Cloud Run Functions 第二世代でPuppeteerを動かしてみる - 実践編【GAS】
前回の基礎編では、Cloud Run Function 第2世代上でPuppeteerをとりあえず動かせるようにしました。しかし実際にはあれでは本番のサイトのスクレイピングではまともに動かないでしょう。ここから先は数々の壁が立ちはだかっています。
そこで今回はあるサイトをスクレイピング実行し、xlsxファイルをダウンロードするというだけの処理という実践で必要となった数々の対処法についてまとめました。ダウンロードに当たって一時保存としてCloud Storageが必要になっています。
目次
今回利用する素材
今回の記事は前回の基礎編の続きとなるので、このエントリーでは事前準備として記載してる内容は、前回の環境に対して追加されたものだけを掲載されています。まずは前回記事で環境を準備してから、今回の実践編を御覧ください。
前回の基礎編とはコードやデプロイ周りに大分大きな変更が加わっているため、飛ばしてしまうとついていけない可能性があります。
事前準備
Cloud Storageを用意する
概要
今回、Cloud Run Functions上のPuppeteerでは一旦自身のコンテナの/tmpディレクトリにファイルをダウンロードしています。それをBase64でエンコードしてGAS側に返せばCloud Storageは要らないと思ったのですが、Base64の結果のデータが大きすぎたため、制約に引っかかってしまいました。
そこで、Cloud Storageにやはり格納し、そのURLをGAS側に送りUrlfetchAppでダウンロードさせる正攻法を取っています。この時署名付きURLとすることでGAS側は認証無しで15分間だけファイルをダウンロード出来、またライフサイクル設定で1日でこのファイルは自動消去するようにセットしていますので、GAS側から削除リクエストを不要にしています。
APIを有効化
GASからCloud Storageへのアクセスに対してのAPIの有効化を行います。
- Google Cloud上の対象のプロジェクトを開く
- 左サイドバーからAPIとサービスを開き、上部にある「APIとサービスを有効にする」をクリックする
- Cloud Storage JSON APIを検索して開き、有効化をクリックする
今回は既にプロジェクトで有効化されていたので、これをそのまま利用します。
図:GCSアクセス用APIを有効化
サービスアカウントのロール
Cloud Storageの操作についても、Cloud Run Functions同様にサービスアカウントが必要です。ですが、今回は前述のCloud Run Functionsで作成したサービスアカウントに対して、追加でロールを付与する形で流用しようと思います。
- Google Cloudの対象プロジェクトを開く
- 左サイドバーからIAMと管理を開く
- IAMパネルにおいて、右側下部より対象のサービスアカウントを見つけてクリック
- 鉛筆マークをクリックする
- 今回はバケットの操作ではなく、作成されたファイルの操作なので、「Storage オブジェクト ユーザー」のロールを別途追加して保存する。
- また、GASでリクエスト時にGCF上でGCSのファイルへのURLを生成していますが、署名付きURLで発行する必要があるため、「サービスアカウントトークン作成者」のロールも付与します(iam.serviceAccounts.signBlob)。
バケットを用意する
ここまで準備ができたら、あとはCloud Storage側にバケットを用意します。以下の手順でバケットを用意して、アップロード用コードの為のバケット名を取得しておきます。
- Cloud Consoleにて、Cloud Storageを開き、バケットの作成をクリック
- 名前に半角英数字で命名する。これがバケット名になる。今回は「pupeteer-coassign-bucket」というバケット名をつけました。
- 作成をクリックして完了。
- 今回は特にフォルダを用意せずに直下にファイルを配置するようにしています。
公開アクセスはしませんので注意してください。リージョンもデフォルトのusのままで今回は作成しています。この時つけたバケット名を後述のGASのスクリプトプロパティに格納しておく必要があります。
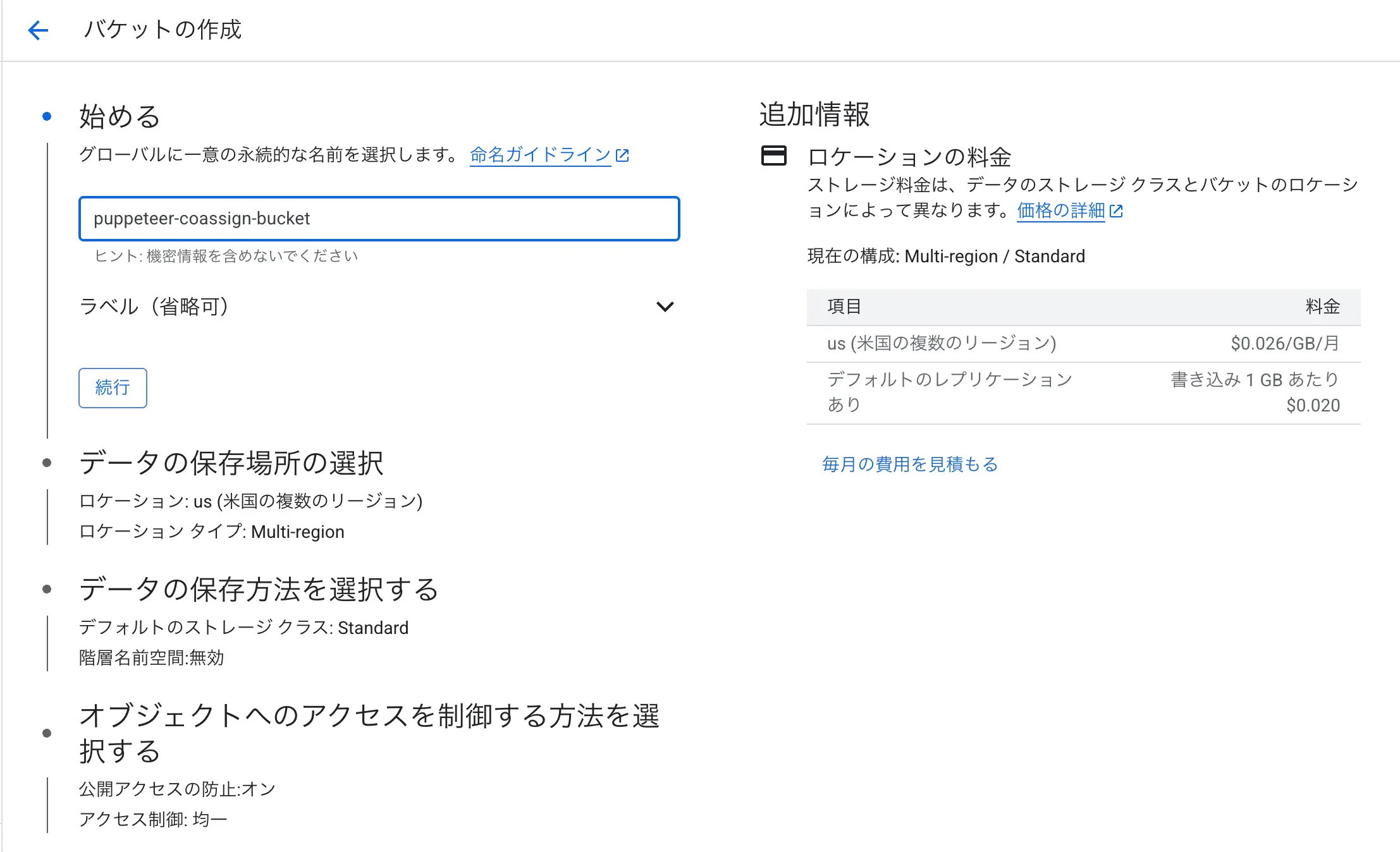
