Google Apps Scriptでスクレイピングを極める【GAS】
Google Apps Scriptで意外とよく利用されてるのが、ウェブページのスクレイピング。今どきのウェブサービスだとREST APIが装備されてるのが半ば当たり前になってきていますが、そうではないサイトや提供されていないサイトも非常に多いです。
そういったサイトのデータを手動で検索し値をコピー、貼り付けて整形してから処理をするのではスマートではありません。そういったケースを自動化するのがスクレイピングの主な目的です。但し、連続してスクレイピングを行うと相手方ウェブサイトに多大な負荷を掛け、また場合によってはアクセスを禁じられる恐れもあるため、利用する頻度やルールは守りましょう。
目次
今回使用するサービス等
- スクレイピングサンプル - Google Spreadsheet
- Google Cloud Functions
- Puppeteer
- cheerio for Google Apps Script
以前、PuppeteerとCheerioを使ってテーブルデータをスクレイピングしましたが、参考になるかと思います。
事前準備
注意事項
Google Apps Scriptでのスクレイピングですが、Node.js + Puppeteerで作る場合と異なり、GASだけでスクレイピングする場合には色々と注意事項があります。主に
- 6分の実行時間制限がある
- Google Workspaceの場合、UrlfetchAppは100,000 回/1日の制限事項がある
- JavaScript多用の動的サイトのスクレイピングは出来ない(Puppeteerは可能)
- 大規模なデータの取得や画面遷移を伴うデータの取得に向いていない
- フォームなどのパラメータ入力の結果をスクレイピングするのには向いていない
これらに該当しそうなケースについては、Google Apps Scriptではなく、Puppeteerなどでスクレイピング環境を構築するほうが良いでしょう。
ライブラリの追加
以前は、HTML Parserライブラリ(1Mc8BthYthXx6CoIz90-JiSzSafVnT6U3t0z_W3hLTAX5ek4w0G_EIrNw)を使うのが主流でしたが、正直言って使いにくい。ので、最近はNode.jsなどでもおなじみのjQuery的にHTMLを処理できるCheerio.gsを使うのが非常に楽に処理できるので、おすすめです。
以下の手順で追加します。
- スクリプトエディタを開く
- 左サイドバーの「ライブラリ」の+ボタンをクリックする
- スクリプトIDに「1ReeQ6WO8kKNxoaA_O0XEQ589cIrRvEBA9qcWpNqdOP17i47u6N9M5Xh0」を追加する
- 検索をクリック
- 最新バージョンが出てくるので、追加ボタンをクリック。Cheerioで呼び出すことになります。
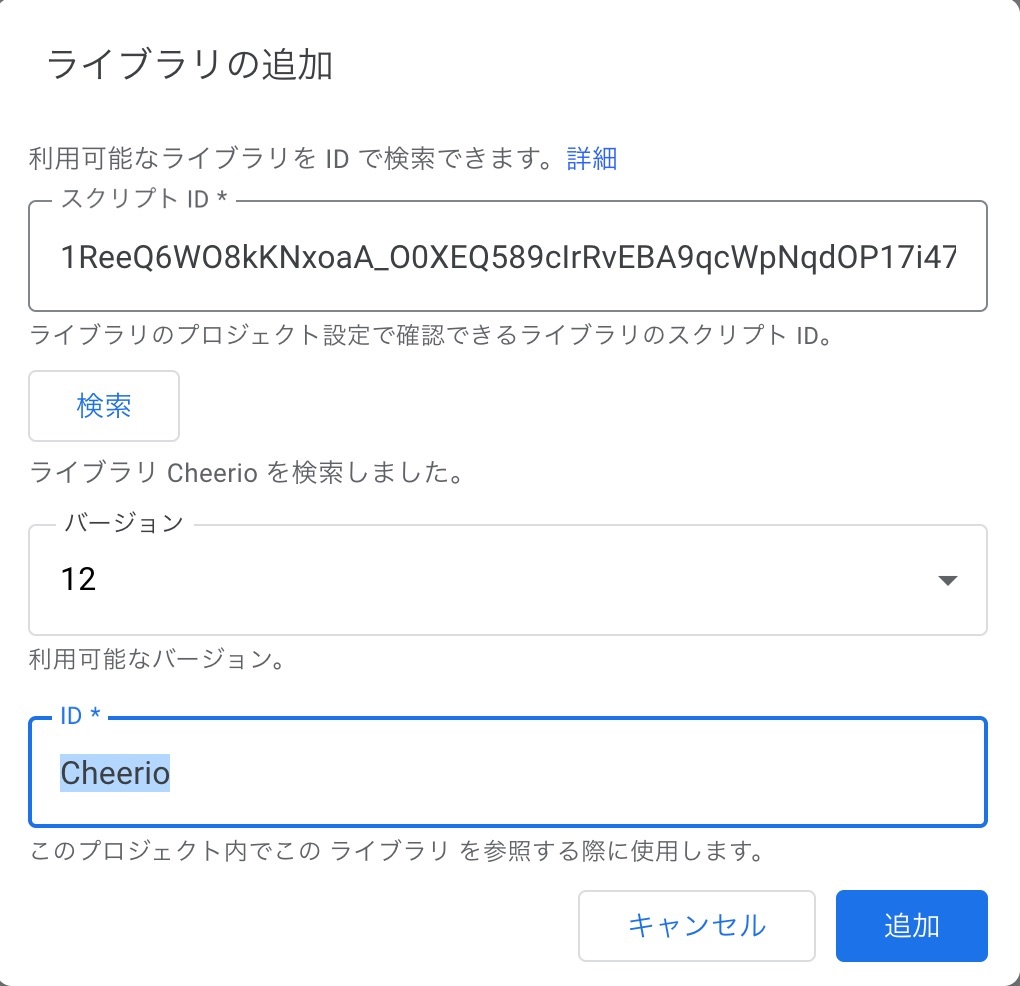
図:jQueryの使い手ならすぐ使いこなせるよ
シンプルなスクレイピング
対象ページのHTMLの構造
Google Apps Scriptでの最もシンプルなスクレイピングです。UrlfetchAppを利用してページの取得になります。シンプルではありますが、Puppeteerを使うわけではないので、注意事項にもあるように、最近の主流である動的なサイトのスクレイピングは出来ません。Ajaxの処理結果でサイトを表示してる場合、処理前の何もないページを拾う事になってしまいます。
今回は医薬品コードサーチにて、ロキソニンを調べデータを取り出してみようと思います。検索をすると医薬品名にマッチした候補が列挙、そのURL先に詳細なGS1/JANコードや、包装形態などの情報が含まれています。
