Google Apps ScriptでWhisper APIを使い字幕を作成する【GAS】
Youtube動画を世界展開するにはまず、動画に対して適切な字幕ファイルを用意する必要があります。Youtubeには自動翻訳はありますが、あくまでも自動翻訳でそれが適してるかどうかはわからない。しかし字幕ファイルを用意するのは結構な労力を要します。
そこで、以前GeminiでM4Aファイルからチャレンジしましたが、イマイチでした。ということで、今回はOpenAIのWhisper APIを利用して字幕ファイルを簡単に生成できないか?チャレンジしてみました。
目次
今回利用するファイル等
- Whisperで字幕ファイル作成 - Google Spreadsheet
- OpenAI Whisper API Reference
- Introducing Whisper
- Whisper WebUI - Streamlit
- Audioの生成オプション
- 変換結果のSRTファイル
これまでOpenAIのWhisperは音声を扱うモデルがあり優れた結果を出していました。現在は上位版のgpt-4o-transcribeがリリースされて利用可能ですが、Whisperを指定しないとSRT出力は現在できないです。このAPIをテストで利用することのできるページで使ってみましたが、かなり正確に日本語を認識しつつ肝心の字幕ファイルであるSRTとして出力するのに重要な「タイムスタンプ」も非常に正確に出力できました。
そこで、このモデルを使って動画やM4Aといった音声ファイルから字幕ファイルを生成してみたいと思います。
※GeminiもGemini 2.5 Proを利用したところ、Whisperと同じくらい精度の高いものが出せるようになりました。以下のエントリーにまとめています。
制限事項
ファイルサイズに制限があります。最大25MBまで。Google Apps Scriptの制約が最大50MBまでなのでGASのQuota上は問題はありませんが、25MBまでとなるとSRTファイルを作る上ではM4Aのファイルが10分で11MBと考えると20分くらいの動画の字幕までは作れる計算になります。
しかし長尺の動画となると制約に引っかかってしまうことになるので、その場合ファイルを分割した上で、1つ目のファイルの終わりの時間分だけ2つ目のファイルはタイムスタンプをあとでズラしてあげる必要があります。
また、出力トークンは最大で16,384トークンがGPT-4oの上限となっているので、ものすごく短時間に喋る人ではない限り、20分の動画ということであれば十分SRTファイルとして出力出来るのでは無いかと思います。