図:バケットを用意しましょう。
ライフサイクル管理設定
/tmpからCloud Storageバケットに配置したファイルは、何もしないとそのまま存在し続けることになります。これではどんどん蓄積してしまうので、本来削除処理が必要です。しかしGAS側から都度削除の実行をするには認証の処理が必要になり結構煩雑。そこで、Cloud Storageのライフサイクル管理設定を使って、自動で1日に1回、バケット内をクリーニングを実行することでこの手間を省いています。以下の手順で、ライフサイクル管理のルールの追加を行います。
- Google CloudのCloud Storageの対象バケットを開く
- タブのライフサイクルをクリックする
- ルールの追加をクリックする
- アクションを選択では「オブジェクトを削除」をクリックする。
- 続行をクリックする
- オブジェクト条件の選択では、経過日数をクリックし日数の数値を1に設定(これで1日となる)
- 続行をクリックする
- 作成をクリックする
これで、オブジェクトが作成されてから1日を経過したものは、ルールに従って自動削除されるようになります。
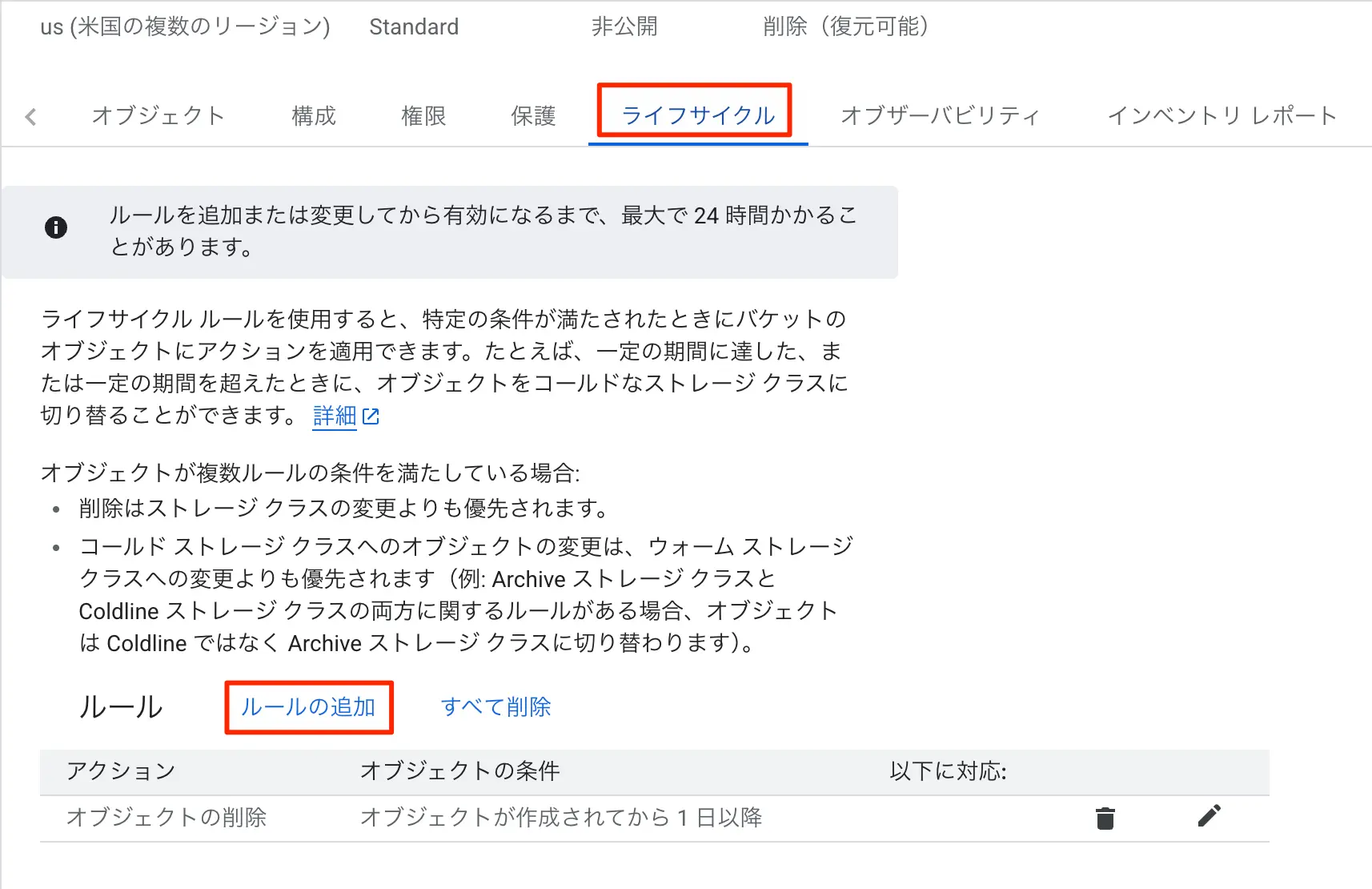
図:1日経過で自動削除のルール
GAS側の準備
スクリプトプロパティに格納
Cloud Storageが加わったことで、GAS側のスクリプトプロパティにも1つ追加が発生しています。
- bucketname : Cloud Storageの用意したバケットの名前を入れる
他、今回のPuppeteerで利用するサイトのログインID, パスワード, レポートの開始日付、レポートの終了日付といったものも今回は追加で入れてあります。
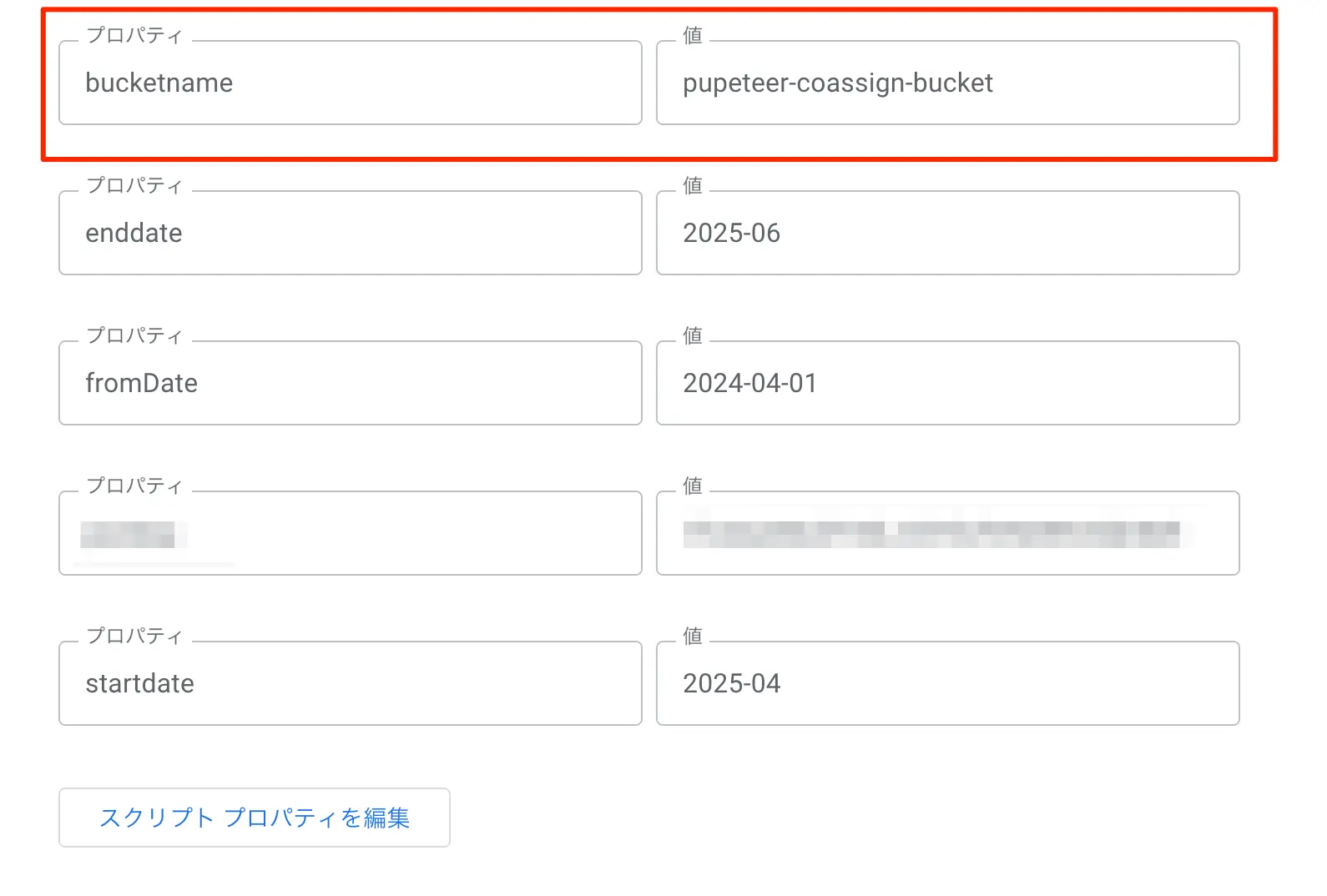
図:bucketnameを入れておく
appsscript.jsonの変更
今回はCloud Storageが加わった結果としていくつかappsscript.jsonも書き換えています。BigQueryやDriveと違ってCloud StorageはGAS側にAdvanced Serviceが存在しないので、https://www.googleapis.com/auth/cloud-platformが必要になってる点に注意が必要です。
"oauthScopes": [
"https://www.googleapis.com/auth/userinfo.profile",
"https://www.googleapis.com/auth/userinfo.email",
"https://www.googleapis.com/auth/script.external_request",
"https://www.googleapis.com/auth/drive",
"https://www.googleapis.com/auth/cloud-platform",
"https://www.googleapis.com/auth/spreadsheets",
"https://www.googleapis.com/auth/script.send_mail",
"https://www.googleapis.com/auth/script.scriptapp"
]
ソースコード
GCF側コード
package.json
新たにCloud Storage操作が加わってるため、パッケージとして@google-cloud/storageが追加になっています。ほかは前回と同じパッケージとなっています。
{
"name": "puppeteer-on-run",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"start": "functions-framework --target=getScraping"
},
"dependencies": {
"@google-cloud/functions-framework": "^3.0.0",
"puppeteer-core": "^22.0.0",
"@google-cloud/storage": "^7.16.0"
}
}
index.js
今回のスクレイピング先サイトはなかなか厄介な仕様になっていて自動化を実現するにはかなり泥臭いアクションが必要でした。Puppeteerを久しぶりに扱ったこともあって、廃止されてるメソッドも多く置き換えが大変でした。
