SQLiteデータベースの活用まとめ - 前編
ElectronやNode.jsなどで業務用アプリを作るとなると、割と避けられないのがデータベースの使用。サーバー型のMySQLやPostgreSQLを使うことになると思いますが、オフラインでの使用やスマフォ用となると、SQLiteがなんだかんだ行ってもベターです(NoSQLデータベースもありますが)。
今回は自分の為のメモとしてSQLiteを扱うアプリでのコードスニペットや知見として色々とまとめておこうと思います。(言語はNode.jsで操作をしています)
※データ量が多くなってしまったので、前後編に分けました。後編はこちらから
目次
今回使用するライブラリ等
DBの作成やビューの構成などは今回はDB Browser for SQLiteを利用して作成します。Windows,macOS,Linuxとマルチプラットフォームにアプリが用意されています。
データベースの作成
データベースの型
SQLiteは他のデータベースと異なり、けっこう型の扱いはラフに作られています。サーバー型のDBやAccessなどから比較しても、型の取り扱いが厳格ではないので、扱いやすくスマフォのアプリなどでも不動の地位を築いています。
大きく5つの型が用意されており、列の型になります。
- Integer - 整数値を格納
- Text - テキストを格納(UTF8,UTF16で格納)
- Blob - バイナリデータを格納(ファイル等)
- Real - 浮動小数点を格納
- Numeric, Null - なんでも型(Accessの変数で言う所のVariantみたいなもの)
となっています。BooleanやDateといった型が存在せず、関数などで処理を行うことになります。この辺りがおいおい開発を行う上での壁になります。
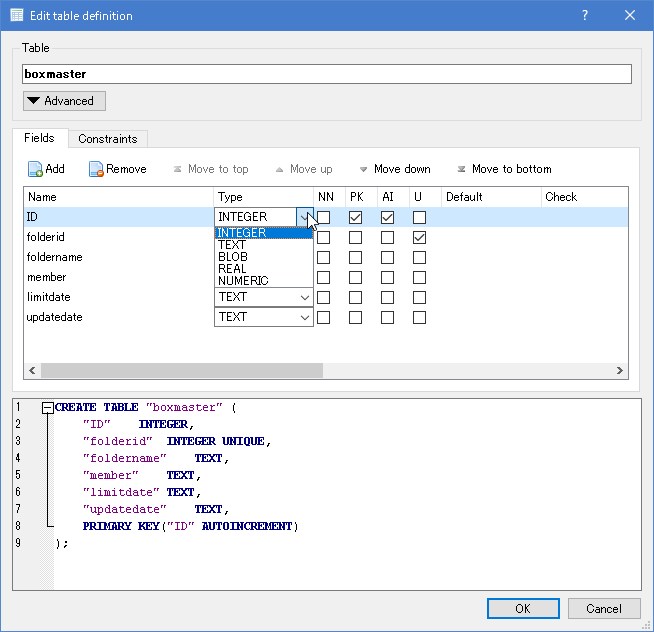
図:5つの大きな型だけがある
インデックスの作成
MySQLやAccessの場合、テーブル作成時に通常、AutoincrementなID列にインデックスを同時貼れるのですが、SQLiteの場合は作成後に任意にインデックスを作成する必要があります。検索時などの高速化などで必要なインデックスですが、高速化だけでなく重複を許可しないなどの制約を加える為にも必要となります。以下の手順で作成します。
- テーブルを作成する
- 作成後にDB BrowserのメニューよりEdit -> Create Indexを開く
- nameに適当なインデックス名を付け、重複を許可しない場合はUniqueにチェックを入れます。
- Columnsよりインデックスを貼るカラムを選び、▶をクリック。ソートを選択
- OKをクリックするとインデックスが作成されます。
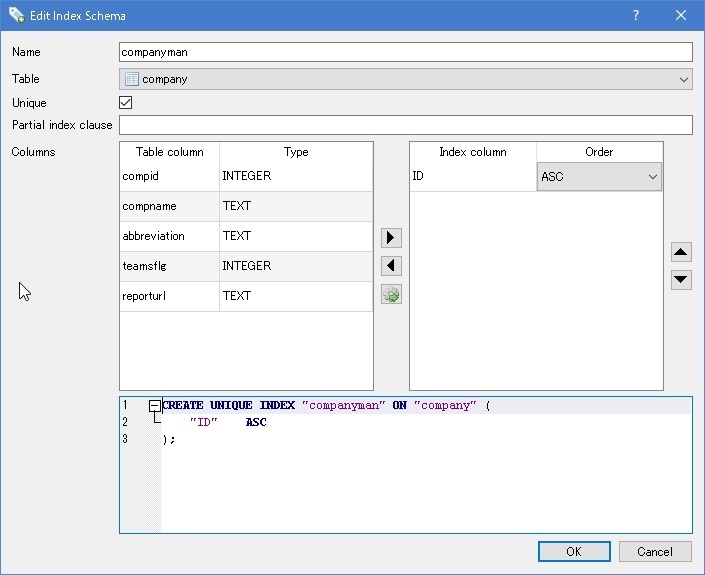
図:忘れずに作成しましょう
外部キー制約
Accessでいう所のリレーションシップに於ける連鎖更新・連鎖削除の設定。設定しておく事でマスタ側で例えば削除された場合、連結してるサブマスタ側でも同じIDを持つレコードが連鎖削除されたりします。逆にマスタ側にないIDをサブマスタ側で追加する事を制限する事が可能です。
DB Browserを利用した場合にはテーブルのカラム項目の一番右側に「Foreign Key」の項目があります。ここで
- サブマスタ側のテーブルを開く
- 連結したいカラムを決める(例えば親IDといった列)
- Foreign Keyの部分をダブルクリックする
- プルダウン等が出てくるので、左からまず紐つけるマスタ側テーブルを選択する
- 連結するマスタ側の列を選択する(今回はマスタ側のID列)
- 最後のボックスには、DELETE CASCADE ON UPDATE CASCADE を入力する
これで削除時、更新時に連鎖的に動作するようになります。CASCADEで連鎖更新・連鎖削除の動作となります。RISTRICTでマスタ側で削除・更新を行うとエラーとなる動作となります。他にもSET NULLでマスタ側で削除・更新を行うとNULL値になるといったものがありますが、通常はCASCADEとRISTRICTの2つを利用します。
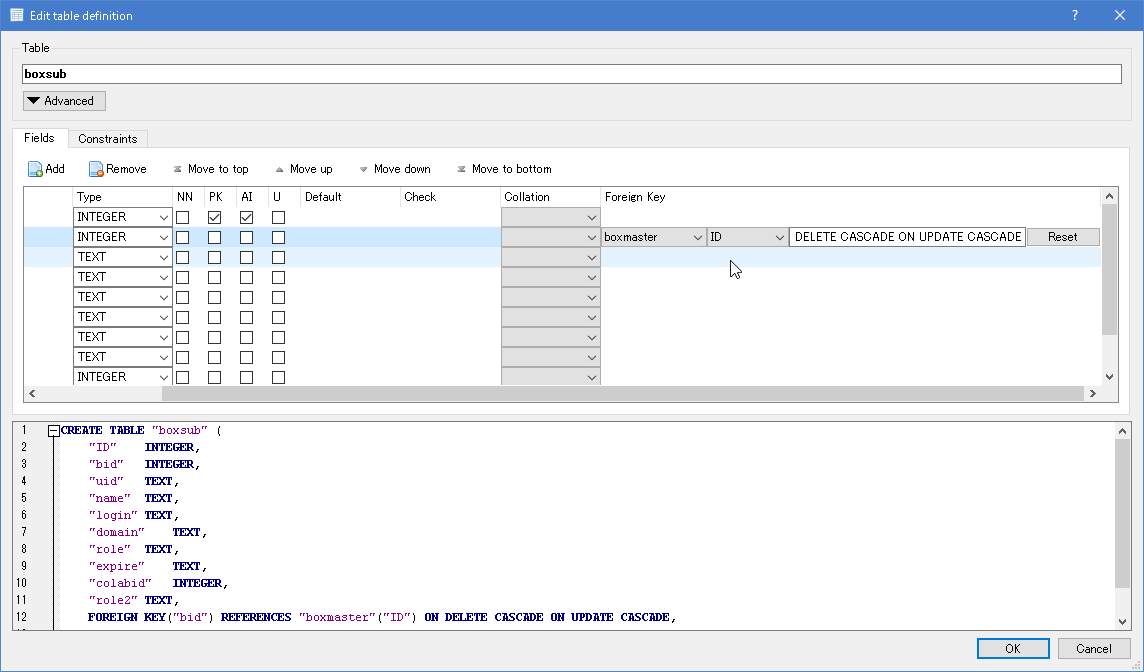
図:データの更新漏れを防ぐのに有効
インポート・エクスポート
テーブルを作成後、プログラムを作るにあたってやバックアップを取る為の機能がDB Browserには備わっています。インポートではSQLファイルおよびCSVファイル、エクスポートではSQLファイル、CSVファイル、JSONファイルに対応しています。
プログラム作成時のサンプルデータを用意するのにこの機能を使ってテストをしましょう。
エクスポート処理
以下の手順でファイルをエクスポート出来ます。CSVの場合は1つのテーブルを1ファイルとして、SQLファイルの場合は1個のファイルにして出力します。また、SQLファイルの場合は出力時にインポートする時のInsert文に対してのオプション設定を行うことが可能です。ファイル -> Exportで実行します。
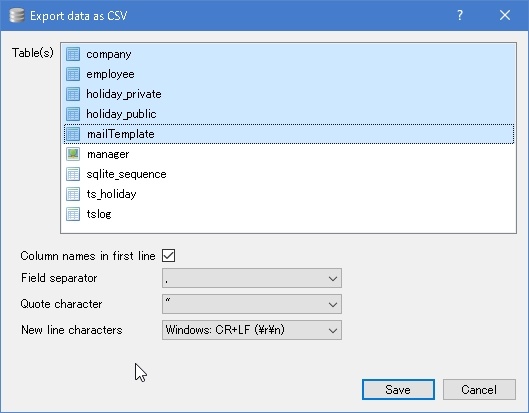
図:CSVの場合の出力画面

図:SQLの場合の出力画面
インポート処理
出力しておいたCSVファイルやSQLファイルをSQLiteのデータベースにインポートする機能です。インポートには2種類あり、テーブルが存在していない場合に新規にテーブルを作ってインポートと、既存のテーブルにインポートの2つになります。後者の場合、データが空ならば問題ないのですが、インデックスを張っていたり、カラムがUnique値を設定してる場合、インポートはエラーになります。予めデータは空にしておきましょう。通常はCSVでバックアップを取っておくと良いでしょう。
ファイル -> Importの実行で取り込めます。
CSVファイルはUTF-8 BOM無しで用意しておきましょう。
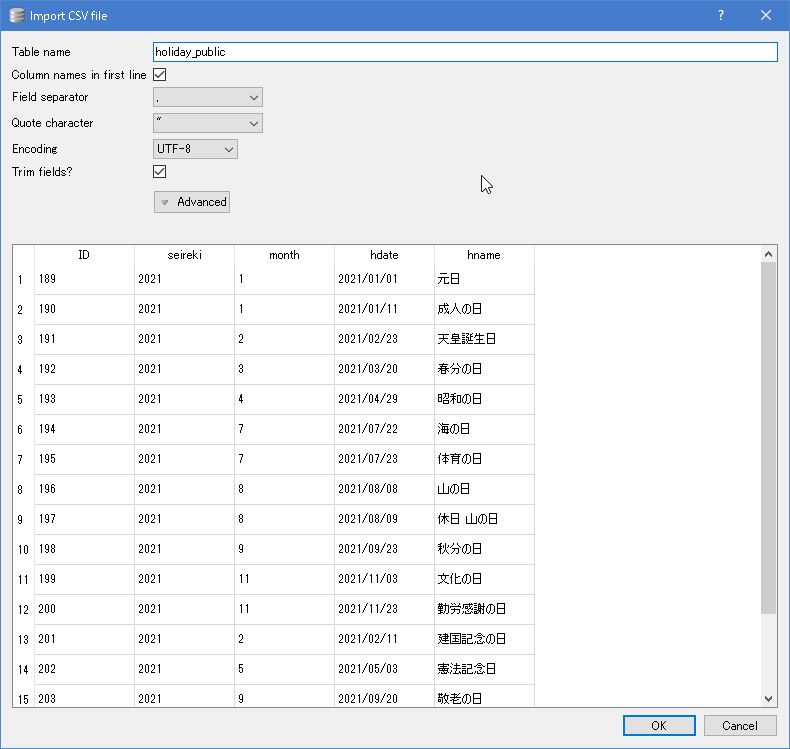
図:CSVであらかじめデータを作っておくと良いでしょう
ビューの作成
DB Browser for SQLiteではAccessのようにGUIからビュー(クエリ)を作成する機能がありません。そのため、作成するにはSQL文を叩いて作成する必要があります。また、すでにビューを作成してる場合、変更をする場合は一旦、ビューをドロップしてから作成する事になります。
作成手順は以下の通りです。
- DB BrowserのExecute SQLを開く
- SQL文として、以下のような構文を入力する
CREATE VIEW VIEWの名前 AS SELECT * FROM MASTER;
CREATE VIEW VIEWの名前に続けて、SELECT文を続ければ良いだけ。SQLiteはシンプルなので方言的にはAccessほどキツくはないので、SQL文を作るのが苦手な人は、Accessのクエリで作ったSQL文でもここにCREATEに続けてコピペでも、ビューを作ることは可能です。
※ビューが存在する場合、それを用いたテーブルに変更を加える場合も同様に一旦、ビューを削除しなければなりません。
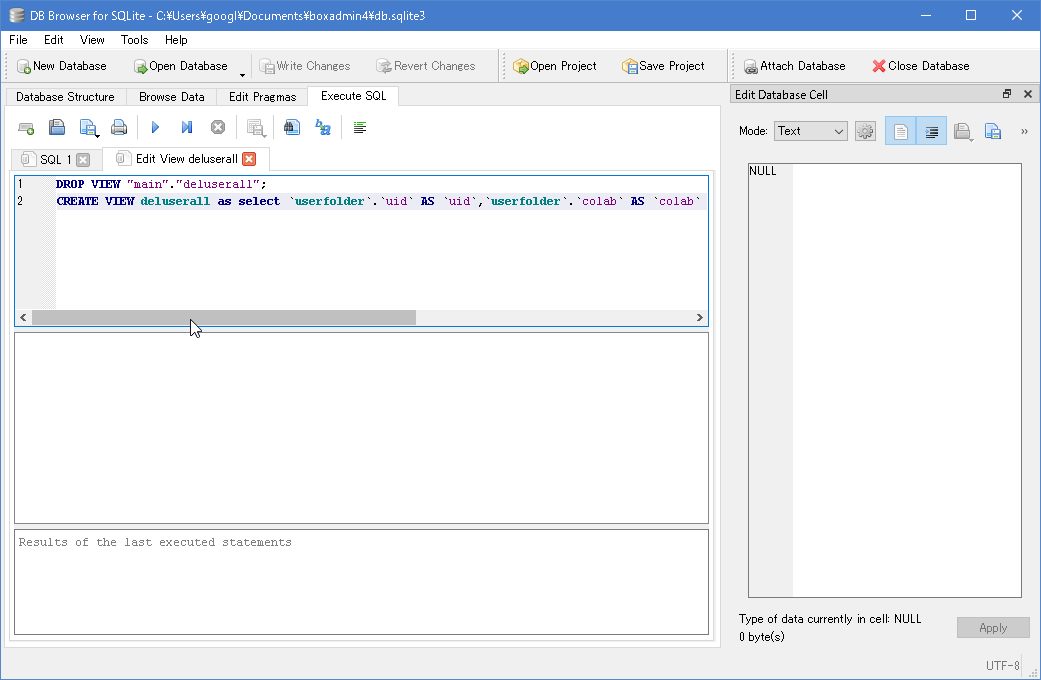
図:ビューを作成する画面
テーブルの結合
テーブルの結合には、内部結合、外部結合、ユニオンの大きく3つがあり、他にも交差結合や自然結合などが用意されています。ビューを作成する上で、2つ以上のテーブルを連結してビューを作成するには必須です。
内部結合
連結する列においてお互いのテーブルで同じ値を持つものだけを抽出して連結します。マスタ側にしか無いようなデータの場合には、ビューには出てきません。必ずマスタ・サブマスタ両方に同じID等を持つデータが必要になります。