対象ページの構造をChrome Developer Toolで調べてみると、医薬品情報はTableで構築されていて、Class名がtable001となっています。また、各セルのclass名はfs13 talというものが指定されてるのがわかります。

図:HTMLの構造を事前に調べておく
ソースコード
function getDrugInfo() {
//スクレイピングスタートするURL
var url = "https://icode-search.com/index.php?key=%E3%83%AD%E3%82%AD%E3%82%BD%E3%83%8B%E3%83%B3&stype=1";
// UrlFetchAppにて取得(UTF-8を指定)
var html = UrlFetchApp.fetch(url).getContentText('UTF-8');
// 返り値をCheerioに食わせる
var $ = Cheerio.load(html);
//class指定
var $tables = $('.table001 td');
//Tableだけ抜き出す
var drugman = [];
var temparr = [];
var cnt = 1;
$tables.each(function(index, element) {
//tdの値を取り出す
let value = $(element).text();
//一時配列に追加する
temparr.push(value);
//カウンタを追加する
cnt = cnt + 1;
//カウンタが4の時はdrugmanに追加し、変数を初期化
if(cnt == 4){
drugman.push(temparr);
cnt = 1;
temparr = [];
}
});
//drugmanをスプレッドシートに書き出す
var ui = SpreadsheetApp.getUi();
var ss = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("医薬品");
var colcnt = drugman[0].length;
var rowcnt = drugman.length;
ss.getRange(2,1,rowcnt,colcnt).setValues(drugman);
//終了メッセージ
ui.alert("取得完了");
}
- urlfetchappのgetContentTextにてHTMLをスクレイピングしています
- スクレイピングした内容をCheerio.loadに渡し、jQuery的な取り出しを可能にします。
- 今回は指定クラスのtdの中身を取り出すので、$('.table001 td')を指定し、ループで回しています。
- $(element).text()にてtd内のテキストだけを取り出しています。
- 今回のテーブルは3列の仕様なので、3つ値を一時配列に入れてから、書込み用のdrugmanの配列にpushしています
- 1行文取れたら、一時配列を初期化し次の3列を取りに行きます。
- データの書き出しは一発で行います。
実行結果
今回は検索結果が6件程度なので、この程度のスクリプトで取得できましたが、検索結果が多いケースなどは更に工夫が必要になります。また、更にリンク先も取得したい場合には、データのとり方を変えて、リンク先もスクレイピングが必要になるかと思います。
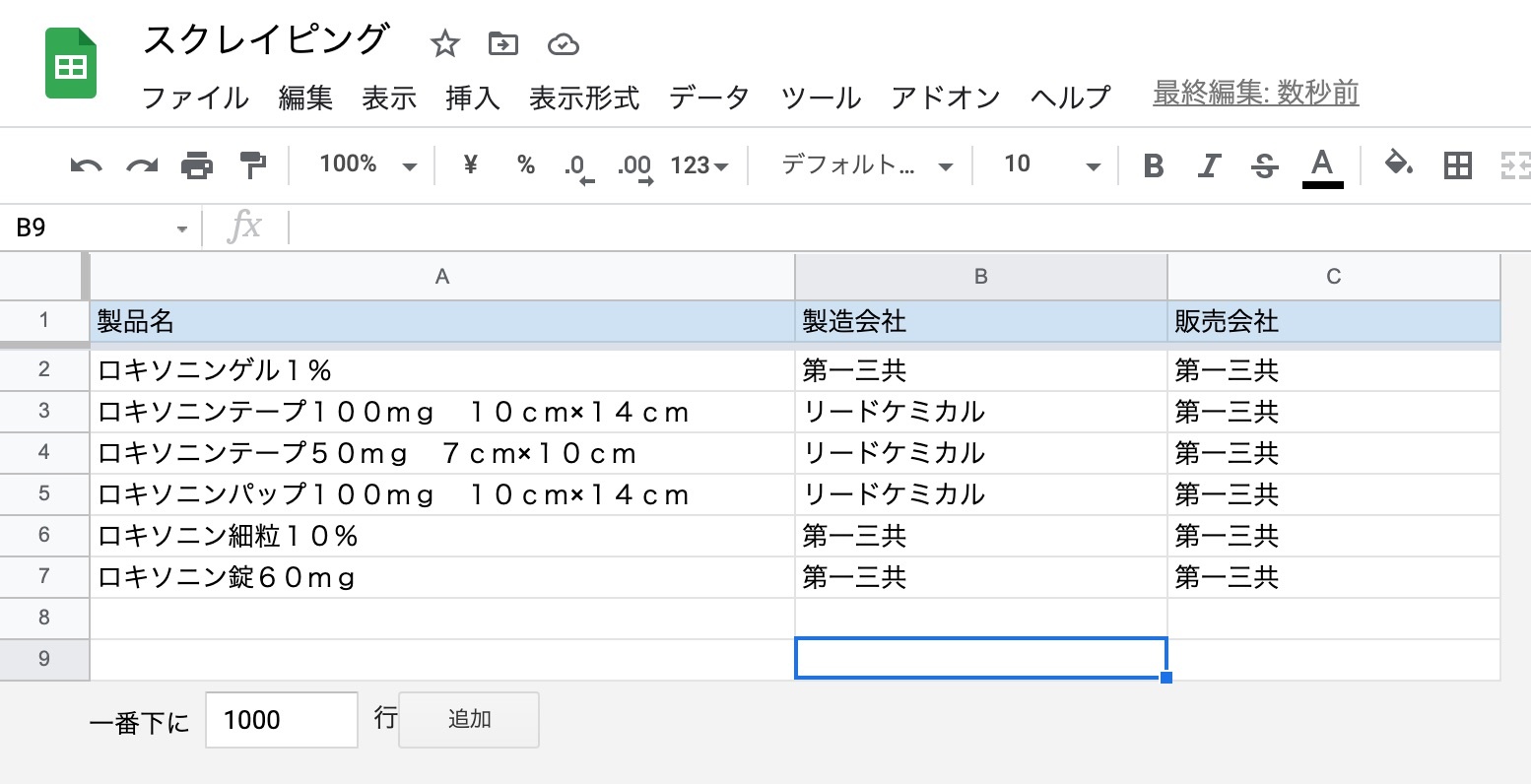
図:検索結果の部分だけを取得できた
501エラーについて
スクレイピングに限らず、UrlfetchAppでウェブサイトの情報を取得したり、自作のREST APIなどを叩いた際に、501エラー(Method Not Implemented)に遭遇することがあります。エラーメッセージの中身や詳細を見ても、そこからは原因をつかめません。
