Query関数を使ってデータを集計しよう - 其の壱
※今回の関数は非常に多機能なので2回に分けて紹介しています。
今回使用するサンプルスプレッドシート
より高度な使い方のその2については以下のエントリーになります。
Query関数の使い方
概要
この関数は他の2つ(Filter関数、ImportRange関数)と比較すると、非常に使いにくい関数です。また、関数の組み方スタイルが独特なのでとっつき難い人が多いでしょう。しかし、SQLの使えないスプレッドシートに於いて、この関数は非常にありがたい関数です。数式が非常にSQLライクな感じなので、VBAなどでSQL文を書いてる人は割りと習得しやすいのではないでしょうか?特徴として、
- 馬鹿でかいデータの塊に対して実行しても非常に高速に値を返してくれる。
- 通常の関数とは異なり、かなり関数内でのパラメータの指定方法が独特である。
- SQLチックなパラメータ指定であるため、非常にとっつきにくい。
- キーとなるパラメータの値を特定のセルから取りたい場合、日付・数値・テキストで指定方法に違いがある。
- SQLチックな文章の中で集計やカウントなどの指定も出来ますが、妙な文字列が1行目に出るのが非常に気になる(9.を参照)
- Query関数で帰ってきた値を通常のSUM関数などに食わせて、集計などが出来る。SUMIFやDSUMなどは不要になる。
- パラメータの指定をレンジではなく、セル単位で指定が可能なので、DSUM関数のようなパラメータが特定レンジで指定しないといけないといったことがないため、非常に融通がきく。
- ピボットタイプ(クロス集計)の集計が可能である。
- データのタイトル部分を関数内で構築が可能である。
注意点
この関数を使う上での注意点が結構あります。以下にそれをまとめてみました。
- Query関数内ではカラム行は使用しないので、範囲指定でもそれらの行は含めない(そのため、A2から指定している)。
- A列、B列などで指定するが、select文の中でsum(C)といったような書き方も可能ではある。しかし、1行目にsumという文字列が出力されたりするので、通常は1.のようにsum関数に食わせるのが通常。
- Where以外にもGroup Byなどが使用できる。
- 条件式の指定に特定のセルの値を参照させたい場合には、””で括って、中に&&で括ったセル番地を指定する。
- 但し、数値ではない場合(文字列)には、”で括った中に4.の書き方をしなければならない(ここ重要)。日付の場合も同じ。
- 更に日付を指定する場合には、5.の前にdateを指定するのが決まりになっている。
- selectで始まる条件式は””で括って置かなければならない。
- andやorが使用できるが、できればそれぞれの条件単位ごとに()で括っておくと、わかりやすくなる。
- 範囲指定した中の日付を元に何かを抽出したい場合は要注意。Queryの条件式側は「2014-10-06」といったパターンで指定されていないと受け付けてくれない。もちろん、セルの中の値に表示としてこのような形にしてもダメ。書式なしテキストにして格納しておくべし。「2014/10/06」といった指定もダメ。
