ElectronでNFCを使った書籍貸出管理を作ってみる - 書籍検索編
前回のElectronでNFCを使った書籍の貸し出し・返却機能を持ったアプリケーションを作成しました。しかし、このアプリケーションはまだ新規に書籍を登録したり廃棄したりする機能が備わっていません。MySQLへ手動で登録するというのもスマートじゃない。
そこで今回は、新しく購入してきた書籍のISBNコードを読み取って、国会図書館および楽天ブックスAPIの2つを持って、書籍情報を取得。データベースへ登録する機能を搭載したいと思います。基本的にはこのエントリーの移植であり、REST APIを叩いて得たデータをInsert Intoで入れるまでを行います。
今回の検索画面の検索結果テーブルのデザインは、こちらのサイトのCSSをお借りしました。
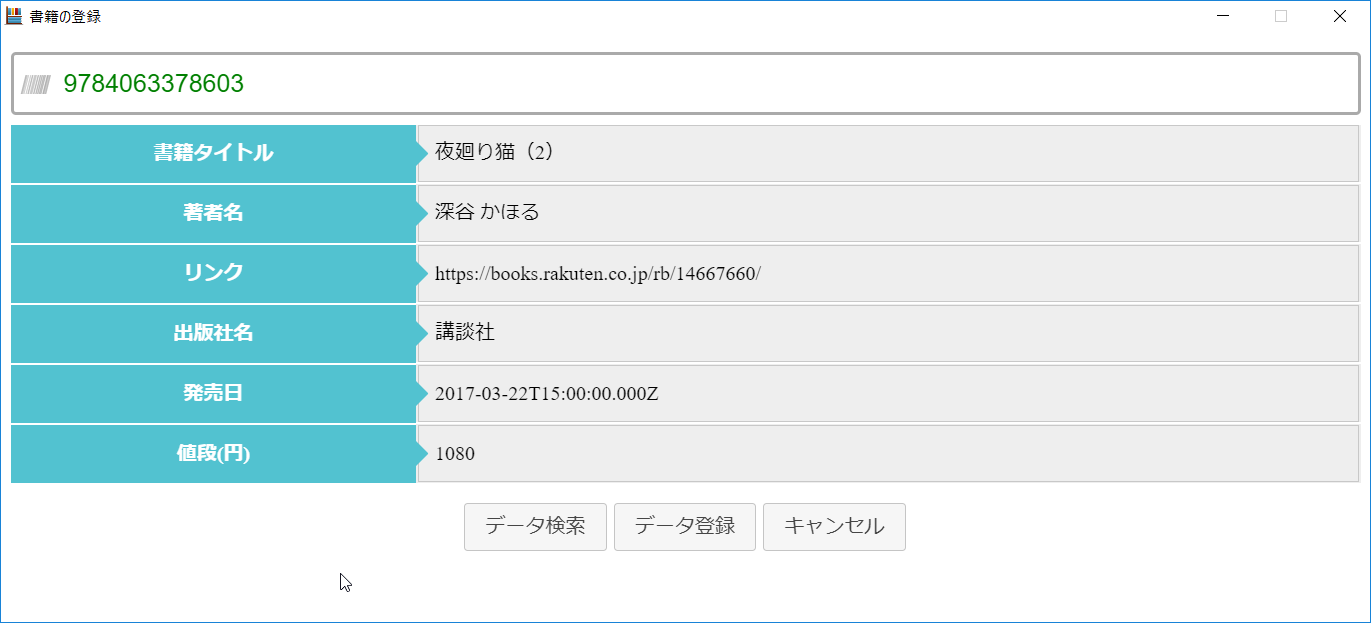
図:ISBNで検索して情報を取得->DB登録する流れ
今回使用するモジュールやサービス
使用するサービス
カードリーダーとドライバー
Node.jsモジュール
HTML側で利用するライブラリ
requestモジュールについて
モジュールの追加
今回は前回の続きであるので、主役であるrequestモジュールを追加します。また、社内で利用する事から「プロキシー」を経由する事を想定し、利用する場合には事前に通過するプロキシーサーバのアドレスとポート番号が必要になります。
モジュールの追加自体は非常に簡単。特別なことをせずともインストールするだけで利用する事が可能です。
※2019年4月15日 - requestモジュールが今後のアップデートをしないメンテナンスモード(修正のみ)へと移行されるようです。別のモジュールへ移行を促すか?非推奨にするかをIssueにて議論されているようです(すぐに使えなくなるとか、消えてなくなるという事ではない)。代替モジュールについての議論はこちらでなされているようです。
npm i request
また、同期的に処理が必要だという方は、requestをPromise化したモジュールもあります。その場合は、
npm i request-promise
で、導入する事が可能です。
通常のアクセスとプロキシー経由のアクセス
特にプロキシーサーバを経由する事がない場合には以下のようなコードで通信をすることが可能です。
//HTTPリクエスト用モジュールの読み込み
var request = require('request');
function kokkaibook(args,callback){
//返す変数用
var retman = {};
//オプション設定
var options = {
url: "http://iss.ndl.go.jp/api/opensearch?isbn=" + args,
method: 'GET'
}
//HTTPリクエスト実行
request(options, function (error, response, body) {
//エラー発生時
if (error) {
console.log("接続エラー");
retman.status = "ERR";
retman.error = error;
callback(retman);
return;
}
console.log(body);
//値はXMLで取得される
console.log("OK");
retman.status = "OK";
retman.recman = body;
callback(retman);
return;
});
}
しかし、プロキシー経由でなければ外に出られない場合には、モジュールの読み込み後にProxy設定を追加し、その設定で通信を行う必要があります。
//HTTPリクエスト用モジュールの読み込み
var request = require('request');
//プロキシー設定
var proxy = request.defaults({'proxy':'プロキシーのアドレスとポート'})
//国会図書館データ検索
function kokkaibook(args,callback){
//返す変数用
var retman = {};
//オプション設定
var options = {
url: "http://iss.ndl.go.jp/api/opensearch?isbn=" + args,
method: 'GET'
}
//HTTPリクエスト実行(プロキシー経由)
proxy.get(options, function (error, response, body) {
//エラー発生時
if (error) {
console.log("接続エラー");
retman.status = "ERR";
retman.error = error;
callback(retman);
return;
}
console.log(body);
//値はXMLで取得される
console.log("OK");