ポイントは以下の通りです。
- Bot対策されてるサイトなのでBot対策用の対策コードが必要です。
- 通常レポート生成直前まではクリック処理が出来ますが、レポート生成ボタンはクリック処理が防御されていますのでキーボードのTabとEnterを駆使して実行させています。
- 冒頭のCORS許可を入れてCloud Run FunctionsへGASでのアクセスを一時的に許可しています。
- /tmpディレクトリは起動時および終了時にそれぞれ完全クリーニングするようにしています。
- 各項目にID属性がなく、Classも毎回ランダムに変更されるので要素の中にある名前で特定してクリックさせています。
- レポート作成を実行してもすぐに作成されず待ちが必要。完了しないとダウンロードボタンが出てこないので、一番上のカードにあるステータス欄がCREATEDやEXECUTEDの時は無限ループするようにしています。
- ダウンロードは古いテクニックである拡張子で判定させる方法を使っています。ストリーム中の情報で行う方法もあるにはあるのですが、ダウンロード完了検知が難しいので使っていません。
- Cloud Storageへ格納後、15分間有効な署名付きURLを生成しています。この値がGAS側でダウンロードさせるのに重要なURLになります(時間は3分くらいに短くしてもイケると思います。GASの連続実行時間上限が6分なので)。
const puppeteer = require('puppeteer-core');
const functions = require('@google-cloud/functions-framework');
const fs = require('fs/promises');
const path = require('path');
const { Storage } = require('@google-cloud/storage');
//GCSを利用する
const storage = new Storage();
//ログイン先URL
const url = "ここにログイン先のURLを入れる";
functions.http('getScraping', async (req, res) => {
//ログイン情報を取得する
//GASから送信されたJSONデータを取得
//functions-frameworkが自動でJSONをパースしてくれるので、req.bodyで直接アクセスできる
const login_id = req.body.login_id;
const password = req.body.password;
const startDate = req.body.startdate;
const endDate = req.body.enddate;
//GCSのバケット名
const BUCKET_NAME = req.body.bucketname; // 事前に作成したGCSバケット名
// (念のため) IDやパスワードが送られてこなかった場合のエラー処理
if (!login_id || !password) {
return res.status(400).send('ログインIDとパスワードが必要です。');
}
//CORSを許可
res.set('Access-Control-Allow-Origin', '*');
if (req.method === 'OPTIONS') {
res.set('Access-Control-Allow-Methods', 'POST');
res.set('Access-Control-Allow-Headers', 'Content-Type');
res.set('Access-Control-Max-Age', '3600');
res.status(204).send('');
return;
}
//ダウンロードパス(インメモリ)
const downloadPath = '/tmp';
//ログイン先URLの指定
let browser;
let page;
let timeoutmin = 300000;
let downloadedFilePath = null; // ダウンロードされたファイルのパスを保存する変数
