Puppeteerで特定サイトのスクショを定期的に取得
Puppeteerシリーズで特定のジャンルで需要がありそうなのが「定期的に実行」系。しかし、通常のPuppeteerでは一回実行して完了したらそれで終了です。この定期実行は、特定サイトのデータを定期的にCSVでダウンロードしておくであったり、また、特定サイトの情報を定期的にスクレイピングなど、使い所は結構あります。
今回はGoogle Mapsの特定のポイントのスクリーンショットを定期的に取得するタイプのものを作ってみました。xlsxに記述したURLを取り込み、10分毎にそれらのスクショを撮るというものです。
※保存場所をGoogle Drive File Streamの場所に指定すれば、Google Driveへのアップロードも自動化になるので、Google Apps Scriptでスクレイピングするよりずっと効果的だと思います。
目次
今回使用するモジュール等
- puppeteer-core – npm
- date-utils - npm
- node-cron - npm
- xlsx-populate-wrapper - npm
- nexe – npm
- 今回使用するリストファイル - xlsx
今回は定期的にpuppeteerを起動させるためにNode-Cronを必要としています。これで10分置きに、xlsxファイルを読み取って、サイトへ移動しながら、スクリーンショットを取り続けるプログラムです。また、Excelデータを読み込ませるためのモジュールも必要です。
今回の操作上の問題点
今回の要件は、特定サイトのスクショを定期的に取り続けることなので、
- リストになるxlsxファイルを必要とし、
- また、定期的に実行するので、Cronが必要になります。
過去にもNode.jsでNode-Cronを取り扱ったことがありましたが、そのままPuppeteerでも利用し、10分置きにスクリーンショットをバンバン撮っていくスタイルなので、自分でコマンドプロンプトを閉じない限り稼働し続けます。
また、ファイル名で利用する日付の生成ですが、getFullYearなどとやってると面倒なので、今回よりdate-utilsモジュールを使って、new Date()を拡張するようにしました。
図:こんな感じでファイルが生成され続ける
URLリスト用のExcelファイルについて
URLリストを記述しておくExcelファイルは単純な構成で、シート名は登録リストとし、IDと場所名、Google MapsのURLを入れてあります。このIDと取得時の日時でファイル名を設定し、バンバン取得していく感じになります。
デスクトップに配置し、同じくデスクトップにsnapshotフォルダを作っておきましょう。
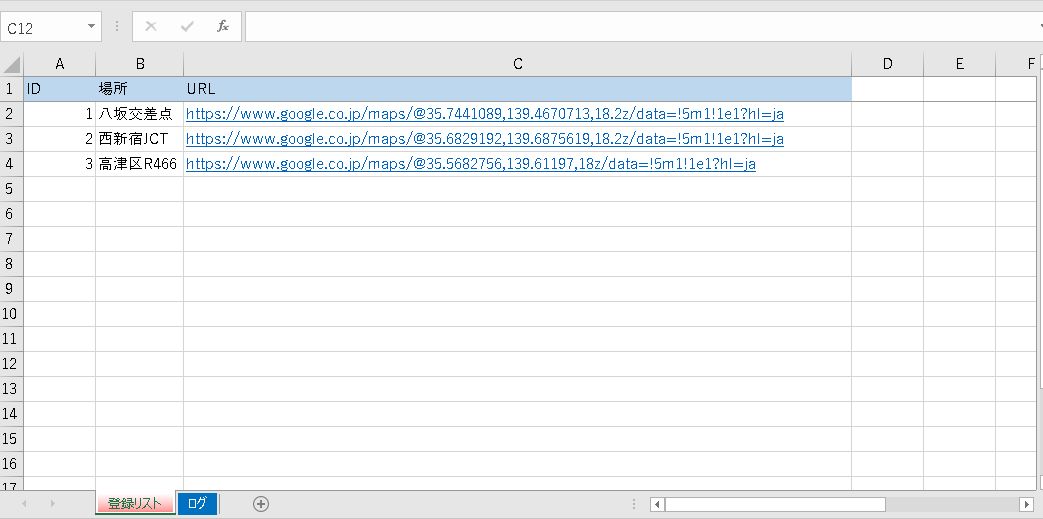
図:IDは連番で振ります
ソースコード
冒頭部分
//使用するモジュール
const puppeteer = require('puppeteer-core');
var fs = require('fs');
const path = require("path");
var shell = require('child_process').exec;
var spawnSync = require('child_process').spawnSync;
require('date-utils');
var CronJob = require('node-cron');
var jobs;
//デスクトップのパスを取得
var dir_home = process.env[process.platform == "win32" ? "USERPROFILE" : "HOME"];
var deskpath = require("path").join(dir_home, "Desktop");
//snapshot保存場所
var snapdir = deskpath + "//snapshot//";
//オープンするURL
var url = "https://www.google.co.jp/maps/?hl=ja";
//Excelファイルをロードする
//冒頭部分
const xlsxpop = require("xlsx-populate-wrapper");
//Excelファイルをロードする
var xlsxfile = deskpath + "//list.xlsx";
const workbook = new xlsxpop(xlsxfile);
//Chromeのパスを取得(ユーザ権限インストール時)
const userHome = process.env[process.platform == "win32" ? "USERPROFILE" : "HOME"];
var kiteipath = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe";
var temppath = path.join(userHome, "AppData\\Local\\Google\\Chrome\\Application\\chrome.exe");
//chrome場所判定
if(fs.existsSync(kiteipath)){