SELECT * FROM MASTER INNER JOIN SUBMASTER ON MASTER.ID = SUBMASTER = MID
上記の例では、masterテーブルのIDとsubmasterのMID列を連結し、お互いに同じ値を持つレコードが抽出されます。
外部結合
連結する列において片方のテーブルにだけデータがある場合でも抽出してくれる連結方法です。マスタ側にだけデータがあってサブマスタに無い場合でも、マスタ側のデータが抽出されるようになります(サブマスタ側の値は空っぽのままになります)。
SELECT * FROM MASTER LEFT OUTER JOIN SUBMASTER ON MASTER.ID = SUBMASTER.MID
但し、SQLiteはRIGHT OUTER JOINをサポートしていないので、サブマスタ側からマスタ側への外部結合は利用出来ません。
ユニオン
2つの全く同じカラムと型を持つテーブルを1つのテーブルに合体させる、Accessでいうユニオンクエリに該当するものです。例えば支店毎にテーブルを作成しておき、各々の支店はそちらのテーブルを参照。管理者はこれらを結合させたユニオンビューを持って処理をするといったようなセグメントを設ける場合に利用します。
SELECT * FROM SIBUYA UNION SELECT * FROM SHINJUKU
上記の例では、SHIBUYAテーブルとSHINJUKUテーブルは全く同じタイプのテーブルで、2つを1つのテーブルにUNION句を使って結合させます。但し注意点として、この場合のビューでお互いにある連番の列(Accessで言う所のオートナンバーに該当)する列は、重複しないような値にするべきでしょう。また、そのレコードがどちらのテーブルに該当するレコードなのかの見分けがつかないと、コードを書く時に面倒です。
日付の差分を取る
SQLiteは日付型というものが列の型に存在しないので、例えば2つの日付の差分を取る場合どうしたら良いのか?と言うと、用意されてる関数をSQL文内で利用して差分を取る事が可能です。また、この時の日付はyyyy/mm/ddではなくyyyy-mm-ddの形式である必要があるので、よくある日付の型の場合には変換が必要になります。
例えばサブマスタの日付列の値と現在の日時からの日付差分をdiffdateとして演算する場合は以下のような構文になります。
SELECT *,
CAST(julianday(replace(SUBMASTER.expire,'/','-')) - julianday('now') as integer) AS `diffdate`
FROM SUBMASTER
- 日付がyyyy/mm/ddの場合はreplace関数でスラッシュをハイフンに変換してあげます。
- 日付の差分として取りたい場合は一旦、日付の値をjulianday関数で数値に変換します。
- julianday('now')にて現在の日付の数値を取得出来ます
- 差分を取る場合には、上記の関数で変換した2つの値をマイナスで差し引きし、CAST関数でinteger型に変換して列名を設定します。
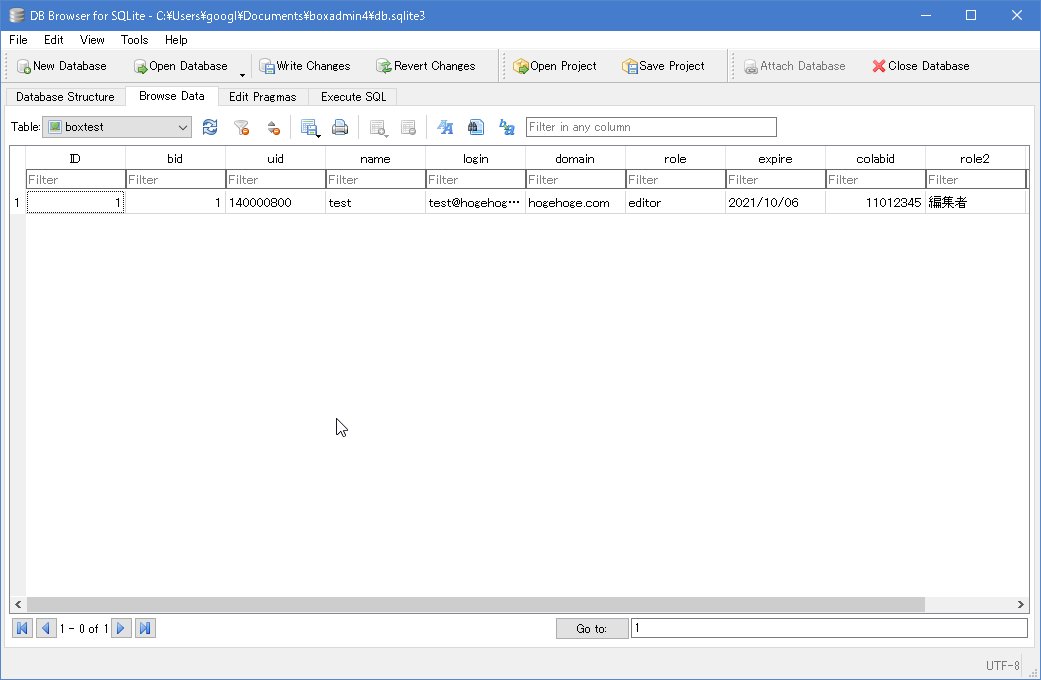
図:expireの日付から現在日付の差分をdiffdateとして取り出した
時刻の差分を取る
日付の差分だけでなく、給与計算に於ける勤怠などで活躍するのが「時刻の差分」を取ること。09:00 - 18:00といったような日付データの無い値でも差分を取ることができます。SQLiteの関数を使って差分を取りますが、秒で取れるので分に直す60で割るところまでを含めると良いです。
例えば、出勤時刻と退勤時刻の差分を取る場合には以下のように組みます。
select starttime,endtime,
(strftime('%s', endtime)-strftime('%s', starttime))/60 as sabun
from earlyhosei
- 差分を取る時は退勤時刻のendtimeから出勤時刻のstarttimeを差し引きします
- 差し引きした値は秒なので、コレを分に直す60で割ったものをsabunという名の列として表示
- 時刻文字列を時刻として認識するにはstrftime関数を利用します。
- オプションの%sを%Mにすれば、秒ではなく分で取ることも可能(その場合60で割るといったことは不要)。オプションは結構豊富にあります。
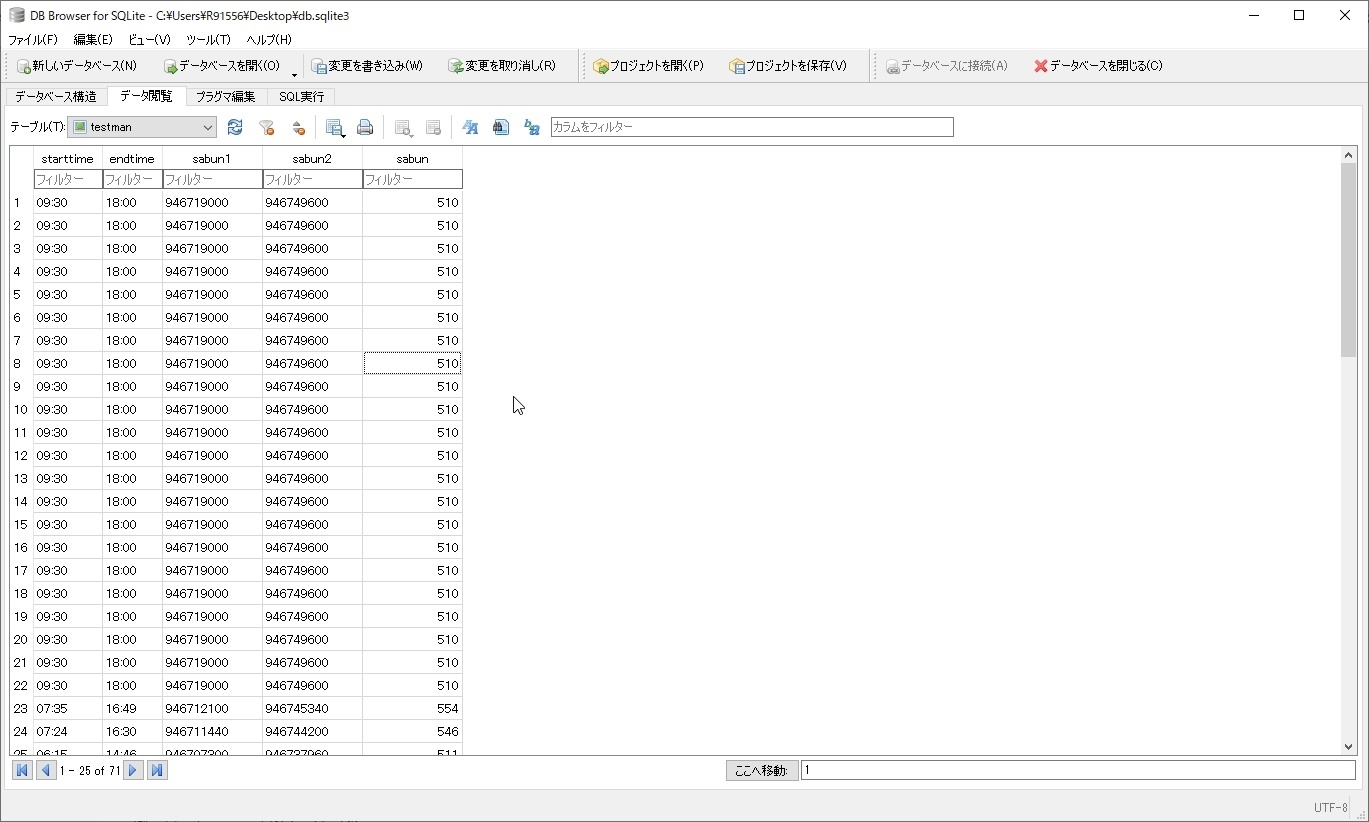
図:無事に差分を取る事ができました。
条件判定をする
Accessなどでは、計算列として特定の値の内容を元に条件判定した結果をIIF関数を使って処理することが結構あります。クエリ上で数式を構築して判定が出来るのでコードの節約にもなりますが、これをSQLiteで実現する場合、IIF関数が使えるわけではないので、躓くポイントになります。またその時に「○○を含む場合」といったケースでは、Like演算子を使う点は同じですが、ワイルドカードの指定方法が異なるので、ここも含めて
「特定の列の値に【固定】という文字列が含まれる場合には、-1を、そうでない場合0を返し、judgmentという列で表示する」
を実現する場合以下のようになります。多数含まれるデータに対して行ったのでグループ化していますが、グループ化は必須項目ではありません。
SELECT tslog.empid, tslog.empname, tslog.kinmu,
CASE
WHEN tslog.kinmu Like '%固定%' THEN -1
ELSE 0
END as judgment
FROM tslog
WHERE judgment = -1
group by empid, empname, kinmu
order by empid
- 条件判定は、CASE~WHEN句を使って行わせます。
- WHENが○○の場合といった形で複数追加できるので、IFというよりSELECT文のようなスタイルです
- ELSEは上記の条件以外の場合、VBAのCASE ELSEに該当します。
- ENDで終わらせて、as judgmentで列として表記しています。
- THENで値を返します。
- ○○を含む場合には、ワイルドカードをLike演算子とともに使いますが、アスタリスクではなく「%」で括ります。
- グループ化する場合、通常の列はgroup byでグループ化しますが、判定列は演算列なのでグループ化する必要はありません。
- WHERE条件をつけて、judgmentの値が-1のだけを抽出も同時に行えます
グループ化
レコードデータを特定列でグルーピングし、合計や平均、カウントなどを行うためのGROUP BYを使うことが可能です。さらにこのグループ化後のデータに対しては、HAVING句を用いて条件設定をすることで抽出する事も可能です。
SELECT uid,count(uid) AS `sharecnt` from SUBMASTER GROUP BY uid HAVING sharecnt > 0
上記の例では、SUBMASTERのuid列だけを取り出し、カウントの列としてsharecntを設ける。group byにてuid列をグルーピング化しています。また、havingにてsharecnt列の値が0より上のレコードだけを抽出するように条件設定も加えています。
count関数などの集計関数はグループ化していないと利用出来ませんし、このグループ化は基本最初に取り出したすべての列に対して設定しなければならないので、group byの後に全部の列が列挙されていないとエラーになります。どういった列だけ取り出しグループ化すべきかが悩むポイントです。