//tmpディレクトリをクリーンアップ
try {
console.log('Starting pre-cleanup of /tmp directory...');
const files = await fs.readdir(downloadPath);
if (files.length > 0) {
const deletePromises = files.map(file =>
fs.unlink(path.join(downloadPath, file))
);
await Promise.all(deletePromises);
console.log('Pre-cleanup of /tmp complete.');
} else {
console.log('/tmp is already empty.');
}
} catch (preCleanupError) {
// このクリーンアップが失敗しても処理は続行するため、エラーをログに出力するのみ
console.error('Error during pre-cleanup, continuing process...', preCleanupError);
}
try {
//Puppeteerのセットアップ
browser = await puppeteer.launch({
executablePath: '/usr/bin/google-chrome',
headless: "new",
args: [ '--no-sandbox', '--disable-setuid-sandbox', '--disable-dev-shm-usage', '--disable-gpu' ]
});
//ログイン処理
page = await browser.newPage();
//viewportを拡大する
await page.setViewport({ width: 1920, height: 1080 });
//ダウンロード先を/tmpに設定
const client = await page.target().createCDPSession();
await client.send('Page.setDownloadBehavior', {
behavior: 'allow',
downloadPath: downloadPath,
});
//自動化対策に対する対策
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, 'webdriver', {
get: () => false,
});
});
//ログインページへ移動する
await page.goto(url,{ waitUntil: 'networkidle2'});
// IDとパスワードを入力
await page.waitForSelector('#email');
await page.type('#email', login_id);
await page.type('#password', password);
// ログインボタンをクリックして、ページ遷移を待つ
const loginButtonXpath = "//button[contains(., 'ログイン')]";
const loginButton = await page.waitForSelector('xpath/' + loginButtonXpath);
await loginButton.click();
await page.waitForNavigation({ waitUntil: 'networkidle0' }); // ネットワークが落ち着くまで待つ
//指定秒数スリープする
await sleep(18000);
console.log("ログイン完了")
//レポートページへ移動 ---
// 「データレポート」をクリック
const reportLinkXpath = "//a[.//span[contains(text(), 'データ・レポート')]]";
const reportLink = await page.waitForSelector(`xpath/${reportLinkXpath}`);
if (reportLink) {
console.log("データレポートOK");
await reportLink.click();
} else {