Gemini 2.0 APIの場合出力トークンが8192トークンが上限であるため、10分の動画であっても半分で上限に達してしまい出力しきれなかったですが、ChatGPTは出力トークン上限が2倍あるので、10分程度の動画であれば十分出力可能。尺が20分だと足りないかもしれない。
Whisper WebUIで試してみる
gpt-4o-transcribeの前身であるWhisper APIを使っての変換を行えるWebサイトがあります。ただし自分のアカウントのAPIキーを利用する必要があるので自己責任での利用となりますが、実際に試してみました。元になった動画からM4Aファイルを作り(10分でおよそ11MB)、アップロードしてSRTファイルを作る事が可能です。
事前にOpenAIアカウントにてAPIキーを発行しておく必要があります。
- こちらのウェブサイトにアクセスする
- 左サイドバーにAPIキーを入力する
- transcription or translationでは、Create transcriptionを選択する
- Audio FileではBrowseをクリックして、M4Aファイルを選択しアップロードする
- Option customizationにて、Input LanguageはJapaneseを選択する
- Promptでは英語にて指定する。ただし、英訳してからSRT生成してなどの指定は出来なかった。
- Output FormatではSRTを選択する
- 最後にTranscribe Audioボタンをクリックする
- Click to Download SRT Fileをクリックすると字幕ファイルが手に入る
コスト的にはこの11MBの音声ファイルで12KBのファイルが生成されて、$0.6程度でした。この出力結果のファイルをYoutube Studioの字幕から該当のファイルに対して追加すればOK。
出力結果はタイムスタンプは非常に正確で、Geminiの時とは全く違う結果になりました。APIキーは一応利用したら削除しておきましょう。出力結果のSRTファイルはこちらになります。
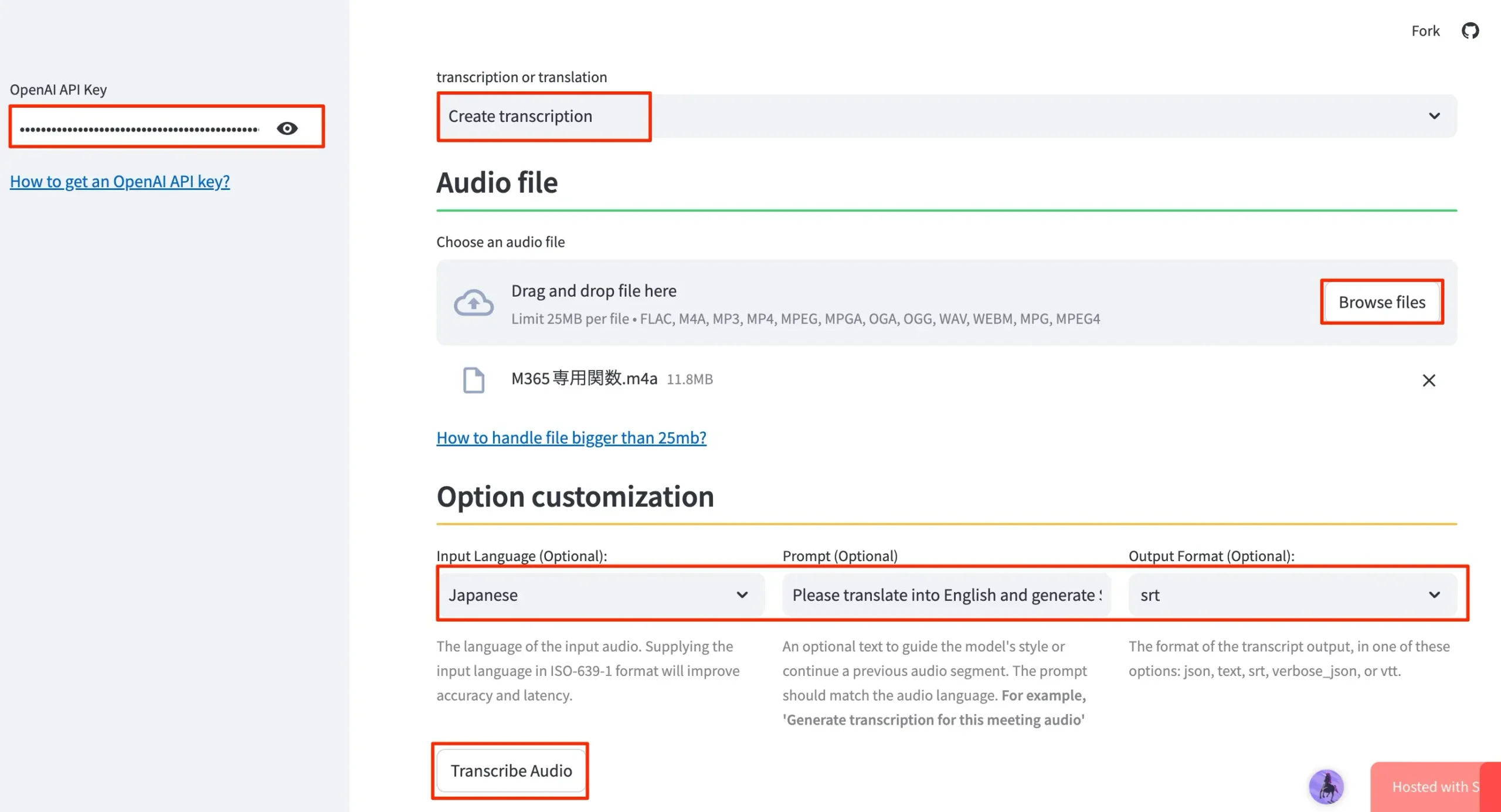
図:Whisper GUIで設定してる様子

事前準備
APIキーの取得
まずは、OpenAIのアカウントからAPIキーを取得する必要があります。以下の手順でキーを作成しましょう。
- OpenAIのアカウントにログインする
- 左サイドバーのOrganizationにあるAPI Keyをクリックする
- Create new secret keyをクリックする
