPageIndices(),
);
//pdfdocs2を結合
for(const page2 of targetPdfPages2) {
mergedPdf.addPage(page2);
}
//ドライブにファイルを生成する
const base64String = await mergedPdf.saveAsBase64()
const data = Utilities.base64Decode(base64String)
var blob = Utilities.newBlob(data).setName("結合ファイル.pdf").setContentType("application/pdf")
DriveApp.getFolderById(driveman).createFile(blob);
}
結合結果
今回のスクリプトはV8ランタイムが有効である場合に利用可能です。また、JS用ライブラリを使っていますが、今回は貼り付けるのではなく、コード内でロードして利用していますので事前準備も必要ありません。
実際にPDF 1.7規格のものを結合していますが、問題なく結合が出来ています。文字化けやオカシナ白いPDFなどが生じていません。
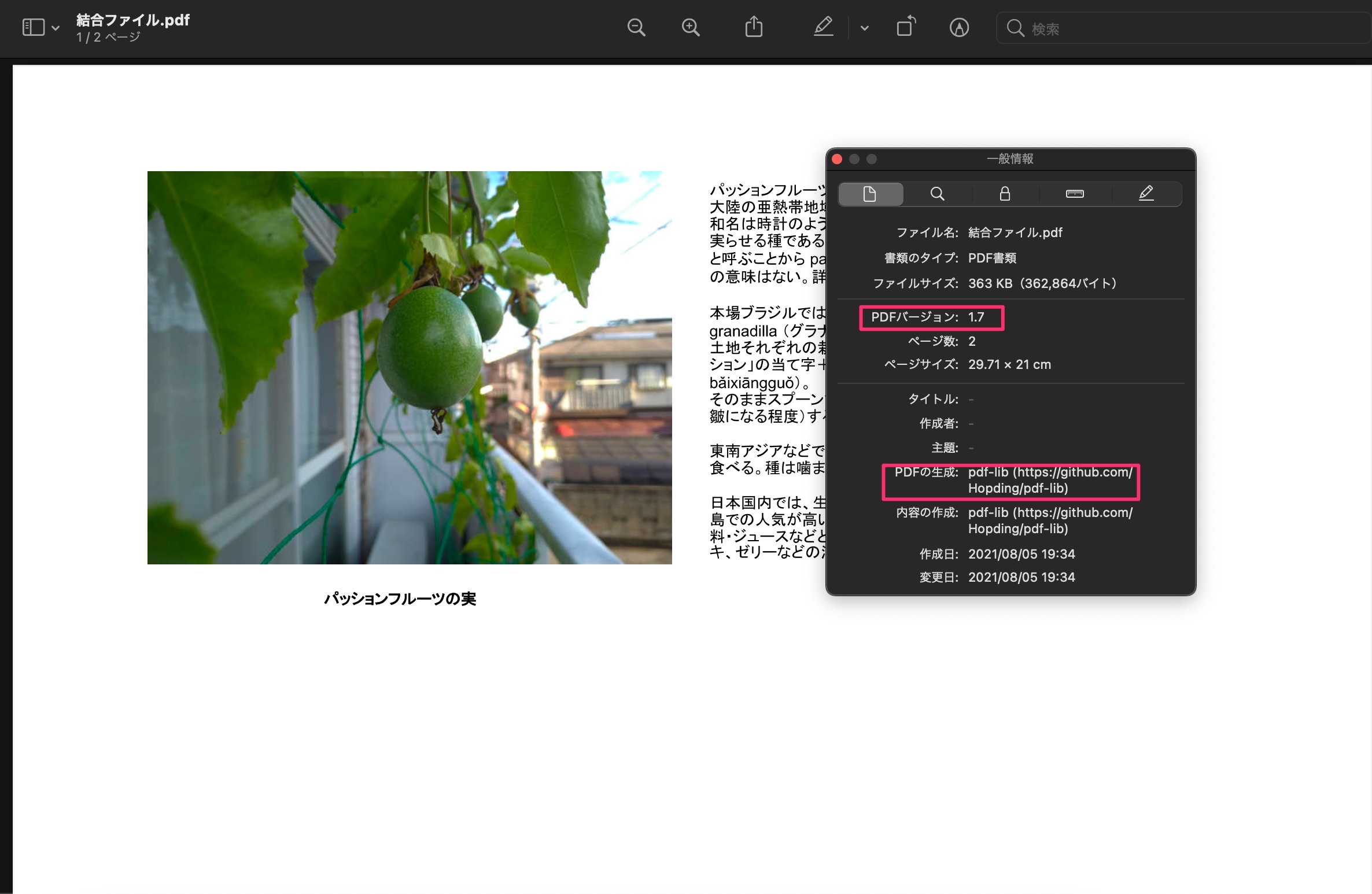
図:GCF無しでv1.7規格の結合に成功
指定フォルダ内のPDFをまとめて結合
mergePdfsが掲載されてるStackOverFlowのページにも、PDFLibsを利用したまとめてPDF化するスクリプトが掲示されており、実際にv1.4規格のGoogle出力のPDFで実験してみましたが、問題なく結合できました。
//まとめて結合の対象フォルダ
var target = "PDFがまとめて入ってるフォルダのID";
var exportman = "結合PDFの出力先フォルダのID";
//eval関数で外部JSを取得させると導入できる
eval(UrlFetchApp.fetch("https://unpkg.com/pdf-lib/dist/pdf-lib.js").getContentText());
//setTimeoutをUtilities.sleepに置き換えてしまう
setTimeout = (func, sleep) => (Utilities.sleep(sleep),func())
//指定のフォルダ内のPDFをまとめて結合するメイン関数
async function mergeAllPDFs(blobs, fileName) {
//PDFLibsでパッケージ
const pdf = await PDFLib.PDFDocument.create();
//取得したPDFデータを次々に結合する
for (let i = 0; i < blobs.length; i++) {
//PDFデータをロードする
const tempBytes = await new Uint8Array(blobs[i].getBytes());
const tempPdf = await PDFLib.PDFDocument.load(tempBytes);
//PDFページのページカウントを取得する
const pages = tempPdf.getPageCount();
//空のPDFに対して取得データを追加していく
for (let p = 0; p < pages; p++) {
const [tempPage] = await pdf.copyPages(tempPdf, [p]);
pdf.addPage(tempPage);
}
}
//PDFを保存する
const pdfDoc = await pdf.save()
//結合PDFを返却する
return Utilities.newBlob(pdfDoc).setName(fileName)
}
//PDFをまとめて結合する関数
async function MergeFiles() {
//指定のフォルダ内のPDFを検索
let folder = DriveApp.getFolderById(target);
let files = folder.getFiles();
let blobs = [];
//blobsに対象のPDFをすべて配列に追加
while (files.hasNext()) {
let file = files.next();
blobs.push(file.getBlob());
}
//PDF結合を実行
let myPDF = await mergeAllPDFs(blobs, "新結合したPDF.pdf")
//出力先フォルダに出力
let exportFolder = DriveApp.getFolderById(exportman);
exportFolder.createFile(myPDF);
}