Power Automate DesktopでCloud Vision APIを使ったOCRを実現
Power Automate Desktopの記事がウェブ上を見てると、ぼちぼち出てきていますね。VBAなどの場合もそうなのですが、こういったいろいろな人の知見や手法などが広がる事がなかったのがこれまでのRPAの現実。広がってきて民主化が進んでいるのを感じます。
さて、前回の記事では、基本的な機能でのみPower Automate Desktopを使った手法を紹介しましたが今回は、OCRの項目でスルーした「Google Cloud Vision APIを使ってOCR」をPower Automate Desktopで実現してみたいと思います。
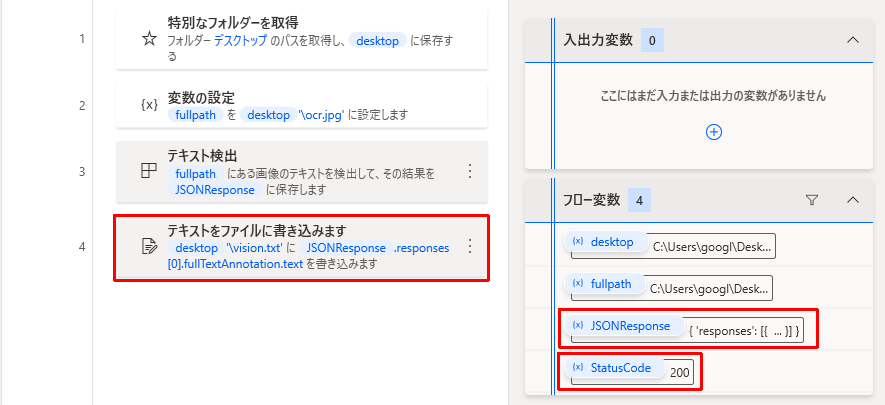
図:4工程で実現します
目次
今回使用するアプリとサービス
事前準備
Cloud Vision APIの概要
Googleが提供している機械学習を行う画像認識APIがCloud Vision APIです。単に画像から文字起こしだけでなく、画像を認識して処理するような事まで幅広く担当しているAPIですが、Speech API同様課金対象のAPIです。ですが、月間の無料枠があるので、その枠内であれば、勝手に課金されるといった事はありません。料金はこちらから。用途別で変わってきます。今回は、OCRについてだけ取り上げてみたいと思います。
また、テキスト検出についてのサンプルなどはこちらのページに用意されています。
| 項目名 | 内容 |
|---|---|
| 画像ファイル | JPG形式, PNG形式(但し、640×480以上のサイズであること) |
| ファイルサイズ | 20MBまで(返り値のJSONオブジェクトは10MBまで)。また1リクエストあたり16枚まで。 |
| リクエスト | Base64形式で渡すか?Cloud Storageへ配置する必要がある(プログラムの場合) |
| 無償上限単位 | 1000ユニット/月まで。それ以上は課金対象(1画像1ユニット) |
| 有償課金 | 1.5ドル/月(500万ユニットまで) |
| 制限 | 1分あたり1,800枚まで。1ヶ月あたり20,000,000 枚まで |
APIキーの作成
きちんと請求アカウントを作り、APIキーを作り、Vision APIの使用の準備をしていないと、403エラーが返ってきてしまいます。また、API方式なのでOAuth2.0認証などはありません。APIキーは漏れたりしないように厳重に管理しましょう。

画像ファイルについて
画像ファイルですが、Power Automate Desktopの場合、直接フルパスでどこぞに格納してるjpgファイルなどを指定して送りつける事が可能になっています。Google Apps Scriptなどの場合にはBase64エンコードなどが必要なのですが、この辺りの処理はVision APIを使うコネクタが後ろで色々よしなにやってくれてるのだと思います。
今回使用するファイルは青空文庫の太宰治の「富嶽百景」を画像として読み込ませました。

図:富嶽百景の冒頭を切り取って画像化してみた
フローを作成する
ここまでで、Google Cloud Vision APIの使用準備が整いました。ここからフローを作るのですが、フロー自体は非常にシンプルで簡単に作る事が可能です。一点だけ、OCRした結果はJSONで返ってくるので、JSONからその部分を取り出す点が今回のポイントになります。
作成手順
以下の手順で作成します。
- 特別なフォルダアクションにて、デスクトップのパスを%desktop%として取得する
- 変数の設定アクションにて、1.のデスクトップパスに加えて、¥ocr.jpgをつなげて、%fullpath%として保存