- Nameは適当に入力し、プロジェクトはすでに作ってあるものを選択し、Create secret keyをクリックする
- キーが生成されるのでコピーしてDoneをクリックして閉じる(キーはこの時にしかコピーできない)
このキーを次項のスクリプトプロパティに格納して使います。
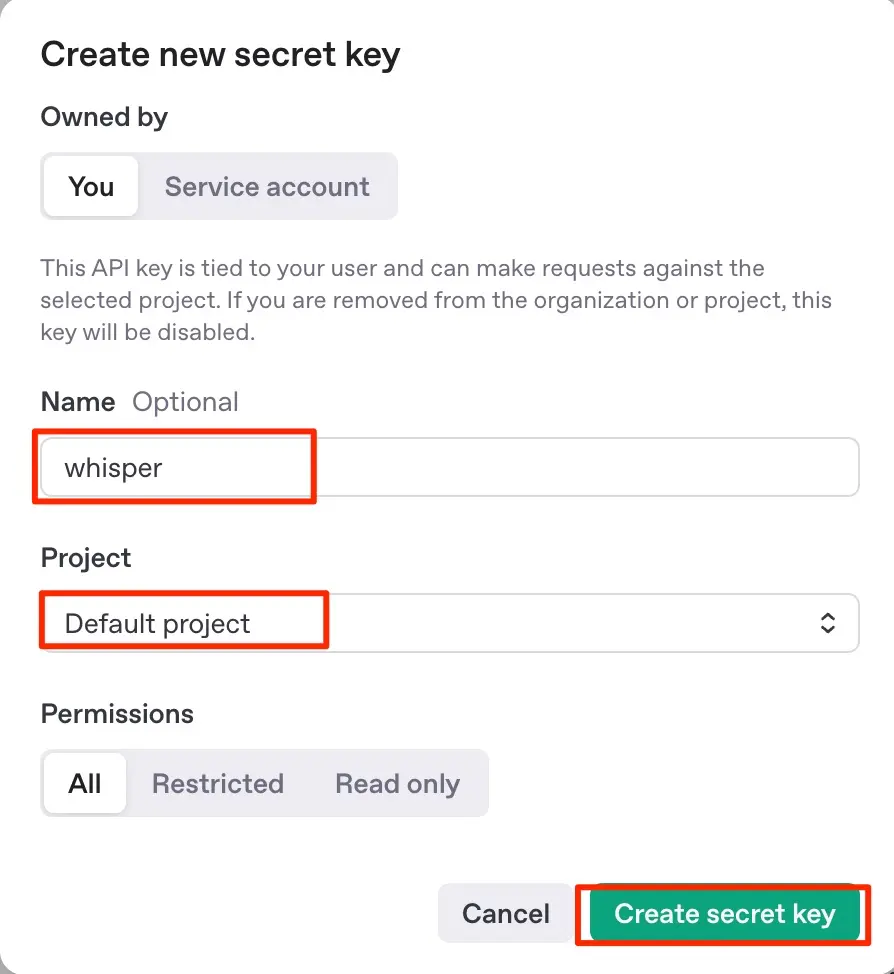
図:キーを生成する
スクリプトプロパティに保存
前述で取得したAPI Keyだけでなく、SRTファイルを生成するGoogle Drive上のフォルダのIDをスクリプトプロパティに格納しておきます。これら2つの値を以下のように格納しておきます。
- apikey : ChatGPTのAPI Keyの値を格納する
- folderid : SRTファイルを生成するフォルダのIDを格納する
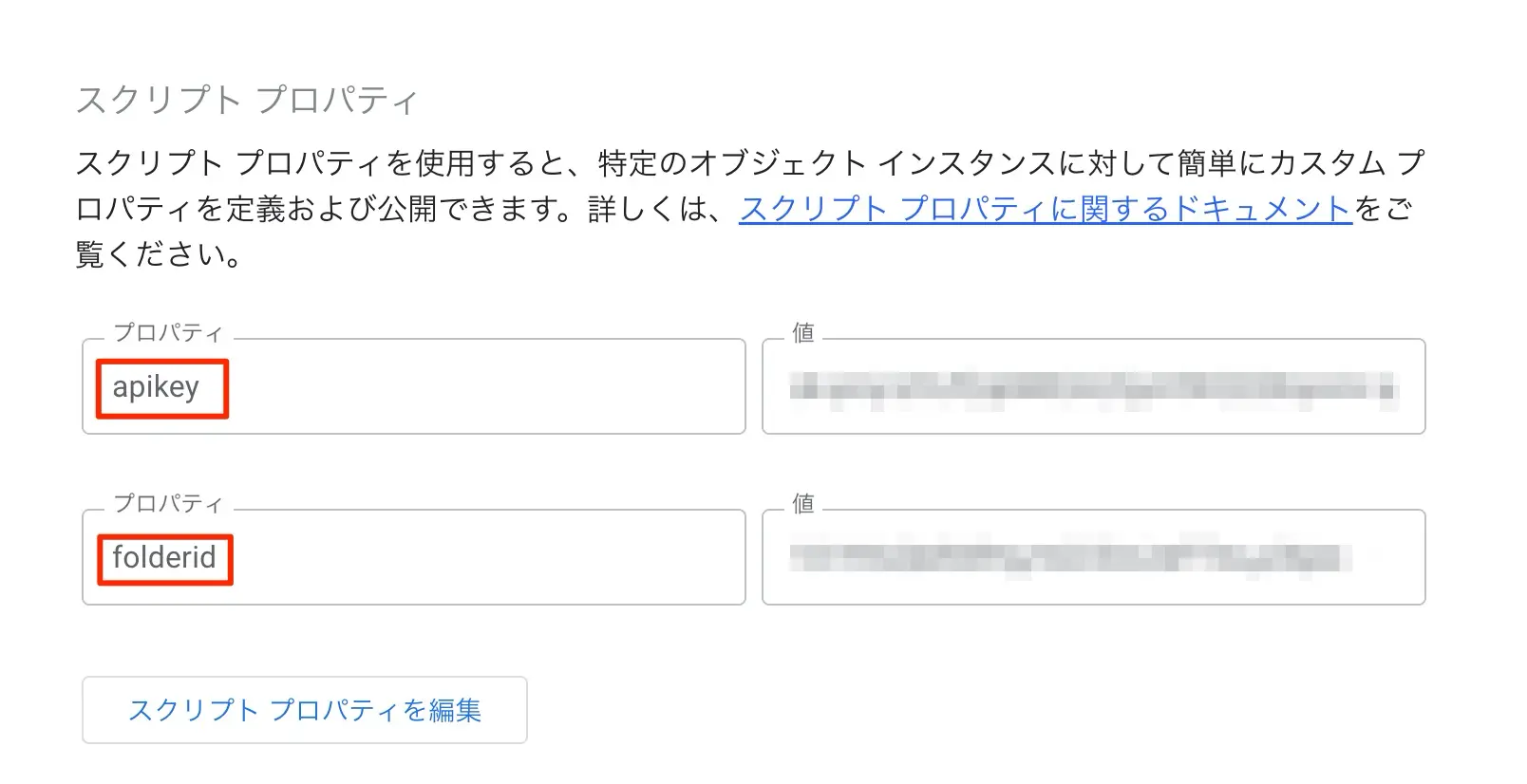
図:スクリプトプロパティに格納する
ドライブにM4Aファイルを配置する
また、今回はYoutubeの動画ではなく、前回記事同様に動画ファイルからmacOSのQuick Time Playerを使って生成したM4Aファイルをアップして変換します。Youtubeにアップする用の動画には動画と音声の2つが含まれており、動画と同じ長さの音声ファイルが入っています。この音声ファイルを取り出して、Geminiにて字幕ファイルを作成することになります。
macOSでの事例になりますが、標準で存在してるQuickTime Playerで簡単にM4A音源だけを抽出することが可能です。
- QuickTime PlayerでMP4動画を読み込ませる
- メニューからファイル→書き出す→オーディオのみを選択
- 保存場所を指定して完了
- このファイルをGoogle DriveにアップロードしてファイルIDを控えておく
これでM4Aファイルが生成されます。
※BGM無しの音声のみの動画を用意して抽出したものならば、さらに精度があがるかもしれない。
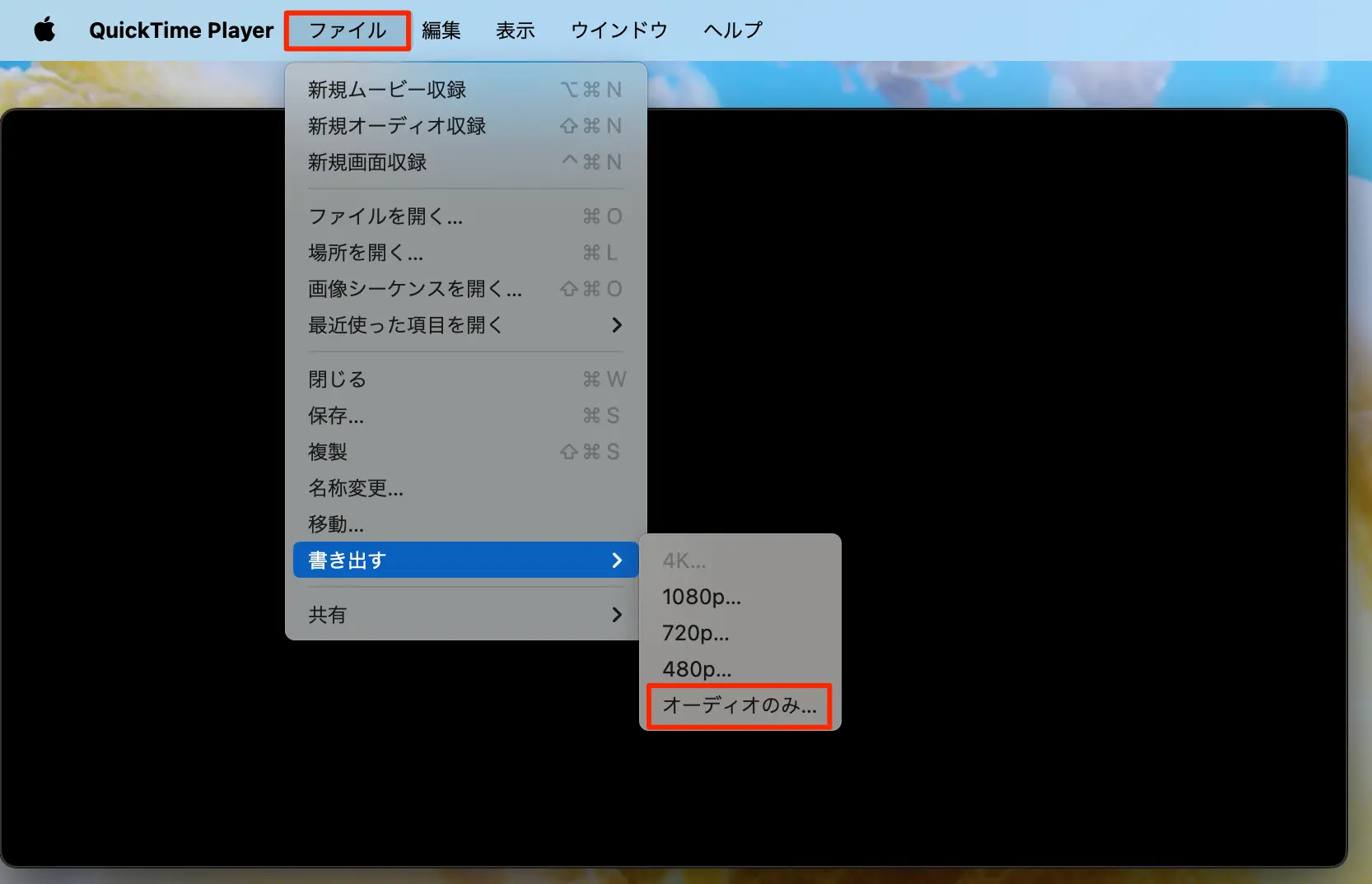
図:オーディオのみに変換で一発
ソースコード
今回の動画は日本語の動画であるため、まずはこのAPIで日本語の文字起こしをしたSRTファイルを生成する。その結果をGPT-4oにて日本語の自然言語に修正しつつ、英語に翻訳したものをSRTで出力するという二段構えで生成と変換を行う必要があります。
文字起こし段階では会話の途中で分断されて次のブロックが始まっている箇所などがあるので、これをまず修正する為の校正処理が自然言語での修正となります。