- さらに、抽出される側の日付データにも注意が必要である。こちらは「2014/10/06」といったデータであっても何ら問題がないが、その代わり、表示がそうでも、時刻データが入っているとダメ。
- 故にどこぞからコピーしてきてsetValuesなんかで貼り付けた後のデータを見ると、表示形式で2014/10/06となっていても、セルの中のデータは「2014/10/06 7:00:00」なんて形で、日付データが勝手に混じっていることがある。setValuesでセットした時にこれが起きる。ここで自分は大嵌まりしてました。データから時刻部分を削って戻してやらないといけない。
- 正直言って、何個もこの関数を使うと、数百レコードで既に重たい。ましてや、多数のセルに同様の計算式を入れると更に重い。sum関数に食わせてセルに反映を多様するには実用的ではない。
- 入れ子でQuery関数内でユーザ定義関数は使えません。逆にユーザ定義関数に食わせたり、予めユーザ定義でデータを準備しておいたものをQuery関数に食わせるのも可です。
最もシンプルな使い方
簡単な使い方からまず。*(ワイルドカード)も使用可能なので、指定範囲の列を全て出す場合には、活用しましょう。条件式としてF列の数値が100より上のレコードを抽出するといった事例の場合には、以下のような数式となります。
=query('シート名'!A2:F,"select * where F>100")
複数条件で抽出
また、特定のセルの値を抽出条件として取り、さらに日付を抽出条件として取るようなケースでは、
=query(A2:H20,"select E where (C = '"&$D24&"') and (date '"&$B24&"'<=B)")
こんな書き方になります。D24の値が文字列の抽出で、ポイントの4,5がコレに該当します。また、日付の場合dateを頭に付いてるが、これがポイントの6に該当しています。この計算結果を更にSUM関数に食わせて合計を出すといった事も可能です。VBA内で変数を抽出条件として使う感覚なので、プログラミング的な数式の作り方だと言えます。
もともとQueryなので、ANDやORで簡単に条件式を構築出来るので、複数条件での抽出はFilter関数よりもお手の物です。
指定範囲内で抽出
日付などに於いて、ここからここまでの期間で抽出といった場合には、dateを頭につけてANDでそれぞれ以上・以下で指定を作って上げると抽出が可能です。もちろん特定のセルを参照させると利便性が向上するでしょう。Aが日付のデータの入ってる列です。
=query('売上一覧'!A2:F,"select * where (date '"&$H2&"'<=A) and (date '"&$H3&"'>=A)")
比較演算子の使い方や、また、9.の注意点にあるように、指定する条件側の日付形式はyyyy/mm/ddではエラーになるので、yyyy-mm-dd形式にしてあげる必要があります。普通に日付を入力するとスラッシュになってしまうので、セルの表示形式に於いて、「書式なしテキスト」にしてあげるとスムーズです。
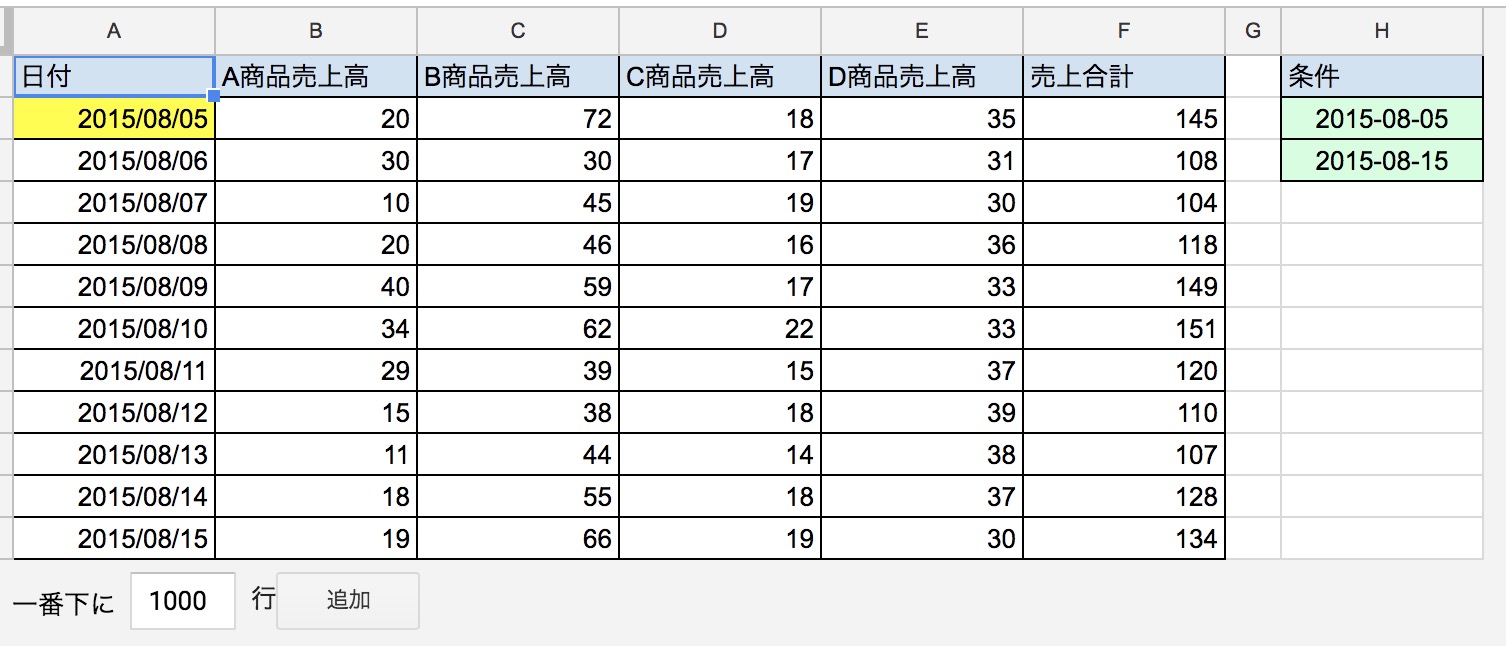
図:日付の指定方法だけ注意が必要
第三の引数