検証をする為に、例えばcurlコマンドでそのURLを叩いたり、ブラウザで開いてみると普通に開ける。Google Apps Scriptだけが問題を吐いて止まる場合がこのケースですが、これはウェブサイト側でWAFをオンにしていたり、海外IPアドレスを弾いてる場合に遭遇するエラーです(さくらインターネットのレンタルサーバにも両方その機能があります)
基本を忘れている人が多いですが、Google Apps Scriptはクラウド側から対象のウェブサイトにアクセスしており、そのサーバは海外にあるGoogleのサーバです。WAFや海外IPアドレスフィルタに引っかかる事は当然の如くあります(なので海外IPアドレスは弾いていても、GoogleのIPアドレスレンジは許可するようhtaccessでセットしたりします)。
故に解決法はWAFを利用してるサーバならばWAFをオフにするか例外設定を追加する、また海外IPアドレスを弾いてるならば、GoogleからのIPアドレス等を調べてAllowにしてあげるが解決策になります。さくらの場合は後者は出来ますが、前者はレンタルサーバの場合オン・オフしか出来ないので、例外設定が出来ないので注意。
※さくらのWAFはGoogleは許可されてたりするので手間がありません。また、IPアドレスフィルタはホワイトリスト機能が用意されてるので、入れておけば許可が出来ます。
UrlfetchAppのキャッシュ制御について
10年くらい前のstackoverflowのエントリーによると、当時はUrlfetchApp.fetchではキャッシュされたページを拾ってきてしまうので、キャッシュではなく現在最新のデータを拾ってくる為に、headerオプションを指定していたようです。現在でもこの仕様なのか?をチェックしてみました。結論から言えば、ページキャッシュされてるサイトでも、UrlfetchAppはキャッシュしないという結果が得られました。
レンタルサーバの特定のディレクトリに以下の.htaccessを配置してキャッシュを実行
<Files ~ ".(css|js|html|gz)$"> Header set Cache-Control "max-age=604800, public" </Files>
この設定を施した同じディレクトリ内にtest.htmlを配置して、以下のようなGASのコードで取得させてみました。手動でページを表示した場合、一度目に取得後に書き換えて、再度同じページを表示させるとブラウザキャッシュが効いて古いまま、再度リロードすると最新のデータが表示されるのを確認しました。
function myFunction() {
var url = "https://officeforest.org/test/test.html";
var res = UrlFetchApp.fetch(url)
var html = res.getContentText('UTF-8');
var head = res.getHeaders()
console.log(head)
// 返り値をCheerioに食わせる
var $ = Cheerio.load(html);
//class指定
var $tomato = $('.tomato');
$tomato.each(function(index, element) {
let value = $(element).text();
console.log(value)
});
}
GASの方では、一度実行し、再度書き換えてもう一度実行してみましたが、キャッシュのヘッダーはたしかに以下のようなレスポンスが返ってきてキャッシュが効いてるのを確認。しかし、データ自体はきちんと最新の状態で取得が出来ました。