ただし、IT用語などがうまく拾えていない部分があったりするので一度日本語でSRTファイルを出力させた後に手修正で直して、それを再度翻訳するような形の半自動化のほうがスムーズでより正確なSRTファイルを作れるのではないかと思います。
SRTファイルを生成する
Whisper APIは難しいプロンプト無しでダイレクトにSRT形式が出力可能です。Whisperに送る場合にはBase64エンコードはせずにBlobで取得したものをそのまま送信します
payloadではpromptを指定することもできますが、英訳してみたいな指示はできません。出力後のテキストに対して別途ChatGPTのAPIに問い合わせをして変換が必要です。
またtranscribeAudio関数では文字起こししてSRT形式にしてくれますが、このままだとおかしな日本語などが記録されていたりするので、次項の日本語して校正を掛けてあげると良い感じになります。10分の音声ですがそこそこ時間は掛かりますが、Geminiと異なり長文でしっかりと最後までデータが出力されました。
//変換するM4AファイルのIDを入れる(25MB以下まで)
var fileId = "ここにM4AファイルのIDを入れる";
//エンドポイントURL
var endpoint = "https://api.openai.com/v1/audio/transcriptions";
//M4AファイルからSRTファイルを生成する
function generateSRTFromM4A() {
//APIキーと出力先を取得する
let prop = PropertiesService.getScriptProperties();
let apiKey = prop.getProperty("apikey");
let targetdir = prop.getProperty("folderid");
//出力先を取得する
let target = DriveApp.getFolderById(targetdir);
//Google DriveからM4Aファイルを取得
const file = DriveApp.getFileById(fileId);
const blob = file.getBlob(); //base64エンコードはしない
//payloadを構築する
let audioFileName = file.getName();
//GPT-4o Transcribe API にリクエスト
const transcript = transcribeAudio(blob, apiKey);
if (!transcript) {
console.log("音声認識に失敗しました");
return;
}