var chromepath = kiteipath
console.log("プログラムフォルダにChromeみつかったよ");
}else{
if(fs.existsSync(temppath)){
var chromepath = temppath;
console.log("ユーザディレクトリにChrome見つかったよ");
}else{
console.log("chromeのインストールが必要です。");
//IEを起動してChromeのインストールを促す
shell('start "" "iexplore" "https://www.google.co.jp/chrome/"')
return;
}
}
//Node-Crons設定(10分置きに実行)
var cronTime = "*/10 * * * *";
//引数の分を元に、分単位トリガーを設置する
jobs = CronJob.schedule(cronTime, () => {
//メインの作業実行
main();
});
- date-utilsモジュールはrequireするだけでnew Date()を拡張してくれるので、変数等に格納は不要です。
- snapshot用のディレクトリ、xlsxファイルの指定等は決め打ちです。
- xlsx-populate-wrapperにて、xlsxデータをJSONで取得し操作するようにしています。
- cronTimeにて上記のコードのように指定すると10分置きに実行という指定になります。最後にCronJob.scheduleでmain()を指定すれば、起動してスクショ撮って閉じるが定期的に実行されます。
Puppeteer部分
//ブラウザ操作メイン関数
async function main() {
const browser = await puppeteer.launch({
headless: true, //今回はHeadlessモードで起動させてバックグラウンドで処理
executablePath: chromepath,
ignoreDefaultArgs: ["--guest",'--disable-extensions','--start-fullscreen','--incognito',],
slowMo:100,
});
//pageを定義
const page = await browser.newPage()
const navigationPromise = page.waitForNavigation();
//初期ページを開く
await page.goto(url)
await page.setViewport({ width: 1200, height: 900 })
await navigationPromise
//Excelファイルを読み込みフラグの無いデータを連続登録
var jsondata;
var dlength;
//ワークブック読み込み
await workbook.init()
.then(wb => {
//ワークシートを読み込み
jsondata = workbook.getData("登録リスト");
dlength = jsondata.length;
return;
})
//ループでxlsxのURLを回していく
for(var i = 0;i<dlength;i++){
//URLを取得する
var mapurl = jsondata[i]["URL"];
console.log(mapurl);
//該当のURLへ移動する
await page.goto(mapurl)
await navigationPromise
//ファイル名を生成する
var today = new Date();
var filename = snapdir + jsondata[i]["ID"] + "_" + today.toFormat("YYYYMMDDHH24MISS") + ".png";
console.log(filename);
//スナップショットを取る
await page.screenshot({path: filename, fullPage:true})
}
//ブラウザを閉じる
await browser.close()
}
- 今回は10分置き実行なので、その度にChromeが表示されると鬱陶しいので、headlessオプションはtrueとしてヘッドレスモードで実行させています。
- xlsxデータを回して、URLを取り出し移動。日付にてファイル名を設定しスクショを撮って保存を繰り返します。
- 最後にブラウザを閉じる。閉じてもプログラムが終了するわけではないので、手動でCtrl+x実行か?プロンプトを手動で閉じれば止まります。
- page.screenshotにて簡単にスクショは取得できる。filenameはフルパスを指定します。
単一実行ファイルを作成する
Node.js 18よりSingle executable applicationsという機能が装備され、標準で単独実行ファイルが作成できるようになりました。結果pkgはプロジェクト終了となっています。よって、以下のエントリーの単一実行ファイルを作成するを参考に、Node18以降はexeファイルを作成することが可能です。