- コグニティブ→Google→ビジョン→テキスト検出のアクションを追加する
- 取得しておいたAPIキーを入力。画像ファイルは2.の変数を指定する
- 次にテキストをファイルに書き込むアクションを追加します
- ファイルパスは、1.と¥vision.txtをつなげて指定します。
- ここがポイントですが、OCR結果は、%JSONResponse%に返ってきます。ステータスコードは%StatusCode%に成功すれば、200が返ってきます。
- 書き込むテキストは、7.の内容からJSONを取り出す形で指定する。%JSONResponse.responses[0].fullTextAnnotation.text%という形で書き込むと、OCR結果の文字列が取り出せます。
- 新しい行を追加するはチェックを外します。
これで完成です。複数のファイルを回したい場合には、for eachや名付けるファイル名などをなんとかすれば、このRPAのみで一斉に画像認識でテキスト化が自動化可能です。
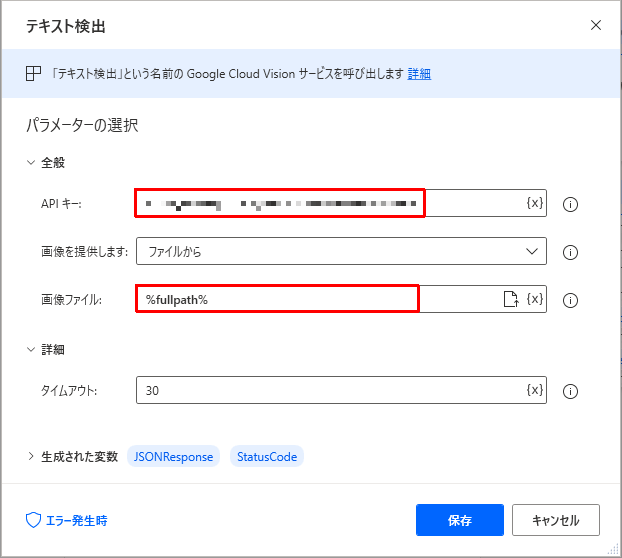
図:テキスト検出以外にもあります
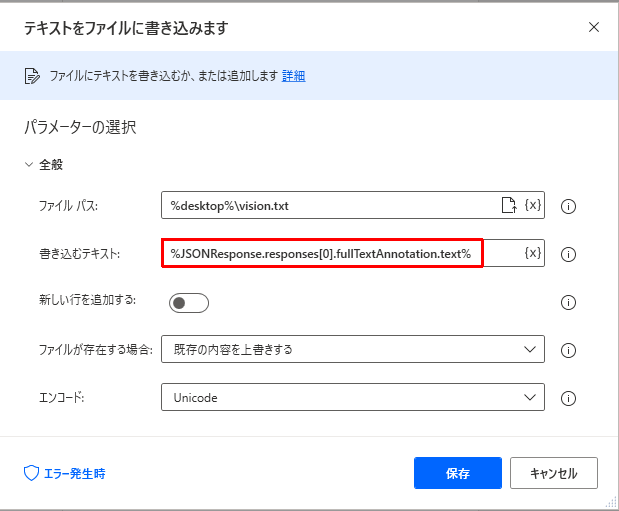
図:テキスト書込みがポイント
フローのコード
Folder.GetSpecialFolder SpecialFolder: Folder.SpecialFolder.DesktopDirectory SpecialFolderPath=> desktop SET fullpath TO $'''%desktop%\\ocr.jpg''' Cognitive.Google.Vision.TextDetectionFromFile APIKey: $'''ここにAPIキーを記述する''' ImageFile: fullpath Timeout: 30 Response=> JSONResponse StatusCode=> StatusCode File.WriteText File: $'''%desktop%\\vision.txt''' TextToWrite: JSONResponse.responses[0].fullTextAnnotation.text AppendNewLine: False IfFileExists: File.IfFileExists.Overwrite Encoding: File.FileEncoding.Unicode
4工程のみで実現してるので、シンプルです。
OCR結果
Cloud Vision APIでOCRしてみた結果は以下の通り。
富獄百景 太宰治 ひろしげ ぶんてう 富士の頂角、広重の富士は八十五度、文晃の富士も八十四度くらゐ、けれども、陸軍の実測図によつて東西及南北に断面図を作つてみると、東西縦断は頂 角、百二十四度となり、南北は百十七度である。広重、文晃に限らず、たいていの絵の富士は、鋭説角である。いただきが、細く、高く、華著である。北斎にい たつては、その頂角、ほとんど三十度くらゐ、エッフェル鉄塔のやうな富士をさへ描いてゐる。けれども、実際の富士は、鈍角も鈍角、のろくさと拡がり、東 西、百二十四度、南北は百十七度、決して、秀抜の、すらと高い山ではない。たとへば私が、印度かどこかの国から、突然、鷲にさらはれ、すとんと日本の沼津 あたりの海岸に落されて、ふと、この山を見つけても、そんなに驚嘆しないだらう。ニツポンのフジヤマを、あらかじめ憧れてゐるからこそ、ワンダフルなの であつて、さうでなくて、そのやうな俗な宣伝を、一さい知らず、素朴な、純粋の、うつろな心に、果して、どれだけ訴へ得るか、そのことになると、多少、心 細い山である。低い。裾のひろがつてゐる割に、低い。