{ 'Last-Modified': 'Sun, 09 Oct 2022 10:14:52 GMT',
'Accept-Ranges': 'bytes',
'Content-Type': 'text/html',
ETag: '"9b-5ea975055f509"',
Connection: 'keep-alive',
Date: 'Sun, 09 Oct 2022 10:24:43 GMT',
'Content-Length': '155',
Server: 'nginx',
'Cache-Control': 'max-age=604800, public' }
Cache-Controlの部分がキャッシュが効いてる内容。つまり、現在のUrlfetchAppは相手のサーバがページキャッシュをしていても、最新のデータを取得するようになっている。また、WP-Optimize等のキャッシュ系のプラグインを入れていると、Cache-Controlはno-cacheとなり、きちんと最新のデータが取得出来ました。
また、以下のようなhtaccessの設定にして、キャッシュしないようにしても同様の結果が得られ、手動でページを表示した場合でもリロードすること無く最新のデータが表示されました。
<Files ~ ".(css|js|html|gz)$"> Header set Pragma no-cache Header set Cache-Control no-cache </Files>
ですので、安心してウェブページのスクレイピングで利用できるのではないかと思います。
ライブラリを使ってログインページのスクレイピング
2023年12月2日、Qiitaのとある方がログインクッキーを制御して、ログイン先のページのスクレイピングを可能にするライブラリを提供してくれています。利用するライブラリはGithubでメンテされており、ライブラリのスクリプトIDは「193oTq1hqBLv_A_4vJBAL1tFR6ACM2DoBzVUaIVGcHRpa4rk1-jpN4KR8」となっています。これを追加してコードを実行することで、ログインが必要でセッション維持のためのCookieをコントロールしながらスクレイピングが可能になります。
これをゼロから作るのはなかなか骨が折れる作業ですが、これで手軽に要ログインサイトのスクレイピングが可能になります。サンプルコードは以下の通り。AutoLoginFetchAppとしてリクエストします。
function main() {
const client = new AutoLoginFetchApp.AutoLoginFetchApp('https://localhost/login.html', {
username: 'test_username',
password: 'test_password',
});
const response = client.fetch('https://localhost/path/to/target-page.html');
const $ = Cheerio.load(response.getContentText());
console.log(/Logout/.test($('html').text() ? 'Logged in successful.' : 'Failed to log in.'));
}
Puppeteerを利用する
Google Apps Scriptでは動的なサイトの操作であったり、スクレイピングが出来ませんが、Google Cloud Functionsを利用し、Puppeteerを動かす事で、動的なサイトや複雑なサイトの処理を行わせる事が出来ます。この場合、Google Apps Script側はCloud Functionsの発火とデータの受取に徹し、実際のスクレイピング処理はCloud Functionsが担当するといった役割分担を行います。