※但し、SQLiteはAccessのようなPivot句には未対応なので、クロス集計は出来ません。ので、アプリ側でピボット前のデータからクロス集計データを配列で作ってあげるなどの対応が必要になります。
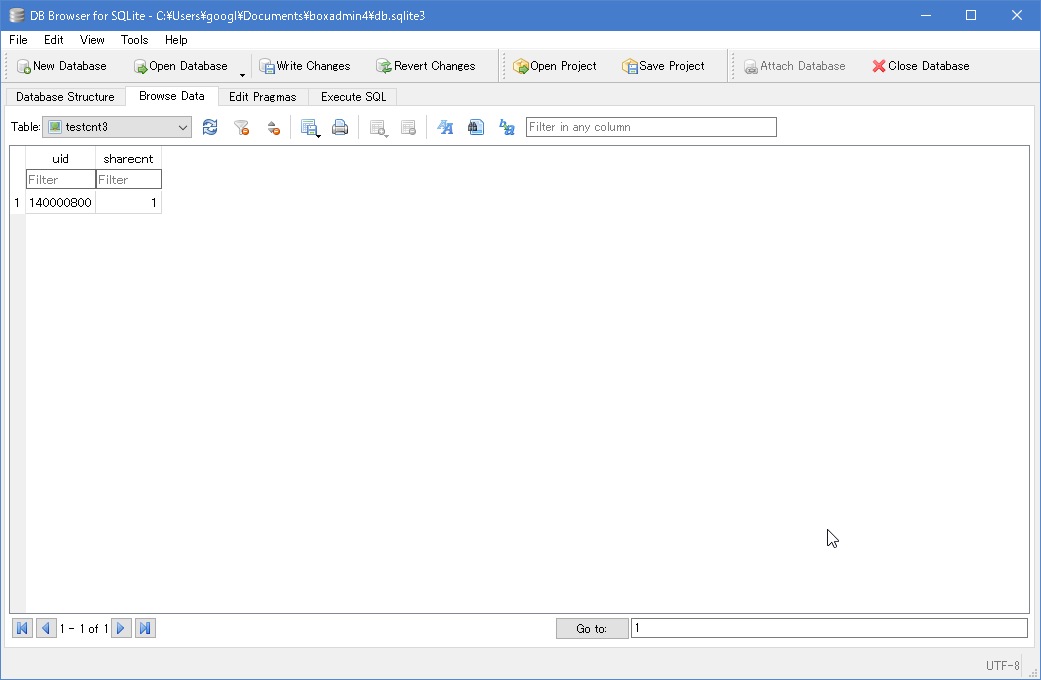
図:集計では必ず使うグルーピング
トリガー
あるテーブルにデータを追加や更新を掛けた時に、別のテーブルに対してもなんらかのSQL文を自動で発行して作業をさせる為のものがトリガーで、例えばINSERT履歴を自動で残したり、レプリカのテーブルに自動で追加したり、プレ集計を行わせておいて実際の集計時間の短縮など、プログラミング無しで行わせる便利な反面、プログラミングほど自由度があるわけではないので、使い所は選ぶ機能です。
ビュー同様、DB Browser上ではSQL文を叩いて作成を行います。作成手順は以下の通りです。
- DB BrowserのExecute SQLを開く
- SQL文として、以下のような構文を入力する
CREATE TRIGGER トリガー名 UPDATE ON テーブル名 BEGIN insert into info (name) values(new.foldername); END
上記の例だと、テーブル名に対して UPDATE をした時にBEGIN以下のSQL文を実行するという意味になります。自動実行するSQL文は複数設置可能で、UPDATE以外にINSERT、DELETEがあります。
SQL文ではnewをカラム名につける事で新しい値、oldをつけることで古い値を取得し、INSERT文などで利用することが可能です。

図:但しトリガーは多用するべからず
データベース暗号化
SQLiteにSQLCipherという仕組みを組み合わせて、セキュアなデータベース運用を行う事が可能です。DB Browser for SQLiteインストール時に通常はノーマルなSQLiteのみがインストールされますが、オプションでSQLCiperを選ぶと、暗号化対応版のDB Browser for SQLiteも別途インストールされます。
インストール後はすぐに使える状態になっており、
- ツールより「Tool」-> 「set encryption」を選ぶ
- パスワードを入力し、暗号化オプションを選び、OKをクリック
- セットされると再読み込みされて、パスワードを再度入力するとオープンできるようになります。
但し暗号化したSQLiteファイルの場合、プログラムからの読み書きはSQLCipher対応のモジュールが必要で、Node.jsだとnode-sqlite3ではなく、better-sqlite3-sqlcipherを利用することになります。(node-sqlite3でも自力でビルドすればSQLCipher対応できるようですが)
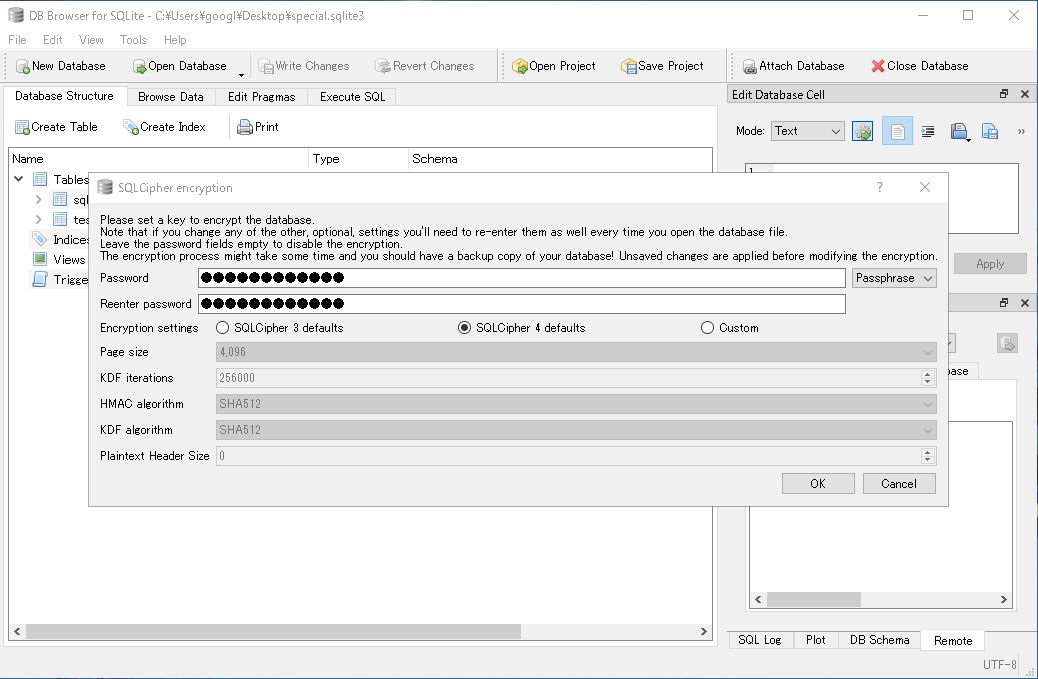
図:暗号化SQLiteを作成中
Vacuum
SQLiteも立派なデータベース。データの追加や削除、テーブルの削除などに伴って、本来であれば減った分だけファイルサイズが減るべきなのですが、SQLiteはテーブル作成時にオプション指定で、Vacuumの指定をしていないと、DBが肥大化する事があります。SQLのVacuum文を任意に実行する事で、残ったノイズデータ文だけシュリンクしてくれるわけですが、毎回手動で行うのもちょっと考えもの。
ということで、テーブル作成前でなければなりませんが、DB Browser for SQLiteにてAuto_vacuumのオプション指定をしておきましょう。
- DB Browser for SQLiteで新規にデータベースを作成する
- タブのプラグマ編集を開く
- Auto Vacuumの項目を「Full」に指定する
- データベースにテーブルを作って保存する
Vacuum文はノイズの除去とフラグメント解消をしますが、Auto Vacuumはトランザクション -> コミットのたびにノイズ除去をしますが、フラグメント解消はしません。
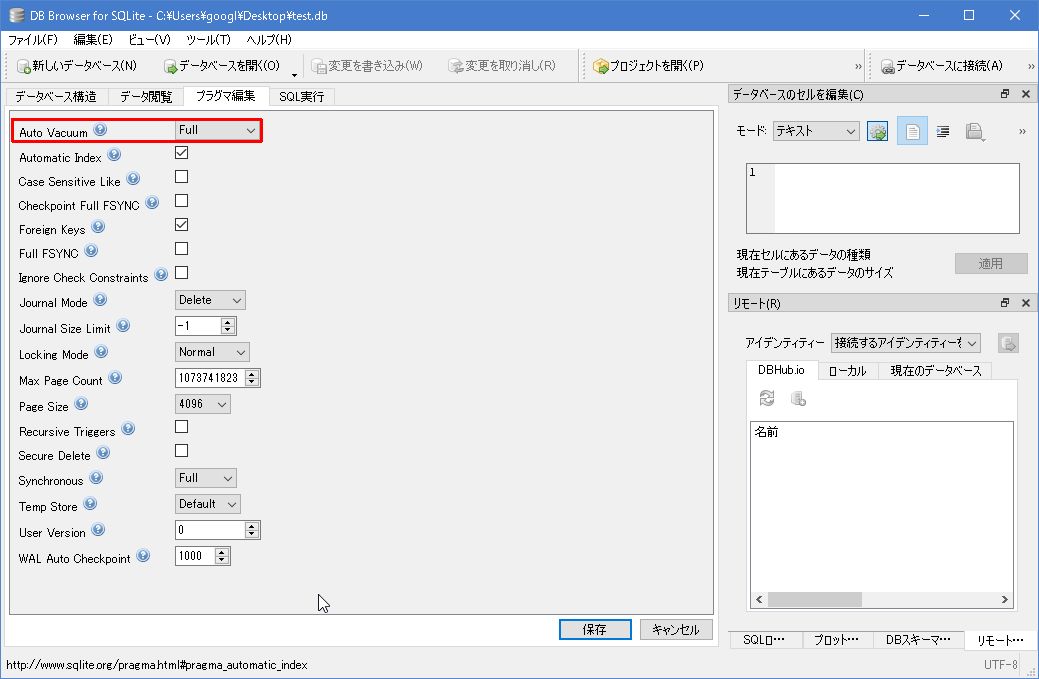
図:Auto Vacuum設定はテーブル作成前に
SQLiteの読み書き
Node.jsなどのアプリでSQLiteに接続してデータを読み書きする場合、メソッド毎に読み書きの構文を書いているとプログラムが冗長になってしまうので、通常はSELECT, INSERT, UPDATE, DELETEの代表的な4構文に関しては関数化しておいたり、もう一歩進めてクラス化しておいて使うと、再利用性が高まって、見通しが良くなります。
冒頭部分
//SQLite3ファイルに接続
const sqlite3 = require('sqlite3').verbose();
var dbfile = __dirname + '/db.sqlite3';
var db = new sqlite3.Database(dbfile);
Node.jsの場合、上記のコードのように予め接続するdb.sqlite3ファイルの場所を指定し、接続しておくようにします。基本的に個人で使うデータベースであるため、マルチユーザで同時書き込みをするようなものには用いないので(サーバで使う場合は別ですが)、自分の場合はMySQLの時のようにロックを考慮したりしません。また暗号化についてもデフォルトでは未対応であるため、別の手段を用意する必要があります。
必要な時に開いて、そして閉じるというシンプルな処理を4パターンに応じて作っています(実際には2パターン辺りまで統合できますが)
インメモリ化
以下のように、:memory:を加えると、SQLiteのインメモリデータベース化が可能です。
var sqlite = require("sqlite3").verbose();
var db = new sqlite.Database(":memory:",sqlite.OPEN_READWRITE | sqlite.OPEN_CREATE);
open_readwrite, open_create, open_readonlyの3種類のモードがあります。
必要な時に接続し終了する
アプリで使用する場合、基本的に個人なので、冒頭でsqliteのファイルを読み込み開きっぱなしでそのまま運用する事が多いですが、必要な時にだけ接続して、SQL実行後にはきちんとクローズする場合には、冒頭で接続しっぱなしにするのではなく、都度インスタンス化してCloseさせます。
var sqlite = require("sqlite3").verbose();
var dbfile = __dirname + '/db.sqlite3';
function tomato() {
//インスタンス化
db = new sqlite.Database(dbfile);
//値
var values = ["tomato",100];
//SQL文を実行
db.run(`UPDATE yasai SET vname = ? WHERE id = ?`, values, (err) => {
if (err){
return console.log(err);
}else{
// データベースを閉じる
db.close(err => {
//エラーハンドリング
if (err) return console.log(err);
});
}
});
}
次にまた接続する場合は、再度、new sqlite.Databaseにてインスタンス化してから処理を行うことになります。
SELECT
SQL実行関数
//SQLiteへのSQL発行(select)
function sqliteselect(query,callback){
//SQLiteファイルからOAuth情報を取得する
db.serialize(function(){
//SELECT文を発行する