throw new Error('「データ・レポート」のリンクが見つかりません。');
}
// 中央に表示されたリストから「リソースレポート」をクリック
console.log('Clicking "リソースレポート" from the list...');
const subMenuXpath = "//h5[contains(text(), 'リソースレポート')]";
const subMenuLink = await page.waitForSelector(`xpath/${subMenuXpath}`);
if (subMenuLink) {
console.log("リソースレポートOK");
await subMenuLink.click();
} else {
throw new Error('リストの「リソースレポート」が見つかりません。');
}
//日付入力欄の処理
const dateInputSelector = 'input.dp__input';
await page.waitForSelector(dateInputSelector);
const dateInputs = await page.$$(dateInputSelector);
if (dateInputs.length >= 2) {
// --- 開始月の入力 ---
const startDateInput = dateInputs[0];
await startDateInput.focus(); // 1. 明示的にフォーカス
await startDateInput.click({ clickCount: 3 }); // 2. 全選択してクリア
await startDateInput.type(startDate); // 3. 入力
console.log("開始日付OK");
//タブで次のフィールドに移動
await page.keyboard.press('Tab');
// --- 終了月の入力 ---
const endDateInput = dateInputs[1];
// Tabキーでフォーカスが当たっているはずなので、そのまま入力操作を行う
await endDateInput.click({ clickCount: 3 });
await endDateInput.type(endDate);
console.log("終了日付OK");
//タブで次のフィールドに移動
await page.keyboard.press('Tab');
//実行ボタンをクリック
await page.keyboard.press('Tab');
console.log('Pressing Enter to execute...');
await page.keyboard.press('Enter');
} else {
throw new Error('Could not find the start and end date inputs.');
}
//実行後すぐにだと古いものをダウンロードするので、1分間ウェイトを掛ける
await sleep(60000)
console.log('Polling for the job to complete...');
const startTime = Date.now();
let latestCompletedCard = null;
while (Date.now() - startTime < timeoutmin) {
// 一番上のカード要素を毎回取得する
const firstCard = await page.$('.mt-10 > .card.mb-5');
let cardText = '';
if (firstCard) {
cardText = await firstCard.evaluate(el => el.textContent);
}
// カードのテキストに「CREATED,EXECUTED」が含まれていたら、作成中なので無限ループ続行
if (cardText.includes('CREATED') || cardText.includes('EXECUTED') ) {
console.log('✅ Found created card.');
await sleep(5000);
continue;
}