retman.status = "OK";
retman.recman = body;
callback(retman);
return;
});
}
- request.defaultsにプロキシーのアドレスとポートを指定する
- proxy.getにて通信を行う。
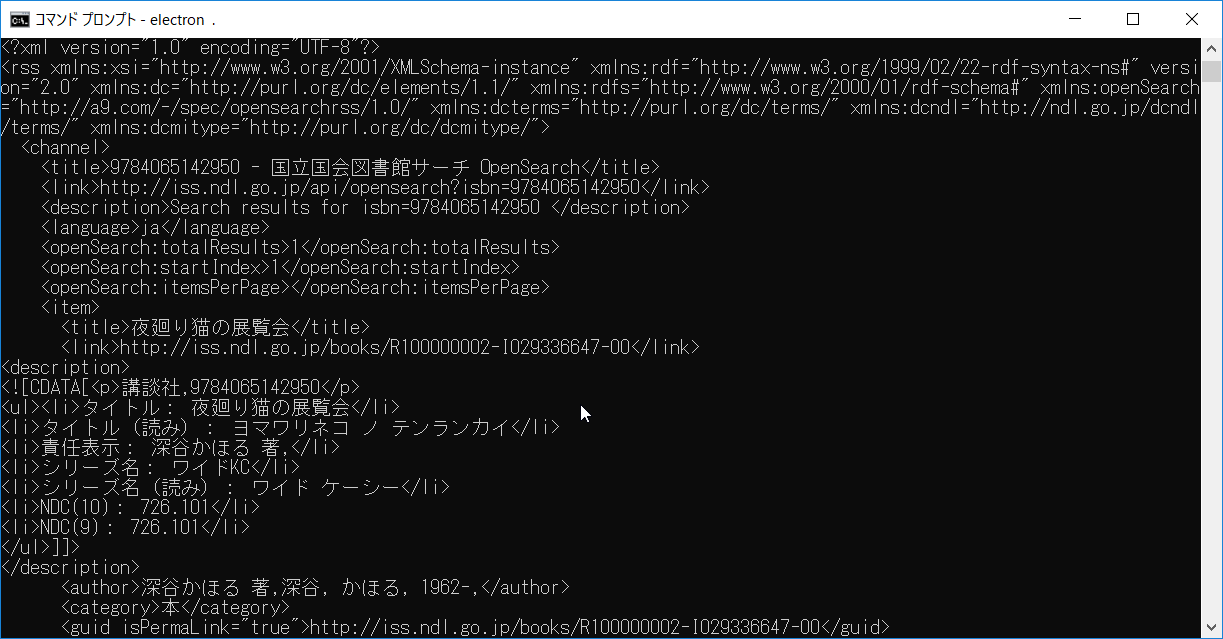
図:きちんとアクセスできた場合
ヘッダーとオプション設定について
HTTPリクエストではこれまでもGoogle Apps ScriptやVBAでも紹介してきたように「オプション設定」と「リクエストヘッダー情報」が付き物です。Node.js上のrequestモジュールでもそれは同じ。
ヘッダーについては以下のような記述を行います。ヘッダー指定も基本マニュアルに記載がありますが、省かれている雑なマニュアルもあるので注意が必要です。
var headers = {
'Content-Type':'application/json',
'Content-Type':'application/x-www-form-urlencoded'
'Authorization':'Bearer '+ token
}
特に「REST APIを叩く」場合には、OAuth2.0認証を利用し、access tokenを持って通信を行う事が非常に多いです。その場合のヘッダー情報が「Authorization」であり、Bearerに続けて、Access Tokenの値を繋げて渡します。但しこのAccess Tokenを取得する為のルーチンや、tokenが時間切れかどうかチェックするコード、token時間切れ時にRefresh Tokenを使って再度Access Tokenを取得するなどのコードもまた必要になる事が多いです。
さらにオプション設定では以下のような記述を行います。その際にoptionsにheadersを加えることをお忘れなく。
var options = {
url: '相手のサーバのエンドポイントURL',
method: 'POST',
headers: headers,
json: true
}
エンドポイントURLとは、その操作(例えばドライブでファイル操作をするといった事例)の時に使用するURLで、マニュアルに記載が必ずあります。Google Drive API v2の事例で言えば、https://www.googleapis.com/drive/v2がエンドポイントURLとなります。機能別に複数わけられているケースもあれば、1つのエンドポイントでオプション指定で分けていることもあります。
methodは通常はPOST、GETのどちらかですが、例えばBox APIなどの場合には、PUTやPATCH、DELETEといったメソッドもあります。基本どれも使いて側からしたらメソッド名が変わるくらいで同じですが、これについても相手側サーバのマニュアルに使うべきメソッドの指定があります。
検索するメインルーチン
国会図書館APIの検索と結果
モジュールの追加
今時のウェブサービスの場合、基本的に送信も受信もデータについては「JSON形式」でやり取りが可能なので、JavaScriptの場合非常に簡単に複雑な構造のデータであっても取り扱いが可能です。しかし、前時代のウェブサービスの場合、JSON形式ではなくXML形式でしか対応していないケースが多く、このXMLは構造が非常に複雑で取り扱いも非常に面倒な形式です。
そこで、XMLでパースするのではなくJSONに変換して楽々取得するためのモジュールを追加しておきます。インストール時にnode-gypによるリビルドが発生しますので、きちんとnode-gypが動いている環境である必要があります。
npm i xml2json --save
また、このモジュールはそのままではelectronで利用できないので、electron-rebuildにてネイティブ環境用にリビルドする必要があります。
- プロジェクトフォルダに入る
- electron-rebuild -w xml2jsonを実行する
- リビルドが完了したら成功
変換するためのコード
まずは取り込む為のコードです。国会図書館サーチAPIで夜回り猫を探索するとこんな感じで返ってくる。
//国会図書館データ検索
function kokkaibook(args,callback){
//返す変数用
var retman = {};
var retval = {};
//オプション設定
var options = {
url: "http://iss.ndl.go.jp/api/opensearch?isbn=" + args,
method: 'GET'
}
//HTTPリクエスト実行(プロキシー経由)
proxy.get(options, function (error, response, body) {
//エラー発生時
if (error) {
console.log("接続エラー");
retman.status = "ERR";