自分はあまり使うことがないのですが、Query関数は第三の引数があります。範囲、クエリ文、そして3つ目は見出しの扱いです。この見出しの引数は、見出しの行目指定を表していて、範囲指定した中で見出しに使うのは何行目なのか?を指定するものです。2行目を見出しに使うなら、2を指定し、省略した場合や-1を指定した時はオートで判定となります。
もちろんですが、見出し行を含まずに範囲指定した場合には、引数を省略すると、見出し行も現れません。ただし、基本的な使用の場合(1行目が見出しになっていて、範囲指定に含めている場合)は、引数はつけなくてOKです。
また、前項のように該当する見出しのない自分で列を生成した場合には、LABEL句にて見出しを加える事が可能。たとえば、F*100という計算列を加えると適当な列名がついてしまいますが、LABEL F*100 '売上金額'とすると、売上金額というラベルを付けてくれます。
集計やカウント
SQL文と同じく、Query関数内でも集計やカウントをする事が可能です。使用できる集計関数は、avg(), sum(), count(), max(), min()の5つとなっています。sumとcountが利用頻度が最も高いでしょうね。それぞれの列の合計を取って集計する例を作ってみました。
=query('売上一覧'!A2:F,"select sum(B),sum(C),sum(D),sum(E) where F>100 LABEL sum(B) 'A商品売上高計', sum(C) 'B商品売上高計', sum(D) 'C商品売上高計', sum(E) 'D商品売上高計'")
それぞれの売上金額のある列の全合計(ただし売上合計が100より上のもの)を集計しています。集計等を行う場合、ポイントの5.にあるようにタイトル行にsumと出てしまうので、LABELもつけて上げています。countであれば件数が出てくるわけです。集計結果を別途Sum関数に食わせたりする必要がありません。
列の入替えと計算
Access使いはおなじみの列の入替えが簡単にできます。Query関数でのselect文は別に順番に列を並べる必要はなく、また全部の列を表示してあげる必要もない。必要な列を必要な順番で好きに並べられるのも特徴です。また、既存の列にはない計算列を作って追加する事も可能。まさにこれぞクエリーという使い方ですね。
ちなみに、列の指定をせずに、「*」を指定すると、全列表示になります。(select *といった具合)。また計算式では別の関数を使っての計算も可能です。
//列を入替えて、個数列に100を掛けた数値を売上列とした事例 =query(A1:F100,"select C,B,E,F*100 LABEL F*100 '売上金額'")
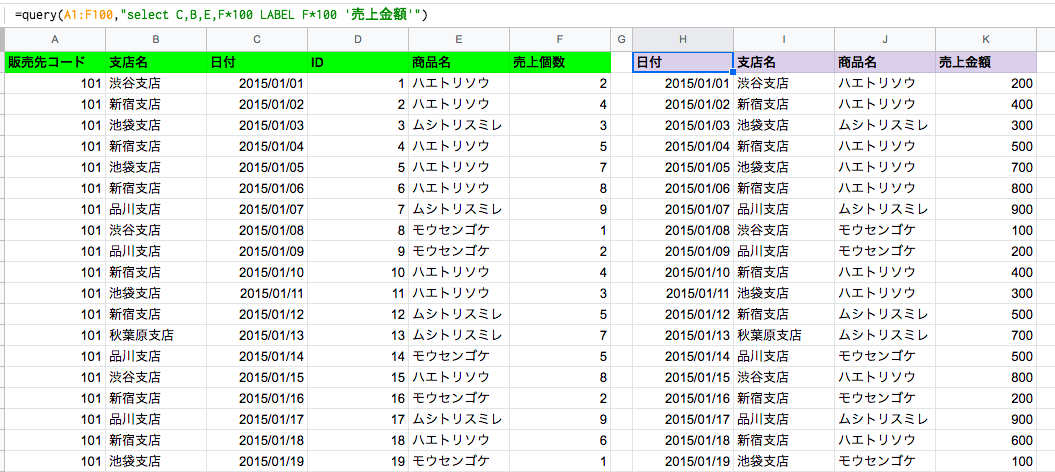
図:列入替えと売上金額列を追加してみた
抽出結果を並べ替えする
通常の並び替え
オートフィルタなどでもよく使う並べ替え。ただ、オリジナルのデータを並べ替えしたら、連番を付けなかったが為に、オリジナルの順番に直せなくなったなんてこともしばしば。だからこそ、オリジナルデータは弄らずにQuery関数を使って操作し、並べ替えをするのがこの関数の使い所の1つです。これを実現するのが、ORDER BY句で列の指定の後に、descで降順、ascで昇順となります。