// カードのテキストに「COMPLETED」が含まれていたら、それが目的のカード
if (cardText.includes('COMPLETED')) {
console.log('✅ Found COMPLETED card.');
latestCompletedCard = firstCard;
break; // ループを抜ける
}
// 現在のステータスをログに出力して、5秒待機
const currentStatus = cardText.trim().split('\n')[0] || 'N/A';
console.log(`Polling: Top card status is "${currentStatus}". Retrying in 5 seconds...`);
await sleep(5000);
}
if (!latestCompletedCard) {
// タイムアウトした場合のエラー
throw new Error('ジョブが時間内に「COMPLETED」状態になりませんでした。');
}
console.log("Card特定完了")
//ダウンロードボタンを実行
const downloadButton = await latestCompletedCard.waitForSelector('button');
await downloadButton.focus();
await page.keyboard.press('Enter');
console.log("ダウンロード実行開始")
///tmpにファイルダウンロードの待機とクリックを同時に開始
console.log(`Waiting for download to complete in ${downloadPath}...`);
const downloadStartTime = Date.now();
const downloadTimeout = 60000;
while (Date.now() - downloadStartTime < downloadTimeout) {
const files = await fs.readdir(downloadPath);
for (const file of files) {
// .crdownload で終わらず、かつディレクトリではないものを探す
const filePath = path.join(downloadPath, file);
const stat = await fs.stat(filePath);
if (!file.endsWith('.crdownload') && stat.isFile()) {
downloadedFilePath = filePath;
break;
}
}
if (downloadedFilePath) break;
await sleep(1000);
}
if (!downloadedFilePath) {
throw new Error('File download did not complete within 60 seconds.');
}
console.log("ダウンロードOK:" + downloadedFilePath);
//ファイル名を取り出す
const destFileName = path.basename(downloadedFilePath);
//GCSバケットへファイルをアップロードする
await storage.bucket(BUCKET_NAME).upload(downloadedFilePath, {
destination: destFileName,
metadata: {
contentType: 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet',
},
});
console.log(`Uploaded ${downloadedFilePath} to gs://${BUCKET_NAME}/${destFileName}.`);
//署名付きURLの生成(15分間有効)
const options = {
version: 'v4',
action: 'read',
expires: Date.now() + 15 * 60 * 1000,
};
const [signedUrl] = await storage
.bucket(BUCKET_NAME)