retman.error = error;
callback(retman);
return;
}
//XML形式をJSON形式に変換(JSON.parseしないとだめだよ)
var json = JSON.parse(parser.toJson(body));
//変換した結果から必要なものをピックアップ
var element = json.rss.channel.item;
//必要な値だけを取り出す
retval.title = element.title;
retval.author = element.author;
retval.link = element.link;
retval.pubname = element["dc:publisher"];
retval.saleday = element.pubDate;
retval.price = element["dcndl:price"];
//値はXMLで取得される
console.log("OK");
retman.status = "OK";
retman.recman = retval;
callback(retman);
return;
});
}
- parser変数にxml2jsonモジュールを読み込みます。
- APIを叩いた結果返ってきたXMLデータをparser.toJson(body)という形で変換しjson変数に格納しています。この時点ですでにJSON化されています。
XMLがどのようにJSONに変換されるか
夜回り猫という面白い本があるのですが、これを国会図書館で検索してみました。まずは普通にXMLで返ってきた値を見てみます。
<?xml version="1.0" encoding="UTF-8"?>
<rss xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:openSearch="http://a9.com/-/spec/opensearchrss/1.0/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dcndl="http://ndl.go.jp/dcndl/terms/" xmlns:dcmitype="http://purl.org/dc/dcmitype/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" version="2.0">
<channel>
<title>9784065142950 - 国立国会図書館サーチ OpenSearch</title>
<link>http://iss.ndl.go.jp/api/opensearch?isbn=9784065142950</link>
<description>Search results for isbn=9784065142950 </description>
<language>ja</language>
<openSearch:totalResults>1</openSearch:totalResults>
<openSearch:startIndex>1</openSearch:startIndex>
<openSearch:itemsPerPage></openSearch:itemsPerPage>
<item>
<title>夜廻り猫の展覧会</title>
<link>http://iss.ndl.go.jp/books/R100000002-I029336647-00</link>
<description>
<![CDATA[<p>講談社,9784065142950</p>
<ul><li>タイトル: 夜廻り猫の展覧会</li>
<li>タイトル(読み): ヨマワリネコ ノ テンランカイ</li>
<li>責任表示: 深谷かほる 著,</li>
<li>シリーズ名: ワイドKC</li>
<li>シリーズ名(読み): ワイド ケーシー</li>
<li>NDC(10): 726.101</li>
<li>NDC(9): 726.101</li>
</ul>]]>
</description>
<author>深谷かほる 著,深谷, かほる, 1962-,</author>
<category>本</category>
<guid isPermaLink="true">http://iss.ndl.go.jp/books/R100000002-I029336647-00</guid>
<pubDate>Fri, 14 Dec 2018 09:00:00 +0900</pubDate>
<dc:title>夜廻り猫の展覧会</dc:title>
<dcndl:titleTranscription>ヨマワリネコ ノ テンランカイ</dcndl:titleTranscription>
<dc:creator>深谷, かほる, 1962-</dc:creator>