また、WHERE条件で抽出後のものも並べ替えが可能なので、オートフィルタで手動でやるより、数式でコントロールするほうが色々と便利です。
//モウセンゴケで抽出して、F列を降順で並び替え =query(A1:F100,"select * where E = 'モウセンゴケ' order by F desc")
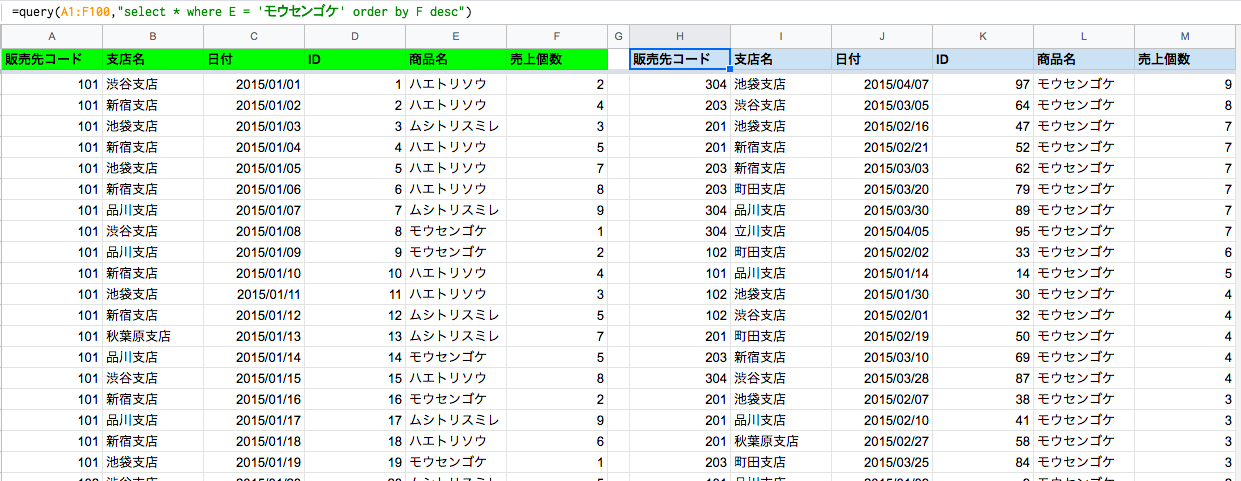
図:抽出結果を個数で降順並び替えしてみた
関数の計算結果を並び替え
関数で処理したものをQuery関数に食わせたという計算結果に対してQuery関数を使ったケースでは、order byにて列で指定が出来ません。その場合3列目ならば、col3となるため、select * order by Col3 Descとすると3列目で降順という形になります。select * order by C descではないので注意です。
例えば以下のように{ }で括られた複雑な関数の計算結果は配列で帰って来ます。こういった場合には Colで列を指定することでソートが可能になります。
//Memberシートとemployeeシートをメアドで結合
=query({member!A2:B,iferror(arrayformula(vlookup(member!B2:B,employee!A2:D,{2,3,4},false)))},"select * order by Col3 Desc")
同じくQuery関数にImportrange関数を食わせての並び替えや列の選択もColで指定する必要があります。
//importrangeの結果を食わせる
=query(importrange("https://docs.google.com/spreadsheets/d/xxx","売上一覧!A:F"),"select Col1, Col2")
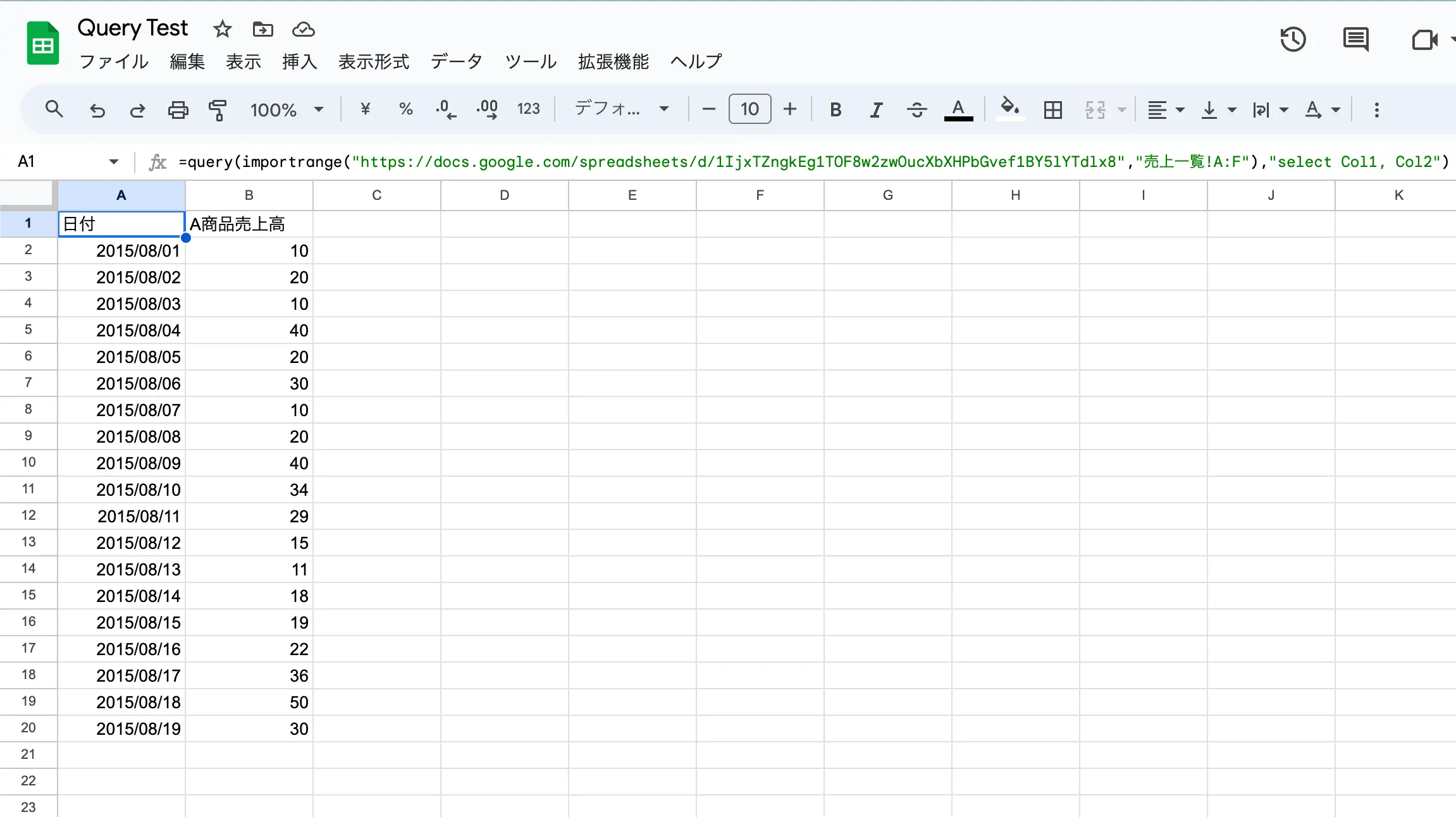
図:ソートする場合は仕様に注意が必要
文字列と数字の混在する列で発生するバグ
通常、列に於いてあまり文字列と数値が混在するケースは多くありませんが、決して無いわけではありません。このような列を持っているデータ群に対して、Query関数を利用したときに、データが存在しないもしくは空白で返ってくる謎現象があります。
この現象は、列内で文字列の値が数値の列よりも、文字列の列の存在数が少ない場合、自動で書式設定が働き、「空白」と見做されてしまい起きてる現象です。StackOverFlowでもこの問題と解決策が提示されています。ただしその解決策は数式が難解なものになってしまうので、以下のような手段を使って解決をすると良いでしょう。
- あらかじめ、その列はすべて書式設定に於いて「書式なしテキスト」に変更を行っておく。
- 書式設定が難しい場合には、指定の列をまずは別の関数で「TO_TEXT関数」にて、文字列型に変換をしておき、その結果をQuery関数に食わせる方法
前者は簡単な方法ですが、そうもいかないというケースもあるので、その場合は2番目の手法を利用することになります。また、2番目の手法の場合、To_TEXT関数で変換をかけたものに対して、Query関数を使うので、1列目はCol1, Col2と列名が変わるので注意!!