あれくらるの裾を持つてゐる山ならば、少くとも、もうー·五倍、高くなければいけない。 十国峠から見た富士だけは、高かつた。あれは、よかつた。はじめ、雲のために、いただきが見えず、私は、その裾の勾配から判断して、たぶん、あそこあた りが、いただきであらうと、雲の一点にしるしをつけて、そのうちに、雲が切れて、見ると、ちがつた。私が、あらかじめ印をつけて置いたところより、その 倍も高いところに、青い頂きが、すつと見えた。おどろいた、といふよりも私は、へんにくすぐつたく、げらげら笑つた。やつてゐやがる、と思つた。人は、完 全のたのもしさに接すると、まづ、だらしなくげらげら笑ふものらしい。全身のネヂが、他愛なくゆるんで、之はをかしな言ひかたであるが、帯紐といて笑ふ といつたやうな感じである。諸君が、もし恋人と逢つて、逢つたとたんに、恋人がげらげら笑ひ出したら、慶祝である。必ず、恋人の非礼をとがめてはならぬ。 恋人は、君に逢つて、君の完全のたのもしさを、全身に浴びてゐるのだ。 東京の、アパートの窓から見る富士は、くるしい。冬には、はつきり、よく見える。小さい、真白い三角が、地平線にちよこんと出てゐて、それが富士だ。な んのことはない、クリスマスの飾り菓子である。しかも左のはうに、肩が傾いて心細く、船尾のはうからだんだん沈没しかけてゆく軍艦の姿に似てゐる。三年ま への冬、私は或る人から、意外の事実を打ち明けられ、途方に暮れた。その夜、アパートの一室で、ひとりで、がぶがぶ酒のんだ。一睡もせず、酒のんだ。あか つき、小用に立つて、アパートの便所の金網張られた四角い窓から、富士が見えた。小さく、真白で、左のはうにちよつと傾いて、あの富士を忘れない。窓の下 のアスファルト路を、さかなやの自転車が疾駆し、おう、けさは、やけに富士がはつきり見えるぢやねえか、めつぽふ寒いや、など咳きのこして、私は、暗い 便所の中に立ちつくし、窓の金網撫でながら、じめじめ泣いて、あんな思ひは、二度と繰りかへしたくない。 昭和十三年の初秋、思ひをあらたにする覚悟で、私は、かばんひとつさげて旅に出た。 きやしや インド わし あこが しるし おびひも しつく つぶや むな す
以前Google Apps ScriptでCloud Vision APIを使った時よりも精度が上がっているみたいです。旧仮名遣いであったり、旧漢字の認識も良い感じです。
ルビが入ってしまってるので、それらは独立した行になってしまっていますが、ルビの入っていない通常の文書であればかなり現実的なOCRを低価格で自前で用意できるのはGoodですね。
関連リンク
- Google Apps Script で Cloud Vision API を使ってみる
- GoogleDriveのOCR機能をGASで取得する方法から名刺管理アプリを作った話
- LINEから送った画像を文字起こししてくれるアプリを作るときのメモ①
- Google Cloud Vision APIのOCR(画像認識)を検証する
- Google Apps Scriptで画像の文字列を抜き出す
- Google Cloud Vision API from Google Apps Script?
- How to Use Google Cloud APIs with Apps Script – Sample Application
- Using a service account – Google Cloud Vision API
- Google Vision API で 400エラーがでたので実施した対応を書く
- 【LINE Botで文字起こし】Cloud Vision APIを利用したOCRボットの作成手順を公開
- 【LINE Botで文字起こし】Cloud Vision APIとComputer Vision APIでOCRボットを作成してみた