<dcndl:creatorTranscription>フカヤ, カオル</dcndl:creatorTranscription>
<dcndl:seriesTitle>ワイドKC</dcndl:seriesTitle>
<dcndl:seriesTitleTranscription>ワイド ケーシー</dcndl:seriesTitleTranscription>
<dc:publisher>講談社</dc:publisher>
<dcterms:issued xsi:type="dcterms:W3CDTF">2018</dcterms:issued>
<dcndl:price>1350円</dcndl:price>
<dc:extent>93p ; 21cm</dc:extent>
<dc:identifier xsi:type="dcndl:ISBN">9784065142950</dc:identifier>
<dc:identifier xsi:type="dcndl:NDLBibID">029336647</dc:identifier>
<dc:identifier xsi:type="dcndl:JPNO">23144077</dc:identifier>
<dc:identifier xsi:type="dcndl:TOHANMARCNO">07418438</dc:identifier>
<dc:subject>夜廻り猫 (漫画)</dc:subject>
<dc:subject xsi:type="dcndl:NDLC">KC486</dc:subject>
<dc:subject xsi:type="dcndl:NDC10">726.101</dc:subject>
<dc:subject xsi:type="dcndl:NDC9">726.101</dc:subject>
<dc:description>NDC(9版)はNDC(10版)を自動変換した値である。</dc:description>
<rdfs:seeAlso rdf:resource="http://id.ndl.go.jp/bib/029336647"/>
</item>
</channel>
</rss>
いわゆる名前空間などが設定されていて、一見すると簡単に取れそうに見えますが、ものすごく面倒臭いです。これをxml2jsonを経由させた場合の値は以下のようになります。
{"rss":
{
"xmlns:dcterms":"http://purl.org/dc/terms/",
"version":"2.0",
"xmlns:dc":"http://purl.org/dc/elements/1.1/",
"xmlns:xsi":"http://www.w3.org/2001/XMLSchema-instance",
"xmlns:rdf":"http://www.w3.org/1999/02/22-rdf-syntax-ns#",
"xmlns:dcndl":"http://ndl.go.jp/dcndl/terms/",
"xmlns:rdfs":"http://www.w3.org/2000/01/rdf-schema#",
"xmlns:openSearch":"http://a9.com/-/spec/opensearchrss/1.0/",
"xmlns:dcmitype":"http://purl.org/dc/dcmitype/",
"channel":
{
"title":"9784065142950 - 国立国会図書館サーチ OpenSearch",
"link":"http://iss.ndl.go.jp/api/opensearch?isbn=9784065142950",
"description":"Search results for isbn=9784065142950",
"language":"ja",
"openSearch:totalResults":"1",
"openSearch:startIndex":"1",
"openSearch:itemsPerPage":{},
"item":
{
"title":"夜廻り猫の展覧会",
"link":"http://iss.ndl.go.jp/books/R100000002-I029336647-00",
"description":"<p>講談社,9784065142950</p>\n<ul><li>タイトル: 夜廻り猫の展覧会</li>\n<li>タイトル(読み): ヨマワリネコ ノ テンランカイ</li>\n<li>責任表示: 深谷かほる 著,</li>\n<li>シリーズ名: ワイドKC</li>\n<li>シリーズ名(読み): ワイド ケーシー</li>\n<li>NDC(10): 726.101</li>\n<li>NDC(9) : 726.101</li>\n</ul>",
"author":"深谷かほる 著,深谷, かほる, 1962-,",
"category":"本",