//確かにデータはあるのに失敗する事例 =QUERY(A2:C7,"select A, B, C where C='A200'")
数字・文字混在の列に対して、C列にて文字列でのデータ抽出を掛けるとN/Aになる。文字列のデータを増やすときちんと、今度は関数が正しく動く・・・文字列データは数値と判断されて、計算上は空白の扱いになるようだ。
//TO_TEXTで変換してからQuery関数で処理 =QUERY(ARRAYFORMULA(TO_TEXT(A2:C7)),"select Col1, Col2, Col3 where Col3='A200'")
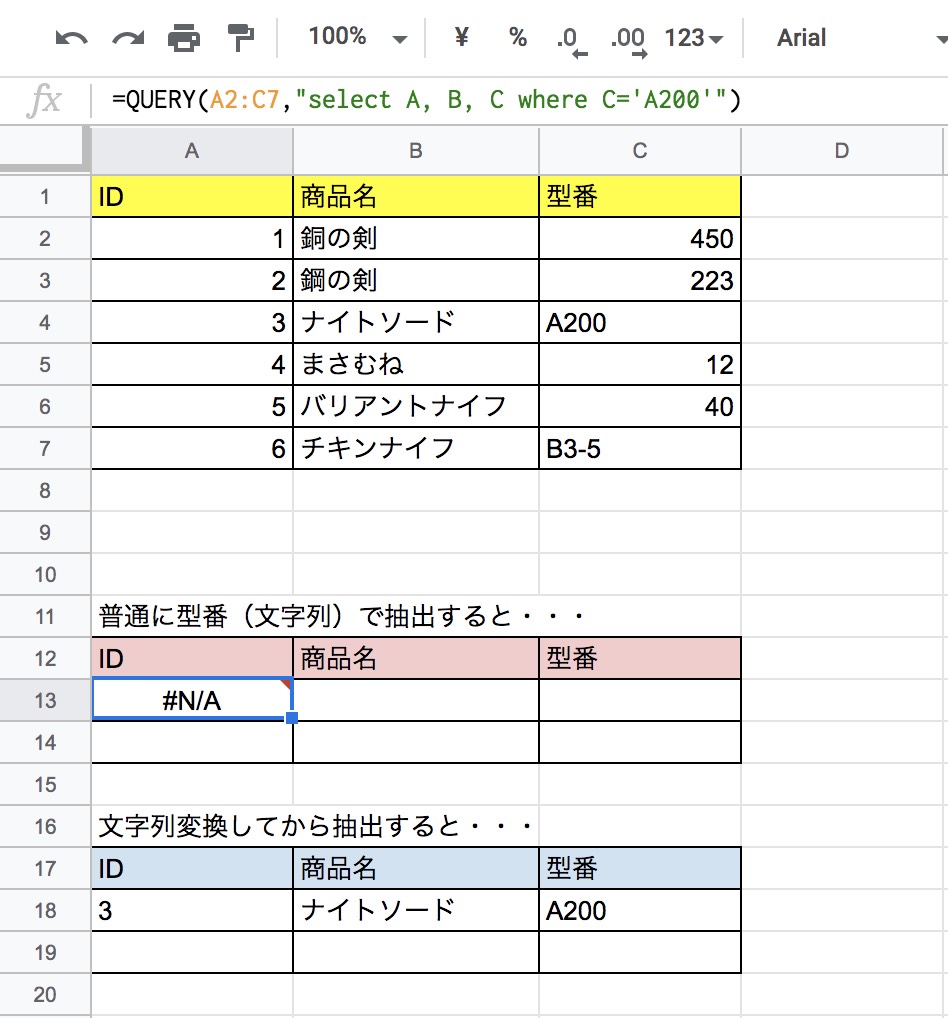
図:文字と数値はなるべく混在しないようにしなければ
この方法であっても、日付型の値がさらに入ってきた場合、日付にてWhere条件中抽出ができなくなったりするので、もともとの設計段階にて、その列には指定の型以外の値は入らないように注意すべきだと思います。
Query関数の結果を別の関数に食わせる
Query関数の場合、関数単体で殆どの事が実現可能なので、使うシーンは少ないですが、他の関数同様返ってきた配列データを更に別の関数に食わせて処理を行わせる事が可能です。Sumなど場合はQuery関数自体に集計機能が備わってるので、別途食わせるといったことをしませんが、その他の関数を使う場合には有効です。
また、配列で結果が返ってきたものを別の関数に食わせている点もExcelにはない感覚ですね。今回は平均値ではなく統計などで利用される中央値(メジアン)の関数で組み立ててみました。
=MEDIAN(query('売上一覧'!A:E,"select E"))
E列(D商品売上高)の数値の配列に対して、Median関数で中央値を取っています。統計ではよく利用される関数ですが、極端に高い数値があると平均値が上がってしまい、現実的ではない数字になります。そこでより集まってる塊に対してだけ平均を取るような関数で、平均値よりも現実的な数値が求められます。

図:平均値と比べてみた。
列で計算させる
まず普通に計算させる
Query関数でたとえばC列、D列が数値で、5番目の列にC列-D列の減算した結果を表示したいという場合があります。この場合、以下のように5列目を作り、またLabelを定義すると良いでしょう。
//C列からD列を引いて、差引残高を計算させる =query(A1:D5,"select A,B,C,D,C-D Label C-D '差引残高'")
単純にselectの中で、5列目でC-Dとして入力し、C-DのLabelを付けるだけ。これで差引計算が出来ます。但し注意事項として
- C列もD列も数値が必ず入っていること(NullはNG。差引計算されません)