.file(destFileName)
.getSignedUrl(options);
console.log('Generated signed URL.');
//finishを使って、レスポンスを返したあとに/tmp内をクリーニングするイベントを先に登録
res.on('finish', async () => {
try {
console.log('Response sent. Starting /tmp cleanup...');
const tempDir = '/tmp';
const files = await fs.readdir(tempDir);
// /tmp内のすべてのファイルを並行して削除
const deletePromises = files.map(file =>
fs.unlink(path.join(tempDir, file))
);
await Promise.all(deletePromises);
console.log('Successfully cleaned up all files in /tmp.');
} catch (cleanupError) {
// クリーンアップ中のエラーはコンソールに出力するのみ
console.error('Error during /tmp cleanup:', cleanupError);
}
});
//レスポンスを返す
res.status(200).json({
success: true,
message : "File uploaded and signed URL created successfully.",
mimeType: 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet',
downloadfilepath: downloadedFilePath,
filename : destFileName,
downloadUrl: signedUrl
});
} catch (error) {
console.error("エラー発生:", error.message);
res.status(400).json({
error: "制御されたエラーが発生しました。",
details: error.message,
});
} finally {
//ブラウザ終了処理
if (browser) {
await browser.close();
console.log('ブラウザをクローズしました。');
}
// /tmp の一時ファイルを削除
if (downloadedFilePath) {
try {
await fs.unlink(downloadedFilePath);
console.log(`Cleaned up temporary file: ${downloadedFilePath}`);
} catch (unlinkError) {
console.warn(`Failed to clean up temporary file: ${unlinkError.message}`);
}
}
}
});
//スリープ用関数
function sleep(milliSeconds) {
return new Promise((resolve, reject) => {
setTimeout(resolve, milliSeconds);
});
}
GAS側コード
処理としてはGCFのエンドポイントに対して、Puppeteerが必要としてるログイン情報やバケット名を付与した状態でリクエストを実行し、PuppeteerがCloud Storageにファイルを格納後に返してくる15分間有効な「署名付きURL」をもってダウンロードを実行。
ドライブにファイルを保存したら完了というコードになります。
署名付きURLなのでAccess Tokenは不要でアクセスが可能となるので、今回は前回のCloud Storageへアップロードする記事と異なり、認証不要ですのでOAuth2ライブラリなども不要にしています。
//Cloud Functionsの関数を実行する
function run_gcffunction() {
//スクリプトプロパティからログイン情報を取得
const prop = PropertiesService.getScriptProperties();