//SRTファイルをGoogle Driveに保存
const srtFile = target.createFile(`${audioFileName}.srt`, transcript, MimeType.PLAIN_TEXT);
}
// 音声認識(whisper-1)
function transcribeAudio(blob, apiKey) {
//Payloadを構築
let formData = {
"model": "whisper-1", //whisper-1じゃないとSRTで出力できない
"temperature": "0",
"language": "ja",
"file": blob, // Blob オブジェクトを直接送信
"response_format" : 'srt', //SRT形式を指定する
"timestamp_granularities":["segment"]
};
//リクエストオプション
let options = {
method: 'post',
headers: {
"Authorization": 'Bearer ' + apiKey,
},
payload: formData,
muteHttpExceptions: true
};
//APIリクエスト
let response = UrlFetchApp.fetch(endpoint, options);
//レスポンスデータを取得
let json = response.getContentText();
//テキストを返す
return json;
}
日本語の文章校正を行う
今回の音声の場合、Microsoft365の関数名などが文字起こしの場合にはうまく文字起こしができずにおかしな箇所がありました。そこで続けて、文字起こししたSRT形式のまま、以下の関数でChatGPTに文章校正をしてあげると殆どが修正されて、良い感じに仕上がります。
図:文章校正したらいい感じになった
// 日本語を自然な表現に修正 (ChatGPT API 使用)
function refineJapaneseSRT(srtText, apiKey) {
//リクエストエンドポイント
let endpoint2 = "https://api.openai.com/v1/chat/completions";
//プロンプト本文
let prompt = `以下のSRT形式の字幕をより自然で分かりやすい日本語に修正してください。
ただし、時間コードや番号はそのままにしてください。\n\n${srtText}`;
//payloadを構築する
let payload = {