db.all(query,function(err,rows){
if(err){
//メッセージを表示
//メッセージオプション
var options ={
type:'info',
title:"エラーメッセージ",
button:['OK'],
message:'データ取得エラー',
detail:String(err)
}
//表示する
dialog.showMessageBoxSync(null,options);
return;
}else{
//取得したデータを変数に格納しておく
callback(rows);
}
});
});
}
クエリを受け取って実行し、成功したらrowsにレコードが入ってるので、callbackで呼び出し元へと返しています。SQL文ついては以下のようになります。もちろん、ビューに対してSELECT文を発行することも出来ます。
var query = "select * from manager where company = 1"
呼び出し側
callbackされてきたrowsの値を取り出し、それぞれをretmanという連想配列にデータ部分と件数とにわけて入れ込み、Electronの場合はレンダラ側にevent.sender.sendで送っています。
var retman = {};
sqliteselect(query,function (rows){
//取得データを返す
retman.data = rows;
retman.count = rows.length;
event.sender.send(sender, retman);
return;
});
指定件数ずつ取得する
一度に大量のデータを取得するとプログラム側にとって少々不具合が出るケースというものがあります。いきなり全件取得ですと表示するまでに時間が掛かるので、遅延ロードなどを併用して10000件ずつ取得して表示などなど。こういったケースでは、次の10000件を取得して既存のデータに追加するといった処理を装備しますが、SQLite側で「次の10000件を呼び出し」といったことをするためには、offset句とLimit句を利用します。
var query = "select * from jisseki limit 10000 offset " + offset + ";";
//クエリを実行
sqliteselect(query, function (rows) {
//取得データを返す
retman.data = rows;
retman.count = rows.length;
event.sender.send(sender, retman);
return;
});
上記の例の場合、offset変数に値を入れることで、データの取得位置(行番号)を変更出来るようになる。初期値は0とし次の1万件を取得したいならば、offsetには10000を入れる(0からスタートしてる点に注意)。つまりこれが、データの取得開始位置となる。
Limit句で10000件を取得するように同時に制限を入れないと、offsetの位置から後ろのデータを全部取得してしまうので注意。
重複してるレコードを抽出
重複してるレコードの対象を抽出するSQLになります。重複していないレコードについては除外されます。例えば同じ社員IDのレコードが本来重複してもらっては困る場合に、重複してる者リストを作るときに利用します。単純に各IDのカウントを取り、その件数が1より上のものを取り出せばOKです。あとはこれによってできたビューに同じ台帳をJOINしてあげれば、重複してるレコードの全体を見ることも可能です。
SELECT jobtypelog.empid, COUNT(jobtypelog.empid) AS numdup FROM jobtypelog GROUP BY jobtypelog.empid HAVING COUNT(jobtypelog.empid) > 1
INSERT
SQL実行関数
//SQLiteへのSQL発行(insert)
function sqliteinsert(query,values,table,callback){
db.serialize(() => {
db.run(query, values,function(err) {
if (err){
callback(["NG",err]);
return;
}else{
//最終行のrowidを取得する
let lastrowid = this.lastID;
//追加した行のAuto inrementのIDを取得して返す
db.all("select *, rowid from " + table + " where rowid = " + lastrowid, function (err, row) {
var retid = row[0].ID;
callback(retid);
});
}
});
});
}
レコードの追加の場合の処理です。続けてサブマスタにレコードを追加する場合を考慮して、追加時のAutoincrementで自動で挿入されるIDの数値を取得して返すようにしています。
SQL文と追加するvaluesについては以下のようになります。
//SQL文 var query = "insert into employee (empid,uname,mail,company) values (?,?,?,?);" //Valuesの例 var values = [selerec.empid,selerec.uname,selerec.mail,selerec.company];
valuesは配列で渡すのですが、二次元配列の形で渡せば、バルクインサートが可能になっています(但し、一度に沢山のレコードをprepareで追加するとNGで、1回900レコード程度の制限があるみたい)。
但し、大量のレコードを普通にInsertで1行ずつ入れていくととてつもなく遅いです。
呼び出し側
呼び出し側は上記の関数を呼び出し、処理が終わったらcallbackしてもらうように組んでいます。retに追加したレコードのIDが返ってくるので、それを取得して引き続きサブマスタへの追加処理へとつなげます。
sqliteinsert(query,values,"employee",function (ret){
if(ret[0] == "NG"){
//ダイアログオプション
var options = {
type:'error',
title:"エラー",
button:['OK'],
message:'エラーが発生しました。',
detail:ret[1]
}
dialog.showMessageBoxSync(null,options);
event.sender.send("closeman");
return;
}
//終了処理
event.sender.send(retfunc);
return;
});
トランザクション処理
SQLiteにもトランザクション処理があり、特にInsert処理の場合は、1行ずつInsertしていくと、
- DBオープン
- DBへ書き込み
- DBへコミット
を何度も繰り返すことになり、非常に遅いです。そこで、トランザクション処理を行う事で一回のDBオープンとコミットだけにし、連続で書き込み処理を行わせる事で高速化出来ます(およそ25,000行のデータで1分程(17カラム))。
基本は
- db.run("begin transaction")でトランザクション開始
- async.eachSeriesのループ内で、db.runにて配列データを順次追加作業
- db.run("commit")でコミット
- エラーが発生すると自動でロールバック
となります。
バルクインサート
バルクインサートの基本