"guid":
{
"isPermaLink":"true",
"$t":"http://iss.ndl.go.jp/books/R100000002-I029336647-00"
},
"pubDate":"Fri, 14 Dec 2018 09:00:00 +0900",
"dc:title":"夜廻り猫 の展覧会",
"dcndl:titleTranscription":"ヨマワリネコ ノ テンランカイ",
"dc:creator":"深谷, かほる, 1962-","dcndl:creatorTranscription":"フカヤ, カオル",
"dcndl:seriesTitle":"ワイドKC",
"dcndl:seriesTitleTranscription":"ワイド ケーシー",
"dc:publisher":"講談社",
"dcterms:issued":
{
"xsi:type":"dcterms:W3CDTF",
"$t":"2018"
},
"dcndl:price":"1350円",
"dc:extent":"93p ; 21cm",
"dc:identifier":
[{
"xsi:type":"dcndl:ISBN",
"$t":"9784065142950"
},
{
"xsi:type":"dcndl:NDLBibID",
"$t":"029336647"
},
{
"xsi:type":"dcndl:JPNO",
"$t":"23144077"
},
{
"xsi:type":"dcndl:TOHANMARCNO",
"$t":"07418438"
}],
"dc:subject":
[
"夜廻り猫 (漫画)",
{
"xsi:type":"dcndl:NDLC",
"$t":"KC486"
},
{
"xsi:type":"dcndl:NDC10",
"$t":"726.101"
},
{
"xsi:type":"dcndl:NDC9",
"$t":"726.101"
}
],
"dc:description":"NDC(9版)はNDC(10版)を自動変換した値である。",
"rdfs:seeAlso":
{
"rdf:resource":"http://id.ndl.go.jp/bib/029336647"
}
}
}
}
}
- rssから始まり、各エレメントが見事にJSON構造になっています。
- 各エレメントの文字列をそのままJSONとして指定すれば取れるので、めちゃくちゃ楽です。
- キー名にコロンを含んだものがあるので、この場合には、例えばdc:publisherの値を取りたい場合には、json.rss.channel.item["dc:publisher"]といった形で指定すればJSONから値を取得可能です。XMLだとここがひどく面倒
楽天ブックスAPIで検索した結果
楽天ブックスAPIはJSON形式で返ってくるので非常に楽です。リクエストの方式もシンプルなので、それほど難儀せずにコードを組み立てることが可能です。
楽天ブックスAPI側の準備

データを取得する為のコード
//楽天ブックスAPI検索
function rakutenbook(args,callback){
//楽天ブックスAPI関係
var appid = "ここにAPI IDを入力してください。";
var rakutenurl = "https://app.rakuten.co.jp/services/api/BooksBook/Search/20170404?applicationId="
//URLを組み立てる
var sURL = rakutenurl + appid + "&isbn=" + encodeURIComponent(args);
//返す変数用
var retman = {};
var retval = {};
//オプション設定
var options = {
url: sURL,
method: 'GET'
}
//HTTPリクエスト実行(プロキシー経由)
proxy.get(options, function (error, response, body) {
if (!error && response.statusCode == 200) {
//変換した結果から必要なものをピックアップ
var element = JSON.parse(body);
//検索結果が0件の場合はエラーとして処理
if(element.count == 0){
console.log("件数が0件");
retman.status = "ERR";
retman.error = "件数が0件";
callback(retman);
return;
}
//変換した結果から必要なものをピックアップ
var elm = element.Items[0].Item;
//書籍のタイトル
if(elm.title == undefined){
retval.title = "名無し"
}else{