"model": "gpt-4",
"messages": [{"role": "system", "content": "あなたはプロの日本語編集者です。"},
{"role": "user", "content": prompt}],
"temperature": 0.3
};
//リクエストオプション
let options = {
method: "post",
headers: {
"Authorization": "Bearer " + apiKey,
"Content-Type": "application/json"
},
payload: JSON.stringify(payload),
muteHttpExceptions: true
};
//APIにリクエスト
let response = UrlFetchApp.fetch(endpoint2, options);
//修正結果を受け取る
let jsonResponse = JSON.parse(response.getContentText());
//テキストを返却する
return jsonResponse.choices[0].message.content;
}
英訳してSRTとして出力
今回さらにそのまま英訳できるかなと思ったのですが、勝手にタイムスタンプが変わったり、やたら長文に整理されてしまったりしました・・・もうちょっとプロンプトを正しく処理してくれるように修正が必要ですが、以下のような関数でSRTデータを英訳することが可能です。
// 日本語SRTを英語に翻訳(ChatGPT API 使用)
function translateSRT(japaneseSRT, apiKey) {
//リクエストエンドポイント
let endpoint3 = "https://api.openai.com/v1/chat/completions";
//プロンプト
let prompt = `以下のSRT形式の字幕を英語に翻訳してください。
ただし、時間コードや番号はそのままにしてください。\n\n${japaneseSRT}`;
//payloadの構築
let payload = {
"model": "gpt-4",
"messages": [{"role": "system", "content": "You are a professional translator."},
{"role": "user", "content": prompt}],
"temperature": 0.3
};
//リクエストオプション
let options = {
method: "post",
headers: {