通常、1回のInsert処理で追加できるレコードは1行のみです。しかし、1回のInsert処理で複数行のレコードを一括で処理するのがバルクインサート。劇的に追加速度がアップします。SQL構文としては
といったように、values以降に、値を格納したものを、カンマ区切りで並べてつなげれば、バルクインサートになります。しかし、あまりにも多くの値をつなげると、too many sql variableというエラーが発生してしまいます(SQLiteの制限)。こちらのサイトに制限についての記載があります。v3.32以前のSQLiteだと999個、それ以降だと32766個がデフォルト設定のようです。これは、?の部分が999個が上限ということですね。
しかし、Node.jsでこれをやろうとするとValuesの部分を構築するのが面倒であるため、例えば100個ずつに区分けして、Insert Intoを実行するようにし、2次元配列は1次元配列に変換して渡すようにするというテクニックがstackoverflowで紹介されています。
//二次元配列のデータ
var array = [[a1,a2,a3,a4],[a5,a6,a7,a8],[a9,a10,a11,a12],[a13,14,15,16]]
//1レコード分のplaceholderを配列の数だけ用意
let placeholders = array.map(() => "(?, ?, ?, ?)").join(', ');
//placeholderを加えたクエリ文を構築する
let query = "INSERT INTO master (empid, empname, mail, age) VALUES " + placeholders;
//値を格納する1次元配列
let flatArray = [];
//2次元配列を1次元配列に変換する
array.forEach((arr) => { arr.forEach((item) => { flatArray.push(item) }) });
//DBにInsert処理を実行
db.serialize(function(){
db.run(query, flatArray, function(err){
if(err) throw err;
});
});
2次元配列を1次元配列にし、またレコードの数だけ必要なplaceholderを用意するという点が独特です。
100レコード単位でバルクインサート
SQLiteのInsert処理に於いて、db.runが非同期に実行されてしまうので、データの処理を考えて同期的に処理を実施しながら、100レコード単位でバルクインサートを実施してみた所、40,000行のデータでおよそ15秒程度で完了(17カラム)できました。これにはElectron側でこの全データをCheetah Gridで表示する所まで含めてこの値なので、当初のトランザクションも使わず、バルクインサートもせずにeachSeriesで1件ずつトロトロインサートしていた時よりも遥かに高速にInsert処理が出来ました。
//TSログインポート処理
ipcMain.on('tsimportdiag', function (event) {
//メッセージオプション
var options = {
properties: ['openFile'],
title: "ファイルの選択",
filters: [
{ name: 'TSログファイル', extensions: ['csv'] }
]
}
const filepath = dialog.showOpenDialogSync(null, options);
var items = "";
if (filepath == undefined) {
console.log("キャンセル")
event.sender.send('message', "処理はキャンセルされました。");
return;
} else {
items = filepath[0]
}
//CSVファイル読み込み
fs.createReadStream(items)
.pipe(csv.parse({ columns: true }, function (err, data) {
//JSONデータに変換する
var jsondata = JSON.stringify(data);
jsondata = JSON.parse(jsondata);
var length = jsondata.length;
//インポート用の配列
var array = [];
//jsondataを加工して配列を組み直す
for (var i = 0; i < length; i++) {
//データが空を検知したら終了
if (jsondata[i]["会社コード"] == "") {
continue;
}
//日付が空の場合は次のレコードへ
if (jsondata[i]["日付"] == "") {
continue;
}
//一時連想配列を用意
var temparr = [];
//データ追加する
temparr.push(jsondata[i]["会社コード"]);
temparr.push(jsondata[i]["社員コード"]);
temparr.push(jsondata[i]["社員名"]);
temparr.push(jsondata[i]["勤務体系: 勤務体系名"]);
temparr.push(paddingNull(jsondata[i]["日付"]));
temparr.push(paddingNull(jsondata[i]["日タイプ"]));
temparr.push(paddingNull(jsondata[i]["イベント"]));
temparr.push(paddingNull(jsondata[i]["イベントタイプ"]));
temparr.push(paddingNull(jsondata[i]["出社時刻・時"]));
temparr.push(paddingNull(jsondata[i]["退社時刻・時"]));
temparr.push(paddingNull(jsondata[i]["総労働時間"]));
temparr.push(paddingNull(jsondata[i]["深夜労働時間"]));
temparr.push(paddingNull(jsondata[i]["所定休憩時間"]));
temparr.push(paddingNull(jsondata[i]["所定労働時間"]));
temparr.push(paddingNull(jsondata[i]["実労働時間"]));
temparr.push(paddingNull(jsondata[i]["休暇ID1: 勤怠休暇名"]));
temparr.push(paddingNull(jsondata[i]["時間単位休暇ID1: 勤怠休暇名"]));
//配列にpushする
array.push(temparr);
}
//データの件数を検知
var dlength = array.length
if (dlength == 0) {
event.sender.send('message', "取り込めるデータの件数が0件でした");
return;
}
//100回単位で区切った場合のループ回数を計算(小数点以下切り上げ)
var loopman = Math.ceil(dlength / 100)
var query = "DELETE FROM tslog";
sqlitedelete(query, function (ret) {
if (ret == "NG") {
event.sender.send('message', "tslogテーブルのデータ削除に失敗しました。");
return;
} else {