retval.title = elm.title;
}
//著者名
if(elm.author == undefined){
retval.author = "名無し"
}else{
retval.author = elm.author;
}
//リンク
if(elm.itemUrl == undefined){
retval.link = "リンク先なし"
}else{
retval.link = elm.itemUrl;
}
//出版社名
if(elm.publisherName == undefined){
retval.pubname = "出版社記載なし"
}else{
retval.pubname = elm.publisherName;
}
//発売日
if(elm.salesDate == undefined){
retval.saleday = ""
}else{
var elmday = elm.salesDate;
elmday = elmday.replace("年","/");
elmday = elmday.replace("月","/");
elmday = elmday.replace("日","");
var tempday = new Date(elmday);
retval.saleday = tempday;
}
//価格
if(elm.itemPrice == undefined){
retval.price = "価格記載なし"
}else{
//特定文字列の置き換えを実行する
retval.price = elm.itemPrice;
}
//JSON形式で値を返す
retman.status = "OK";
retman.recman = retval;
callback(retman);
return;
}else{
//エラー発生時
console.log("接続エラー");
retman.status = "ERR";
retman.error = error;
callback(retman);
return;
}
});
}
ISBNで検索した結果
{
"count":1,
"page":1,
"first":1,
"last":1,
"hits":1,
"carrier":0,
"pageCount":1,
"Items":
[{
"Item":
{
"title":"夜廻り猫(2)",
"titleKana":"ヨマワリネコ2",
"subTitle":"",
"subTitleKana":"",
"seriesName":"ワイドKC",
"seriesNameKana":"ワイドKCコミックス",
"contents":"",
"author":"深谷 かほる",
"authorKana":"フカヤ カオル",
"publisherName":"講談社",
"size":"コミック",
"isbn":"9784063378603",
"itemCaption":"",
"salesDate":"2017年03月23日",
"itemPrice":1080,
"listPrice":0,
"discountRate":0,
"discountPrice":0,
"itemUrl":"https://books.rakuten.co.jp/rb/14667660/",
"affiliateUrl":"",
"smallImageUrl":"https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/8603/9784063378603.jpg?_ex=64x64",
"mediumImageUrl":"https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/8603/9784063378603.jpg?_ex=120x120",
"largeImageUrl":"https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/8603/9784063378603.jpg?_ex=200x200",
"chirayomiUrl":"",
"availability":"1",
"postageFlag":0,
"limitedFlag":0,
"reviewCount":37,
"reviewAverage":"4.83",
"booksGenreId":"001001012"
}
}],
"GenreInformation":[]
}
データを登録するコード
すでに登録済みの本かどうか、ISBNコードでチェックを掛けてから、フォームデータをもとにMySQLへ登録します。今回は必要な個所だけコードを記載しています。
//MySQL読み書き用
ipcMain.on('async', function( event, args, args2){
//引数に応じて処理を分岐
switch(args){
case "savebook":