- Labelとつけないと5列目のタイトル行はdiffrenceという文字が表示されてしまい格好悪い
という点があります。注意しましょう。
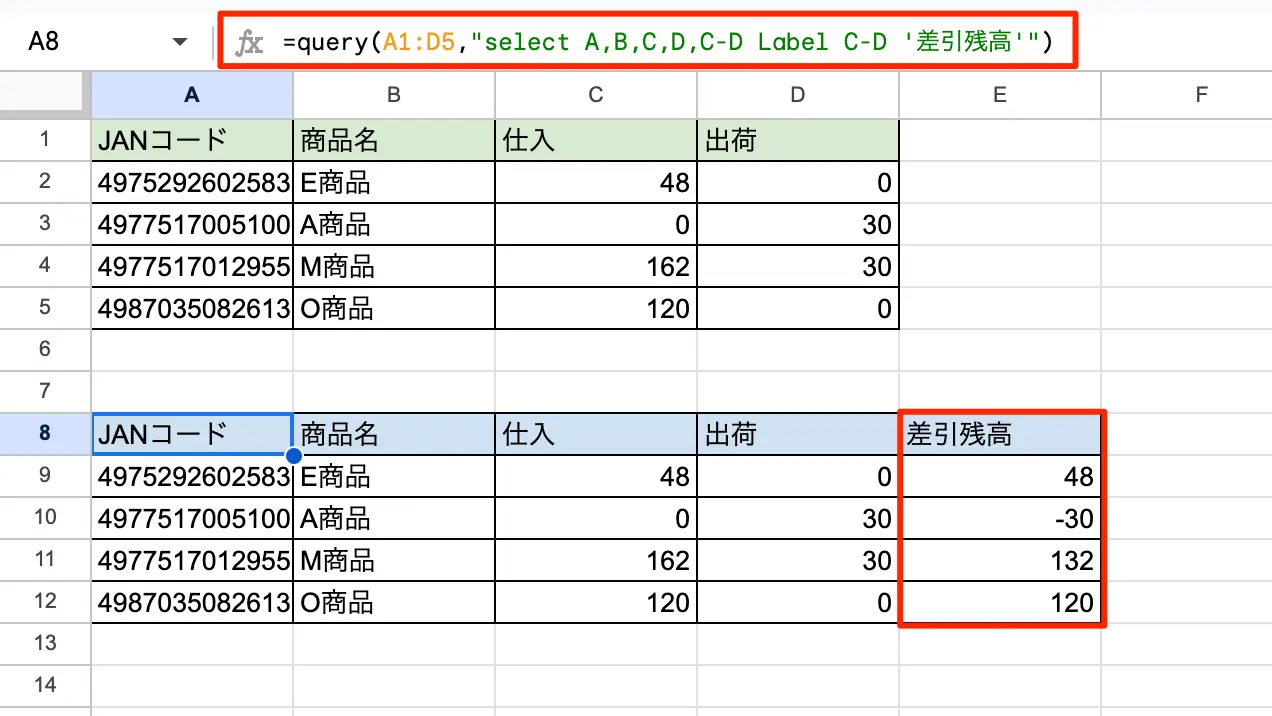
図:差引計算して残高表示できた
0表示させてから計算させる
さて、問題はQuery関数にて、クロス集計した結果のC列やD列で合計を取った場合、0ではなくNullのケースがあります。クロス集計のQuery式でこのまま計算させても、前述の通り計算されません。よって、以下のように一度GASで作成したユーザ定義関数でNullを0に置き換えて、その結果をさらにQuery関数で食わせてから前述のように計算させるとうまくいきます。
※5番目の列だけarrayformula(C2:C - D2:D)みたいな継ぎ足しが必要ありません。
//クロス集計結果に計算列を追加してあげる
=query(nullcheck(query('テーブル結合'!A2:G9,"select A,E,sum(C) Group By A,E Pivot D LABEL A 'JANコード', E '商品名'")),"select Col1, Col2, Col3, Col4, Col3-Col4 label Col3-Col4 '差引残高'")
この時、ユーザ定義関数としてスプシに用意した関数は以下のようなGASになります。
function nullcheck(array) {
let check = array.map((row, i) => (i === 0)? row: row.map(column => !column? 0: column));
return check
}
タイトル行の1行目はスルーして、それ以下の数値をmapで1つずつチェック。nullだったら0を返すようにしています。この結果を前述のようにQuery関数で食わせて、Labelをつけてあげれば完成。
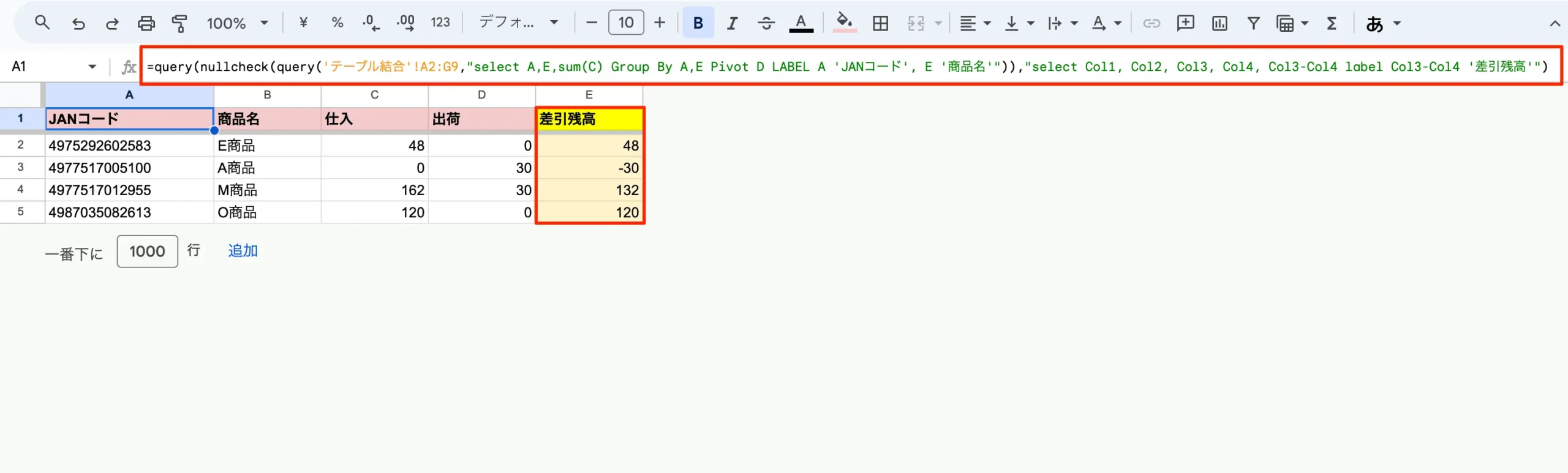
図:nullcheck関数に食わせてから再度Query
クロス集計を行う
Googleスプレッドシートには、Excel同様にピボットテーブル機能が用意されているので、問題なくクロス集計が可能になっています。しかし、データの二次利用となると、あの形式では正直使いにくい。Access等では、クロス集計クエリをまたテーブルとして扱えるので、更なる計算などが可能になっているけれど、これをGoogle Spreadsheet上でやるためには、ピボットテーブル機能を使っての作成ではちょっと困難です。