"Authorization": "Bearer " + apiKey,
"Content-Type": "application/json"
},
payload: JSON.stringify(payload),
muteHttpExceptions: true
};
//APIリクエスト
let response = UrlFetchApp.fetch(endpoint3, options);
//翻訳結果を受け取る
let jsonResponse = JSON.parse(response.getContentText());
//テキストを返却する
return jsonResponse.choices[0].message.content;
}
関連リンク
- OpenAI Speech to text
- GPT-4o Transcribe・GPT-4o Mini Transcribe・GPT-4o Mini TTS の概要
- OpenAIの自動文字起こし「Whisper API」は1分1円以下! 簡単に使える?
- OpenAI API の Whisper API の使い方
- openai/whisper - Github
- GASで文字起こしする方法(Whisper API/writeout.ai/Speech-to-Text)
- 【Whisper APIで音声入力にも対応!】ChatGPT x GoogleAppsScript(GAS) でお手軽LINEbotを作ってみた
- GASからChatGPTのAPIを呼び出す方法
- GAS(Google Apps Script)でGroqのWhisper-Large-v3 APIを使う方法
- faster-whisper(Whisper-Large-V3)で字幕(srt)をいい感じに作る
- OpenAIからChatGPTとWhisperに関するAPIがリリースされたのでドキュメントを読み解いてみた
- YouTube動画編集のために利用する字幕をOpenAIのwhisper apiを使って生成する
- OpenAI、次世代音声モデルをAPIに導入 ~「親身なカスタマー担当のように話して」も可能
- OpenAI.fm
- 考古学者のためのOpenAI APIを利用した議事録作成
- OpenAIが日本語にも対応した音声文字起こしモデルやテキスト読み上げモデルをリリース、無料で読み上げモデルを試せるデモも登場したので使ってみた
- 【GPT-4o Transcribe/Mini Transcribe】Whisper超え!?OpenAIの次世代音声認識モデルの性能から使い方まで徹底解説