//書籍を登録する
bookregister(args2,function (ret){
var json = ret;
switch(json.status){
case "NOSET":
//接続設定がないため繋がなかった場合の処理
event.sender.send('retmsg', "DB接続設定がありませんよ");
break;
case "ERR":
//エラーメッセージを表示
event.sender.send('retmsg', json.error);
break;
case "OK":
//登録結果を返す
event.sender.send('bookregend', json.msg);
break;
}
});
break;
}
});
//書籍を登録するルーチン
function bookregister(arg,callback){
//変数を宣言
var connection;
var retman = {};
var result = "";
var pass = [];
//引数より登録用の値を取得する
var isbn = arg[0];
var title = arg[1];
var author = arg[2];
var publisher = arg[4];
var sellday = arg[5];
var price = arg[6];
//サービス名を構築する
var servicename = "bookman_" + store.get("id");
//接続設定があるかないか判定
if(store.get("id") == "undefined" || store.get("id") == null){
//エラーでコールバックさせる
retman.status = "NOSET";
callback(retman);
return;
}
var secret = keytar.getPassword(servicename,store.get("id"));
secret.then((result) => {
//パスワードを取得する
pass = result;
//MySQLに接続してデータを取得する
//createConnectionでは接続が時々切れる
mysql.createConnection({
host: store.get("server"),
port: 3306,
user: store.get("id"),
password: pass,
database: "mhr"
}).then(function(conn){
//書籍が登録済みかどうかチェック
connection = conn;
//該当のIDでの登録数が何件かしらべる
var result = connection.query("SELECT * FROM mhr.bookmaster where isbn = " + isbn + ";");
return result;
}).then(function(rows){
//データ件数を取得する
var dlength = rows.length;
if(dlength == 0){
//貸し出し履歴を追加する
var result = connection.query('insert into mhr.bookmaster (isbn,title,author,publisher,sellday,price) values (?,?,?,?,?,?);',
[isbn,title,author,publisher,sellday,price],
(err,result)=> {
//エラーが発生した場合
if (err) {
console.log("接続エラー");
retman.status = "ERR";
retman.error = err;
console.log(err);
connection.end();
callback(retman);
return;
}
//取得データを返す
retman.status = "OK";
retman.msg = "書籍の登録が完了しました。";
callback(retman);
connection.end();
return;
}
);
}else{
retman.status = "ERR";
retman.error = "対象の書籍はすでに登録済みみたいですよ。";
callback(retman);
connection.end();
return;
}
}).catch(function(error){
if (connection && connection.end) connection.end();
//logs out the error
retman.status = "ERR";
retman.error = "接続エラーですよ。パスワードが違うとかサーバアドレス間違ってるとか、ありませんか?";
callback(retman);
return;
});
});
}