Cloud Functionの準備
まず、Cloud FunctionsでPuppeteerを利用できるようにします。事前に請求先アカウント、サービスアカウントが必要ですが、最初の200万回までは無償(月間)で利用が可能のようです。以下の手順で準備します。
- Cloud Consoleにログインする
- 右上のハンバーガーメニュー(≡)をクリックし、サーバーレス項目にあるCloud Functionsをクリック
- 関数を作成をクリック
- 関数名を入れて、us-central1のリージョン、トリガーはHTTP、今回は未認証を選びます。
- この時、URLが生成されてるのでコピーしておく
- 保存をクリックする
- 続けて下にある「ランタイム、ビルド、接続の設定」をクリック
- メモリは512MBを指定、使用するサービスアカウントの指定をして次へをクリック
- Cloud Build APIをオンにしろといわれるので、APIを有効化する
- ランタイムでは、今回はNode.js 12を指定、エントリポイントは最初に実行する関数名を指定します。今回はgetScrapingとしました。
- package.jsonをクリックして、puppeteerをdependenciesに追記する
これでとりあえず、準備は完了。とりあえずデプロイボタンを押します。但しこのデプロイは緑色のチェックマークがついたら成功なのですが、かなり時間が掛かります。
※実行できるユーザを追加したい場合は、権限タブにそのユーザのメアドを追加する必要性があります。再度コードを編集する場合は、編集ボタンをクリックします。
{
"name": "sample-http",
"version": "0.0.1",
"dependencies": {
"puppeteer": "^9.0.0"
}
}
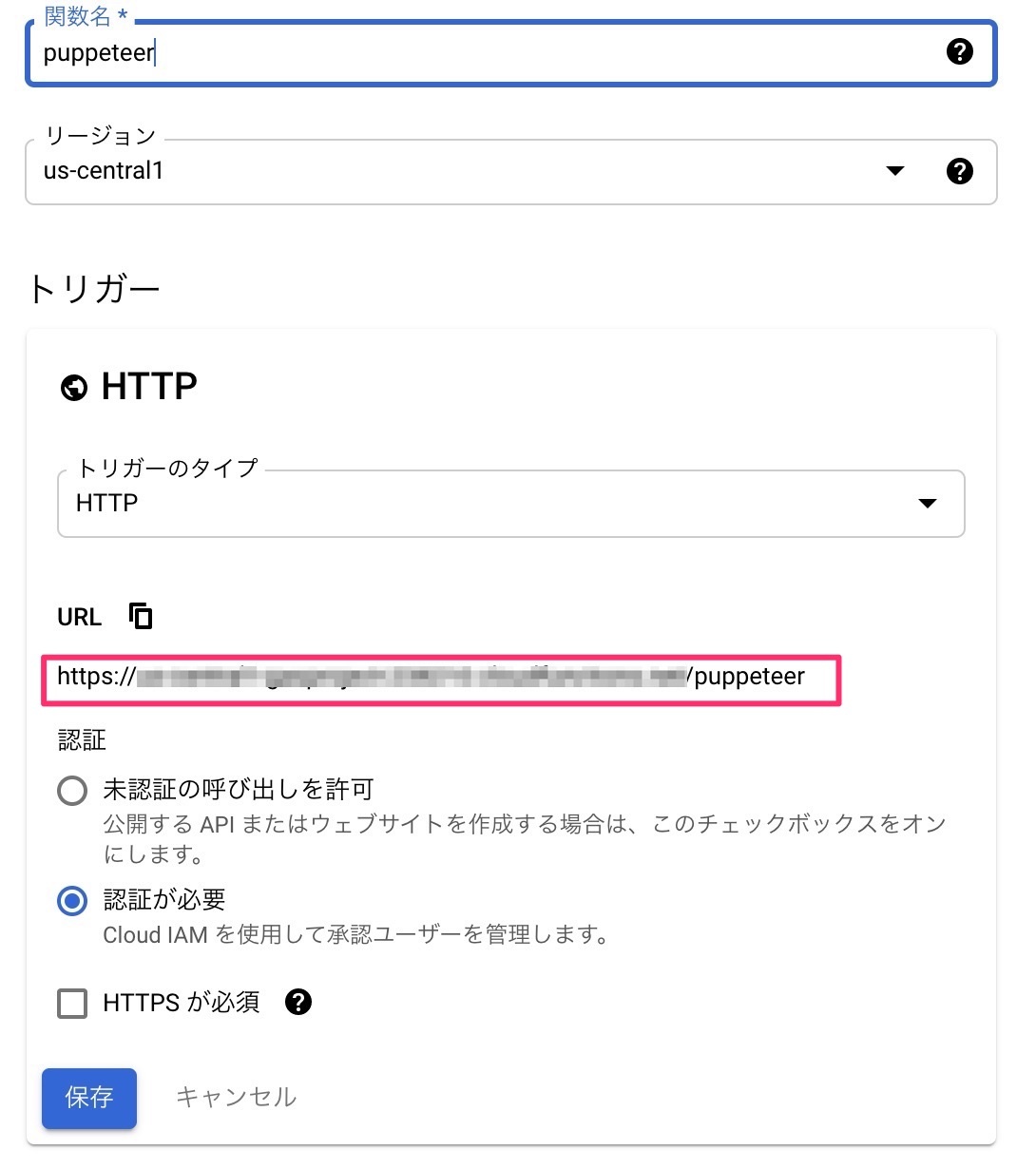
図:以前とだいぶUIが変わっている
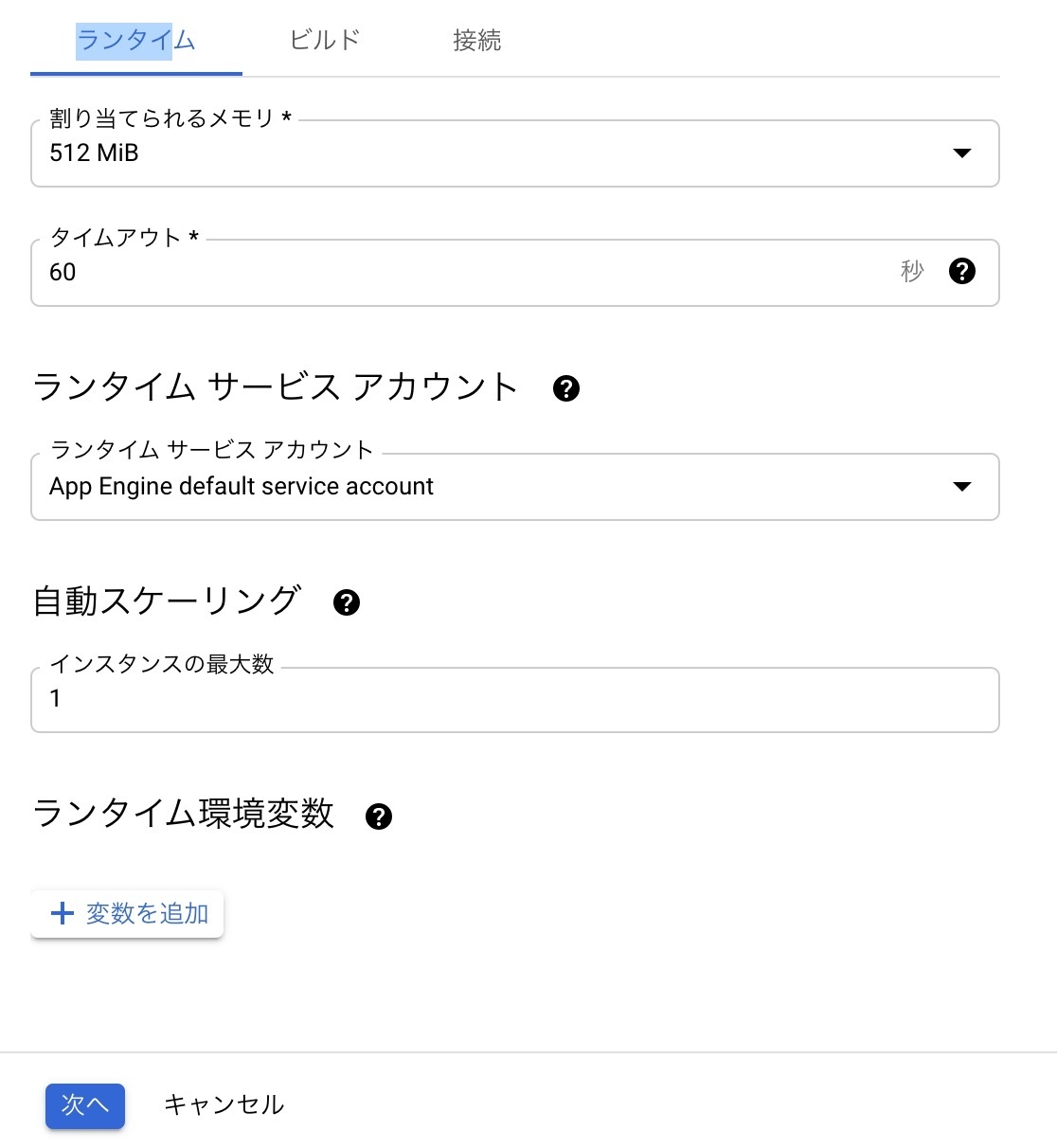
図:サービスアカウントとRAMの指定
ソースコード
ソースコードを再編集して、デプロイを押せば実行可能な状態になります。緑色のチェックマークが付けばデプロイ成功。今回はリクエスト側からURLを引数で取って、そのページを取得して返す仕組みにしています。
デプロイと実行時のchromiumダウンロードに時間が掛かるので、他の環境で開発して動くことを確認したコードをアップすると良いです。テストではコード内にURLを記述して、準備の5.で取得したURLを叩くと実行テストと結果が手に入ります(但し認証を入れてると403エラーが出てしまうので一時解除しておきましょう)
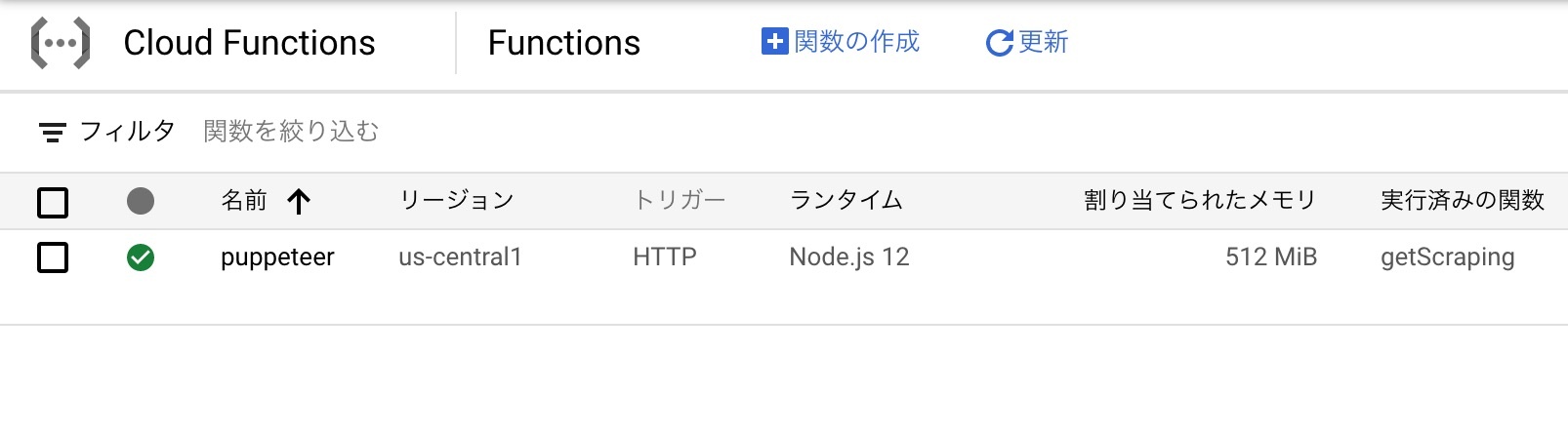
図:デプロイ成功したらOK
GAS側コード
//cloud functionsの関数のURL
var gcfurl = "ここにGCF側の関数実行URLを入れる";
//Cloud Functionsを実行してスクレイピング
function getgcfscraping() {
//uiを取得
var ui = SpreadsheetApp.getUi();
//スプレッドシートを取得
var ss = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("医薬品");
//スクレイピングするURL
var url = "https://icode-search.com/index.php?key=%E3%83%AD%E3%82%AD%E3%82%BD%E3%83%8B%E3%83%B3&stype=1";