//トランザクション処理開始
db.run("begin transaction")
//バルクインサート処理を開始
topgun(loopman, array).then(result => {
if (result == "OK") {
//コミット
db.run("commit");
//処理を完了
event.sender.send('tsimportend', 'TSログの取り込みが完了しました。');
} else {
event.sender.send('message', 'ログ読み取り時にエラーが発生しました。');
}
});
}
});
}));
});
//同期的にデータをバルクインサート(100レコード単位で)
async function topgun(loopman,array){
//baseとなるクエリ
var querybase = "INSERT INTO tslog (compid,empid,empname,kinmu,workdate,datetype,event,eventtype,starttime,endtime,totaltime,nighttime,resttime,syoteitime,worktime,restname,timerestname) VALUES ";
//バルクインサート処理
for(var i = 0;i<loopman;i++){
//一時配列を用意
var temparray;
//100件分取り出す
temparray = await array.splice(0,100)
//1レコード分のplaceholderを配列の数だけ用意
var placeholders = await temparray.map(() => "(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)").join(', ');
//placeholderを加えたクエリ文を構築する
var query = querybase + placeholders;
//値を格納する1次元配列
var flatArray = [];
new Promise((resolve, reject) => {
//2次元配列を1次元配列に変換する
temparray.forEach((arr) => {
arr.forEach((item) => {
flatArray.push(item)
})
});
resolve(flatArray);
}).then((ret) => {
db.run(query,ret);
}).catch(e => {
console.log('エラーを捕捉');
return "NG";
})
}
return "OK"
}
100件分を取り出すspliceの項目。一番最後のInsert時には100指定しての場合、実際の配列の数以上の値を指定してしまってることになりますが、取得されるtemparray変数にはきちんと残りの未処理の配列分だけ取り出せています。エラーも出ず残りの配列数を気にすることなく切り出せるので、非常に便利です。spliceはsplice(0,100)で、0番から100個目までの配列を取り出すことになり、arrayから除去されますので、次のターンでもsplice(0,100)で次の200個を取り出せます。
同期的にバルクインサート
前述の方法の場合、基本的には非同期でバンバンデータをインサートする為、インサートの完了を持って通知して次の処理へ進むには都合が悪いです。そこで1パートずつ確実にインサートしてから完了通知を送るような仕組みにするには、以下のような形で構築します。
//呼び出し元
topgun4(loopman,array,function(result){
if (result == "OK") {
//次の処理へ
event.sender.send('insertend');
return;
} else {
event.sender.send('message', "データの追加に失敗しました。");
return;
}
});
//メインの処理
//各社条件データベースをバルクインサート
async function topgun4(loopman, array, callback) {
//バルクインサート処理
let querybase = "INSERT INTO datatable (recid,patternid) VALUES ";
//loopmanにもとづきダミーの配列を用意
let dumarr = [];
for(var i = 0;i<loopman;i++){
dumarr.push(0);
}
//トランザクション処理開始
db.run("begin transaction");
//バルクインサート処理
async.eachSeries(dumarr, function (rec, next) {
//一時配列を用意
var temparray;
//100件分取り出す
temparray = array.splice(0, 100);
//1レコード分のplaceholderを配列の数だけ用意
var placeholders = temparray.map(() => "(?,?)").join(', ');
//placeholderを加えたクエリ文を構築する
var query = querybase + placeholders;
new Promise((resolve, reject) => {
//2次元配列を1次元配列に変換する
const arr2 = temparray.reduce(function (acc, cur) {
return [...acc, ...cur];
});
resolve(arr2);
}).then((ret) => {
db.run(query, ret);
next();
}).catch(e => {
callback("NG");
})
}, function (err) {
//エラートラップ
if (err) {
callback("NG");
return;
}
//処理を返
db.run("commit");
callback("OK");
});
}
- async.eachSeriesを持って同期的に処理をします。そのループ回数の為にダミーの配列を生成させて回しています。
- 2次元配列を1次元配列にする為には、今回はreduceを利用して変換しています。
- insertが完了したら、next()で次のパートをinsertします
- 全てが完了したら、commitして、callbackでOKを返します。まだinsert中の状態で返さないので、次の処理でDBへ続けてinsertするようなケースで「cannot start a transaction within a transaction」といったようなエラーが出ずにすみます。
UPDATE
SQL実行関数
//SQLiteへのSQL発行
function sqliteupdate(query,values,callback){
db.serialize(() => {
db.run(query, values,function(err) {
if (err){
return;
}else{
callback("OK");
}
});
});
}
レコードの更新処理の時の関数です。基本は更新が成功したかどうかだけを呼び出し元へと返します。SQL文とvaluesについては以下のようになります。
//UPDATE構文 var query = "update employee set empid=? retireflg=? where ID=3" //Values var values = [selerec.empid,selerec.retireflg];