ということで、Query関数を旨いこと活用することで、Accessのように二次利用に最適な形で、日々の入力データをクロス集計化し、シートに展開する事が出来ます。複雑ではあるので万人にオススメという訳ではありませんが、標準の関数のみで行えるので、スピードが早い点、そして何よりもスクリプトを組まずに展開が出来、スクリプトから二次利用が出来るというのは非常に都合の良いものです。グラフ作成でも、柔軟に自動的にグラフ展開が期待できるので、オススメですよ。
事前準備
今回想定しているのは、以下のようなデータカラムの日々の入力データから、クロス集計化して別のシートに展開するケースです。今回使用するスプレッドシートも全く同じデータ構造なので、そちらを見てもらったほうが、理解は早いかもしれませんね。下記のデータテーブルより、【商品名】を基準にクロス集計を行って行きます。
| 販売先コード | 支店名 | 日付 | ID | 商品名 | 売上個数 |
|---|---|---|---|---|---|
| 101 | 渋谷支店 | 2015/5/1 | 1 | ハエトリソウ | 300 |
| 102 | 梶が谷支店 | 2015/6/2 | 2 | サラセニア | 150 |
これをクロス集計して展開する時には以下のような構造で行列を設定し、展開を行います。商品名毎に売上個数を集計する訳です。
| 販売先コード | 支店名 | ハエトリソウ | サラセニア |
| 101 | 渋谷支店 | 30 | 40 |
| 101 | 渋谷支店 | 25 | 12 |
さて、これでクロス集計化した時のイメージは出来たので、実際に実データを基に、Query関数を使用してピボット化を行います。普通はココで、ピボットテーブルを使う所ですが、今回は使用しません。あくまでもQuery関数で二次利用の為にデータテーブルを作るのが目的ですから。
クロス集計させてみる
さて実際に使用します。Query関数自体の使用方法についてはいずれ他の独自の関数とまとめて紹介しようと思います。
今回の数式は以下のようになります。SQLチックですが、独自のPivotという項目が今回の肝になります。Group Byでどこまでグルーピングするかは、ユーザがどこまで列を残すかによります。今回は、日付の部分を外し、グループ化の対象にはしませんでした。
=QUERY(database!A2:F, "SELECT A,B,sum(F) Group By A,B Pivot E LABEL A '販売先コード', B '支店名'")
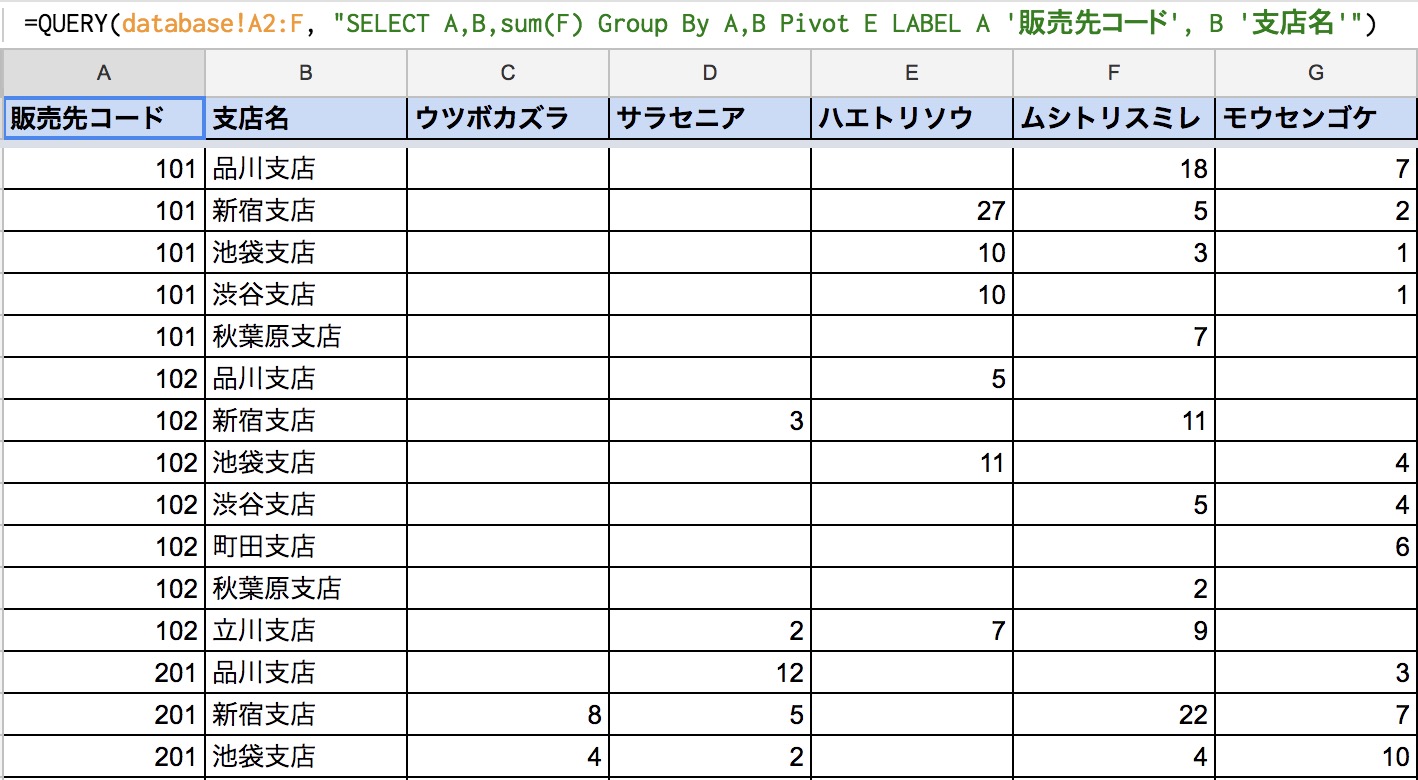
図:スクリプトからの二次利用がとてもしやすい
カラムのソートはできないので・・・
Query関数は、構文の中でPivotを使った場合、ORDER BYが利用できません。その為、Pivotを使ったクロス集計を使った時に、例えば「日付」をカラムに取った場合、順番がオカシナ事になります(1日の次が10日、2日の次が20日といったような感じで列が並んでしまう)。