//送信パラメータを組み立てる
var payload = {
"url": url
};
//POSTで関数を実行する
var response = UrlFetchApp.fetch(gcfurl, {
method: 'POST',
contentType: "application/json",
payload : JSON.stringify(payload),
muteHttpExceptions: true
});
//サーバーレスポンスコードを取得する
var resCode = response.getResponseCode();
//リターンされて来たデータをスプレッドシートに書き込む
if (resCode === 200) {
//取得した配列を格納する
var drugman = JSON.parse(response);
//1行目に空の配列があるので削除する
drugman.shift() ;
//データを書き出す
var colcnt = drugman[0].length;
var rowcnt = drugman.length;
ss.getRange(2,1,rowcnt,colcnt).setValues(drugman);
//終了メッセージ
ui.alert("データの取得が完了しました");
}else{
//エラーメッセージ
ui.alert(resCode + "エラーが発生しました。");
}
}
- puppeteerのモジュール読み込みで結構時間が掛かります。故に大量のスクレイピングには向いていません。
- また、複数同時にリクエストを受けることを考えて、GCF側のインスタンス数をそれだけ増やしておくと良いでしょう(今回は1なので、1度に1回しか受け付けられません)
- gcfurlに準備でコピーしておいたGCF側のURLを記述します。
- スクレイピングするURLをpayloadとして記述し、POSTで送信します。
- レスポンスコードは今回200しか用意していませんが、色々用意して返してあげるようにすると便利です。
- レスポンスデータは配列なので、JSON.parseしてから取得すると取り出せます。
- 今回のページはなぜか、配列の1つ目が空っぽなので、shiftで削除させています。
- 最後は配列データをシートに一発で書き込みをさせています。
GCF側コード
//モジュールを読み込み
const puppeteer = require('puppeteer');
//Puppeteerを実行
exports.getScraping = async(req, res) => {
//JSONリクエストパラメータを取得する
const json =req.body;
//個別パラメータを取得する
var url = json.url;
//Puppeteerを準備する
//高速化の為に余計なオプションはオフにしておく
var browser = await puppeteer.launch(
{ args: [
'--no-sandbox',
'--disable-gpu',
'--disable-dev-shm-usage',
'--disable-setuid-sandbox',
'--no-first-run',
'--no-zygote',
'--single-process'
]}
);
var page = await browser.newPage()
//ページを開く
await page.goto(url);
//テーブルを二次元配列でスクレイピング
const result = await page.evaluate(() => {
const rows = document.querySelectorAll('#contents > table tr');