Valuesについては、Insert処理同様にバルクインサート処理を行えば高速アップデートを実行可能です。
呼び出し側
呼び出し側は処理が完了したらOKだけを返すようにしています。エラー時にはダイアログ表示をして処理を終了します。
sqliteupdate(query,values,function (ret){
//終了処理
event.sender.send(retfunc);
return;
});
他のテーブルとJOINしてUPDATE
MySQLやAccessなどでは普通にできることなのですが、2つ以上のテーブルをJOINしてその値を元にUPDATEするということが、SQLiteの場合実行することができません。例えば以下のようなSQL文は実行が出来ないのです(Version 3.33より前のバージョン)。結構使うテクニックなので、このままだと非常に困ります。
▼以下の例はtslogのeventの値をtslog.workdate<->holiday_public.hdate2で連結して、holiday_publicのhnameで更新するクエリ
UPDATE tslog INNER JOIN holiday_public ON tslog.workdate = holiday_public.hdate2 SET tslog.event = holiday_public.hname;
上記の事例だと、1つの列の値を更新するだけで、複数の列を更新したい場合困ります。その場合は以下のような記述が可能です。
UPDATE tslog
SET
(tslog.event, tslog.eventflg) = (SELECT holiday_public.hname, holiday_pulic.hflg
FROM holiday_public
WHERE holiday_public.hdate2 = tslog.workdate )
WHERE
EXISTS (
SELECT *
FROM holiday_public
WHERE holiday_public.hdate2 = tslog.workdate
)
()で括って、カンマ区切りで列名を列挙し、SELECT文の側でも同様に列を列挙することで、指定の複数の列のアップデートをテーブル結合で実現出来ます。また、SQLite Version 3.33以降は、UPDATE FROMが使えるようになり、より簡単に記述が可能になり、以下のような書き方でもアップデートが可能です。
UPDATE tslog SET event = daily.event ,eventflg= daily.eventflg FROM daily WHERE daily.ID = tslog.dailyid; もしくは UPDATE testman SET (dailyname, restflg) = (daily.dailyname, daily.restflg) FROM daily WHERE daily.ID = testman.dailyid;
DELETE
SQL実行関数
//SQLiteへのSQL発行(Delete)
function sqlitedelete(query,callback){
db.serialize(() => {
db.run(query, function(err) {
if (err){
//メッセージを表示
//メッセージオプション
var options ={
type:'info',
title:"エラーメッセージ",
button:['OK'],
message:'データ取得エラー',
detail:String(err)
}
//表示する
dialog.showMessageBoxSync(null,options);
return;
}else{
callback("OK");
}
});
});
}
更新時処理と殆ど同じなので、UPDATEとDELETEは一個の関数としても良いのですが、UPDATEの場合は今回は利用していませんが、Bulk Updateの処理も存在し得るので、Transaction処理を考慮して、別に分けています。SQL文としては以下のようになります。
//DELETE構文 var query = "DELETE FROM employee where ID=3"
呼び出し側
基本的にはUPDATE文の時の関数処理と同じ。
sqlitedelete(query,function (ret){
//終了処理
event.sender.send("delmemresult");
return;
});
テーブルを新規作成する
アプリのアプデ時に過去の版にSQLiteのファイルを上書きするようなことをしてしまうとデータが消えてしまいます。そこで、既存のDBに対してテーブルの有無チェック(後述)を行い、なかった場合には新規にテーブルを作ってあげないとアプリの運用ができなくなります。といったようなシーンや膨大なデータを新規のテーブルに切り出して分割するようなシーンでも使うのが「テーブルの新規作成」。作成時にはテーブル名、列の名前、データ型の指定が必要になります(デフォルト値のセットも出来ます)
//busyoテーブルの作成
var query = "CREATE TABLE 'テーブル名' ('ID' INTEGER, 'compid' INTEGER, 'busyo' TEXT, PRIMARY KEY('ID' AUTOINCREMENT))"
//作成の実行
db.serialize(() => {
console.log("テーブルを作成");
db.run(query);
});
- Create Table文を使って新規に作成します。
- '列名' 型 といった形でカンマ区切りで列を指定してゆきます。
- ID列等の場合は、Primary keyの指定が必要且つ、Autoincrementの指定をするのが定石です。
- db.runでクエリ文を実行するとテーブルが作成されて保存されます。
列を新規に追加する
テーブルの新規追加の他にも過去のアプリとの互換性の為などを主な目的として新規に列を追加するケースがあります。列の追加だけでなく削除や型の変更など様々なテーブル構造の変更を行う場合に使うのが「Alter文」です。但し、SQLiteの場合は以下のような制限があります。
- 列の追加などは一度に複数の列を追加できず、1列ずつ追加する事になる
- alter table ~ modify ~といった感じで、カラム構成の変更は出来ない。
- Primary Keyの列は変更出来ないし、新規に追加も出来ない
- unique指定も出来ません
- 追加時にデフォルト値をセットする事が出来るけれど、関数などの指定などは出来ない
などなど。結構制約が多いので多用することはないと思います。この当たりの制約をまとめたページがこちらにあります。既存のテーブルに同名の列チェックを行った後に(後述)、列を追加するSQL文を実行します。
//busyoおよびcompid列を追加
db.serialize(() => {
//busyo列を追加
var mkcol = "ALTER TABLE ngemployee ADD COLUMN busyo TEXT";
db.run(mkcol);
//compid列を追加
mkcol = "ALTER TABLE ngemployee ADD COLUMN compid INTEGER";
db.run(mkcol)
});
- 2つ以上の列追加は、一列ずつ追加していく事になります。
- Alter Table ~ Add Column ~句を使って、列名と型を最低でも指定して実行します。
特定の列の存在有無チェック