出勤簿やら日付を横にとって見ていく時にこれでは具合が悪いです。但し、数字のみであるならば、きちんと並んだりするので、「日」といった文字が入ると、順番がおかしくなるようです。この場合、数字の部分に於いて1桁の数字には0を頭に加えて「01日」としてあげて、2桁の数字は普通に「10日」としてあげることで、きちんと並びます。
下記の図はそれぞれ同じ構文ですが、並びが違うのがわかると思います。Query関数できちんとPivotで並べたい時は、関数ではなくデータ側に細工が必要なので注意が必要です。
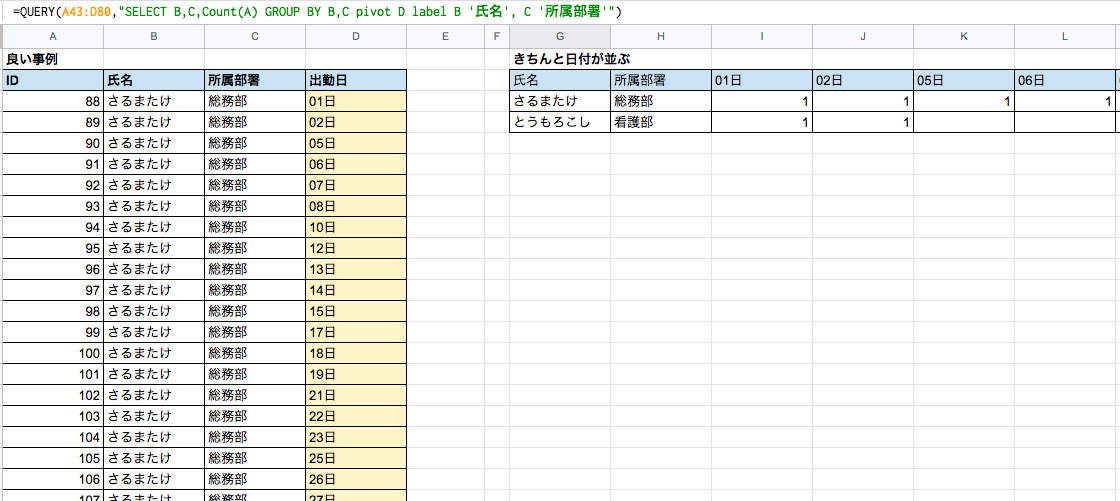
図:良い事例
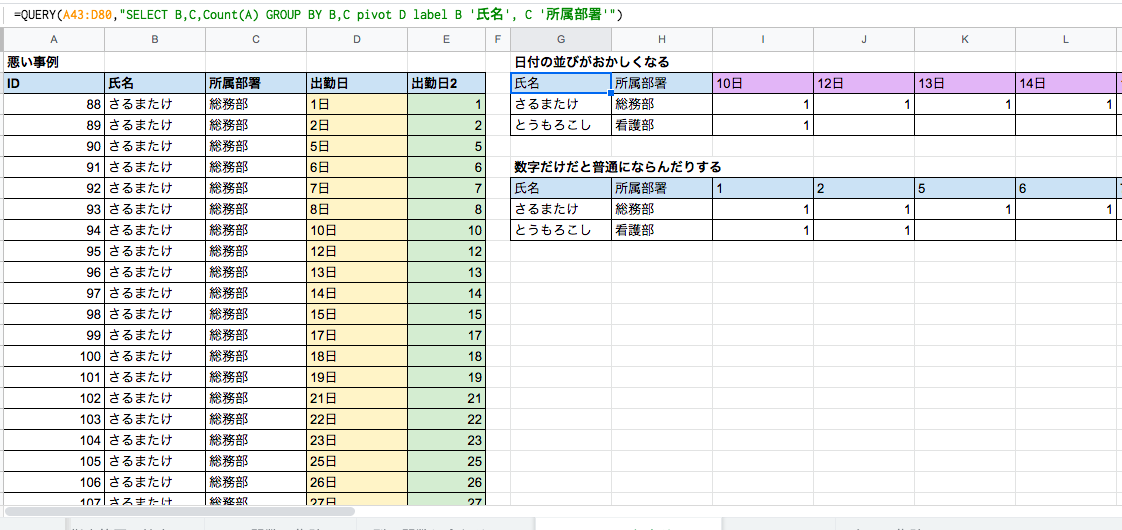
図:悪い事例
ポイント
- 使用する列は、D列以外の全てですが、表示する行は、A~Cそして、集計としてF列の値を指定しています。
- Group Byにてグループ化を指定します。A~Cまでをグループ化の対象として指定しています。この辺りは、Accessではお馴染みですね。
- Pivotにて列指定としてE列を指定しています。1.で集計対象にした内容が、これで商品名毎に集計表示されるわけです。
- LABEL以下は要らないと言えば要らないのですが、任意の列ラベルを付ける事ができます。標準だとラベルがない為、A~Cまでラベル指定してます。
- 但し、E列のPivotで指定した箇所は、自動的に列名として商品名が付与されるようになっています。
- 値は配列で返されるので、Filter関数同様自動的にスプレッドシートが拡張され、A1に式を入れた場合、そこを基準に値が自動的に展開されますので、誤って消しても復元されます。
- あとは作成されたデータテーブルの値を他のレポート用シートからvlookupで取ったり、カウントしたり、グラフを作ればOKです。
関連リンク
- GAS:GASでSpreadSheetの組み込み関数(Query関数)を使う
- google spreadsheetのquery関数
- Query関数について – Google Developer
- Query a Google Spreadsheet like a Database with Google Visualization API Query Language
- Google Spreadsheets を簡易 SQL DB に!「Google Visualization API」
- Microsoft Power Query for Excel の概要
- 平均値と中央値の違い
- MEDIAN|データ範囲における数値の中央値
- スプレッドシートのQUERY関数にて、SELECTする際に置換(REGEXREPLACE)したい。