return Array.from(rows, row => {
const columns = row.querySelectorAll('td');
return Array.from(columns, column => column.innerText);
});
});
console.log(result);
//取得データを返す
res.status(200).send(result);
}
- 今回は未認証のままなので、URLを知られてしまうと無限に叩かれてしまうので注意
- テーブルデータを二次元配列に変換して、ステータスコードとともに返却しています。
- Node.jsで記述してるので、GCF側でcheerioを使ってスクレイピングしたデータの処理をやらせる事も可能です。

図:テストで無事スクレイピングできた
実行制限をつけたい場合
今回は実行制限を付けずに、Cloud FunctionsのPuppeteerを動作させています。しかし、実際には実行制限を加えないと、URLを知っていれば誰でも叩ける状態になりかねません。そこで、実際に実行するには、特定のメンバーだけに制限したいというケースは、以下のエントリーを参考に、実行できるメンバーを制限しましょう。
Google Workspaceの場合、デフォルトでは組織外の人間はメンバーに追加しても動作しませんので、組織内だけで済みますが、オープンになってる場合には要注意です。
PhantomJS Cloudを利用する
お手軽にJavaScriptを使った動的サイトにも対応してるPhantomJS Cloudを利用してのスクレイピングをGoogle Apps Scriptから操作する事が可能です。クリックやページ遷移などはちょっと工夫が必要みたいです。
事前準備
PhantomJS Cloudは現在、500ページ/1日はフリーで利用することが可能です。元々は、すでに開発終了したPhantomJSを元にクラウドで利用できるようにしたサービスです。利用するには、サインアップしAPIキーを取得する必要があります。以下の手順で取得します。
- 公式サイトに移動してsing up nowをクリックする
- create an accountのページでメアドを入れて、ロボットチェックをしたらsing upをクリック
- メールが届くので、リンクをクリックして開く
- パスワードを設定してFinish and Loginをクリック
- すると、API Keyが表示されるので、コピーしておく
これで完了です。
図:API Keyを取得します
ソースコード
//API Key
var apikey = "ここにAPI Keyを入力";
//PhantomJS CLoudを利用してスクレイピング
function pjscloudget() {
//取得するURLを指定
var url = "https://icode-search.com/index.php?key=%E3%83%AD%E3%82%AD%E3%82%BD%E3%83%8B%E3%83%B3&stype=1";
//HTTPSレスポンスに設定するペイロードのオプション項目を設定する
var option = {
url:url,
renderType:"HTML",
outputAsJson:true
};
//JSON.stringifyしてURLエンコードする
var payload = JSON.stringify(option);
payload = encodeURIComponent(payload);
//リクエストURLを構築
var requesturl = "https://phantomjscloud.com/api/browser/v2/"+ apikey +"/?request=" + payload;