const loginId = prop.getProperty('LOGIN_ID');
const password = prop.getProperty('LOGIN_PASSWORD');
const startdate = prop.getProperty('startdate');
const enddate = prop.getProperty('enddate');
//バケット名を取得する
const bucketname = prop.getProperty('bucketname');
//idtokenを取得する
let idtoken = ScriptApp.getIdentityToken();
//ログイン情報をまとめる
const payload = {
'login_id': loginId,
'password': password,
'startdate' : startdate,
'enddate' : enddate,
'bucketname' : bucketname
};
//リクエストヘッダを構築
let header = {
Authorization: "Bearer " + idtoken
}
//リクエストオプション
const options = {
'method': 'POST',
'headers': header,
'contentType': 'application/json',
'payload': JSON.stringify(payload),
'muteHttpExceptions': true
};
//POSTで関数を実行する
const response = UrlFetchApp.fetch(pturl, options);
//サーバーレスポンスコードを取得する
let resCode = response.getResponseCode();
//リターンされて来たURLを取得する
if (resCode === 200) {
//レスポンスデータを取り出す
const data = JSON.parse(response.getContentText());
//署名付きURL等の情報を取得する
const downloadUrl = data.downloadUrl;
const filename = data.filename;
//署名付きURLリクエストを実行してBlobで取得
//署名付きなのでリクエストのトークンは不要
const fileBlob = UrlFetchApp.fetch(downloadUrl).getBlob();
//所定のダウンロードフォルダにファイルを生成
const downfileid = DriveApp.getFolderById(folderid).createFile(fileBlob).setName(filename).getId();
//終了処理
console.log(resCode + ": ダウンロード完了" + downfileid) ;
return true;
}else{
console.log(resCode + "エラーが発生しました。");
const errorResponseText = response.getContentText();
console.log(errorResponseText);
return false;
}
}
デプロイと実行
前回同様コードを変更したらgcloudコマンドでデプロイするのですが、前回と違って大きなポイントがあります。Cloud Run Functionsのデフォルトの連続実行時間は30秒でタイムアウトするようになっています。これではPuppeteerで使うには短すぎる。ということで、デプロイ時にタイムアウト時間の変更を加えてデプロイする必要があります。
2行目のdeployコマンドで --timeout=300とすることで300秒にまでタイムアウト時間を拡大させています。これが重要です。
gcloud builds submit --tag gcr.io/GCFを動かしてるプロジェクトの名前/GCFのプロジェクト名 gcloud run deploy puppeteer-coassign --image gcr.io/GCFを動かしてるプロジェクトの名前/GCFのプロジェクト名 --region=us-central1 --timeout=300