//設定したAPIリクエスト用URLにフェッチして、情報を取得する。
var ret = UrlFetchApp.fetch(requesturl);
//スクレイピングデータを受け取る(JSON形式)
var json = JSON.parse(ret.getContentText());
//HTMLデータ部分を取り出す
var source = json["content"]["data"];
// 返り値をCheerioに食わせる
var $ = Cheerio.load(source);
//class指定
var $tables = $('.table001 td');
//Tableだけ抜き出す
var drugman = [];
var temparr = [];
var cnt = 1;
$tables.each(function(index, element) {
//tdの値を取り出す
let value = $(element).text();
//一時配列に追加する
temparr.push(value);
//カウンタを追加する
cnt = cnt + 1;
//カウンタが4の時はdrugmanに追加し、変数を初期化
if(cnt == 4){
drugman.push(temparr);
cnt = 1;
temparr = [];
}
});
//drugmanをスプレッドシートに書き出す
var ui = SpreadsheetApp.getUi();
var ss = SpreadsheetApp.getActiveSpreadsheet().getSheetByName("医薬品");
var colcnt = drugman[0].length;
var rowcnt = drugman.length;
ss.getRange(2,1,rowcnt,colcnt).setValues(drugman);
//終了メッセージ
ui.alert("取得完了");
}
- 後半はこれまで同様、Cheerio.gsに食わせて、解析をすればOKです。
- レスポンスデータの中のcontent -> dataの中にスクレイピングしたHTMLデータが入ってるので注意。
- Cloud Functionsのような環境構築が不要な点は楽です。
- Clickなどの複雑な操作はAPIドキュメントを読むとoverseerScript指定にて、Puppeteerのように出来るようです。

図:スクレイピングデータの格納場所に注意
関連リンク
- スクレイピング練習用サイト - Webスクレイピング入門
- GASでスクレイピングする方法!Parserライブラリを利用した手順を解説
- Quotas for Google Services
- PhantomJS Cloud
- Google Apps Script(GAS)を使ったwebスクレイピング
- IAM による Cloud Functions へのアクセスの承認
- Cloud Functions with Puppeteer + Google Apps Script でスクレイピングサーバーをサクッと作る
- Node.js(cheerio) を使ってスクレイピング
- List of Chromium Command Line Switches


phantomeJSをコピペで試そうとしたら、医薬品サイトが閉鎖されていてエラーになってしまいました。
昨年末に閉鎖されてしまったようですね。
代替のサイトは、http://www.medd.jp/sc/guests/HNS20001.cfmが利用可能のようですが、スクレイピングすることは可能だと思いますが、コードは変えていかないと利用はできませんね。