アプリのバージョンアップを重ねていく内に、SQLiteのテーブル構造も変更するシーンが出てきます。そうなると、過去のアプリとデータベースの互換性が失われてしまうことがあります。それが「特定の列の有無」。後のバージョンで列を追加したのであれば、アプデ時にデータベースも上書きすれば問題無いですがデータも消えます。ということで、列の有無をチェックしてさらに「列を追加する」処理を装備すれば、データベースを上書きせずに、DB側を弄る事でユーザのアプデ上の障害を取り除けます。
//対象のテーブルの情報を取得する
var query = "pragma table_info('テーブル名')";
//SQLを実行する
db.all(query, function (err, rows) {
if (err) {
console.log(err);
}else{
//テーブルの列を一個ずつ走査する
async.eachSeries(rows, function (rec, next) {
//busyoが含まれているかチェック
var colname = rec.name;
if (colname == "対象の列の名前") {
console.log("列あったよ")
noflg = true;
}
//次の列名
next();
}, function (err) {
//エラートラップ
if (err) {
//メッセージを返して処理を中断
console.log(err);
return;
}
//列がなかった場合の処理
if (noflg == false) {
}
});
}
});
- テーブル情報を取得するためのSQLは、pragma table_infoという変わったSQLを利用します。これで列情報が連想配列で返ってきます。
- ループで一個ずつ列をチェックして、対象の列の名前と一致するものがあったら、フラグを立てます
- フラグが建ってる場合は列が存在するので、処理をせず、ない場合には例えば列追加の処理を追記します。
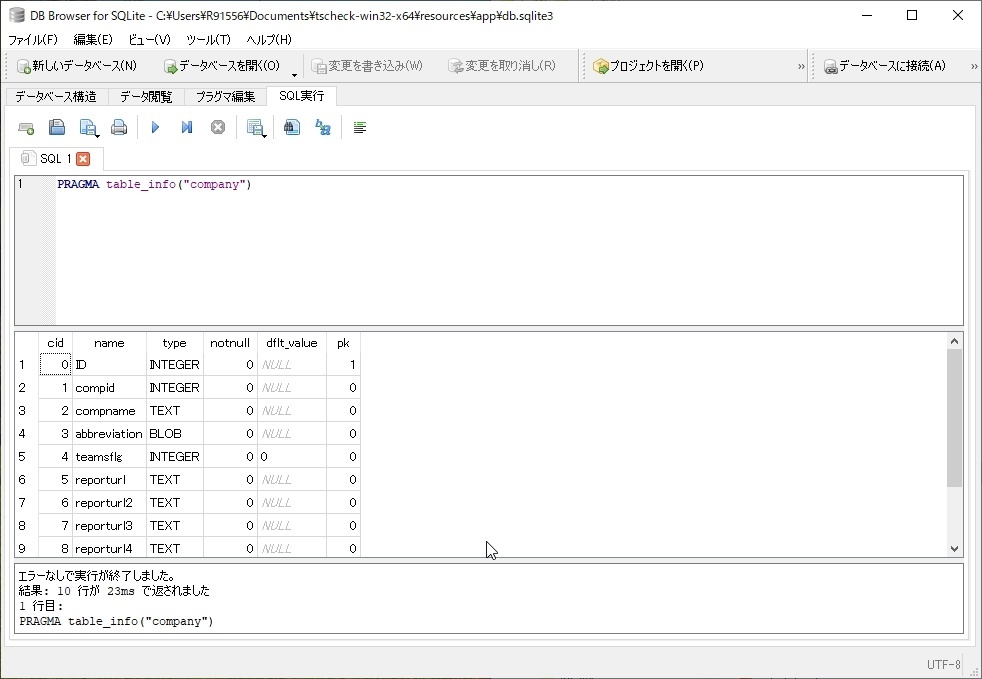
図:列の名前や型がわかる
対象のテーブルの存在有無チェック
Node.jsなどのプログラムで、他のSQLite3のデータベースをインポートして入れ替えるといった仕組みの場合、バージョンを重ねるごとに、古いバックアップのdb.sqlite3ファイルには存在しないテーブルというものが出来ていくこともあるでしょう。しかし、当然のように普通にインポート処理をコードで記述してしまうと、存在しないテーブルに接続してデータを取り込もうとしてエラーが発生する事になります。
そこで、対象のSQLite3ファイルに「対象となるテーブルが存在しているかどうか?」をチェックするSQL文を発行して、存在しなければ処理をスルーするような仕組みが必要になります。この場合、以下のようなSQL文を構築し、存在すれば1、存在しなければ0が返ってくるので、それを元に処理を分岐させる事が可能です。
//対象のテーブルが存在するかチェックする
function sqliteexist(rec){
//SQL文を構築
var query = "SELECT COUNT(*) FROM sqlite_master where type='table' AND name='" + rec + "';";
//SQL実行
dbback.get(query,function(err,res){
if (err){
//ダイアログオプション
var options = {
type:'error',
title:"エラー",
button:['OK'],
message:'エラーが発生しました。',
detail:String(err)
}
dialog.showMessageBoxSync(mainWindow,options);
return;
}else{
//取得したデータを変数に格納しておく
var countman = res["COUNT(*)"];
console.log(countman);
return countman;
}
});
}
- SELECT文ではCOUNT関数を使ってレコード数を返すようにしています。
- 検索対象は表向き見えない管理用テーブルであるsqlite_masterテーブルに対してクエリを発行しています。
- WHERE条件は、typeで「table」を指定してテーブルのみとし、「name」にてテーブル名を指定します(recにはテーブル名を入れておく)
- 該当するテーブル名のtypeがtableのデータがあれば、1が返ります。なければ0が返ります。
- dbbackはインポートするDBに対して接続しているインスタンスです。それに対して、db.getにてクエリを発行します。
- resには[{'COUNT(*)':1}]といった値が返ってくるので、countman変数ではその値のみを取り出しています。
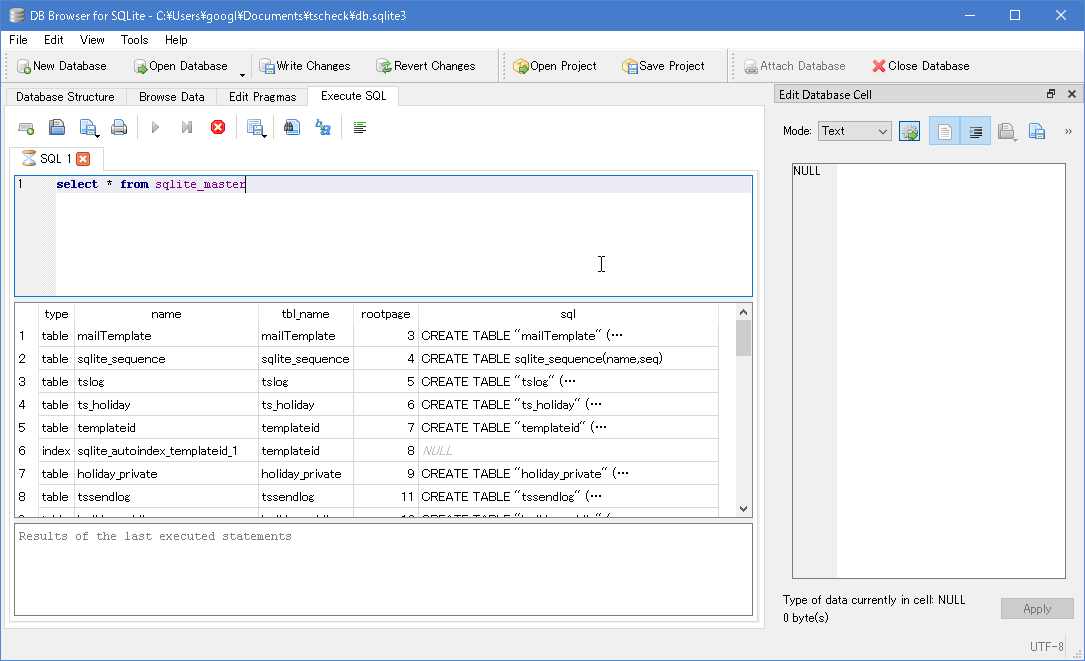
図:管理用テーブルを参照するテクニックです。
AccessからODBC接続
SQLiteは大変便利なんだけれど、テーブルにデータを流し込むであったり、Accessの2GBの制限を超えるためにもSQLiteは役に立ちます。但し、データを流し込むには、DB Browser for SQLiteはちょっと使いにくく、データのコピペでイケるAccess + SQLite ODBC Driverの組み合わせが、Windowsで扱うには便利です。
以下の手順で、AccessからSQLiteに接続しデータを扱う事が可能です。
- SQLite ODBC Driverをダウンロードしてインストールしておく(64bitだとsqliteodbc_w64.exeがそれになる)
- Windowsの検索窓から、ODBCデータソースアドミニストレータを開く(今回は64bit版)
- ユーザDSNが開かれてる状態なので、追加をクリック
- SQLite3 ODBC Driverを選択
- Data Sorce Nameは適当に付ける。Database NameはBrowseをクリックして、接続するdb.sqlite3ファイルを指定する
- OKをクリックする
- Accessを起動する
- 外部データ -> 新しいデータソース -> 他のソース -> ODBCデータベースを開く
- リンクテーブルを作成して、ソースデータにリンクするにチェックを入れてOKをクリック
- コンピュータデータソースをクリックし、5.で作ったデータ設定を選んでOKをクリック
- データベース一覧が出てくるので、リンクするものをクリックして選ぶ
- リンクテーブルが貼られるので、後は好きなように操作する
Accessでクエリを作り、そのSQL文はそのままDB Browser for SQLiteでも使えたりするので、Viewを作ったりする時にもAccessのUIは役に立ちます。
また、コピペでデータを流し込める上に、SQLiteの場合はaccdbファイルのような2GBの制限が無いので、大量のデータでこの制限に引っかかってるケースでも有効な手段になります。
VBAで手動で接続する場合には、以下のような接続文字列を作る事で接続が可能です(ActiveX Data Object 6.1 Library等を参照設定で指定しておく必要があります)
Public Function testdb() '接続文字列 Dim strconn As New ADODB.Connection strconn.Open "DRIVER=SQLite3 ODBC Driver;Database=db.sqlite3" strconn.Close Set strconn = Nothing End Function
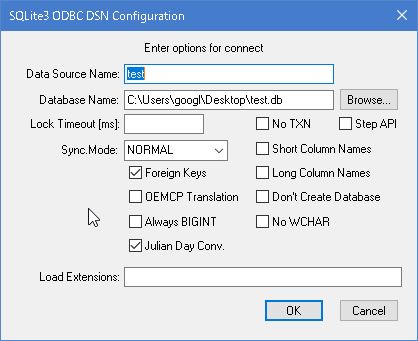
図:セットアップは至ってシンプル
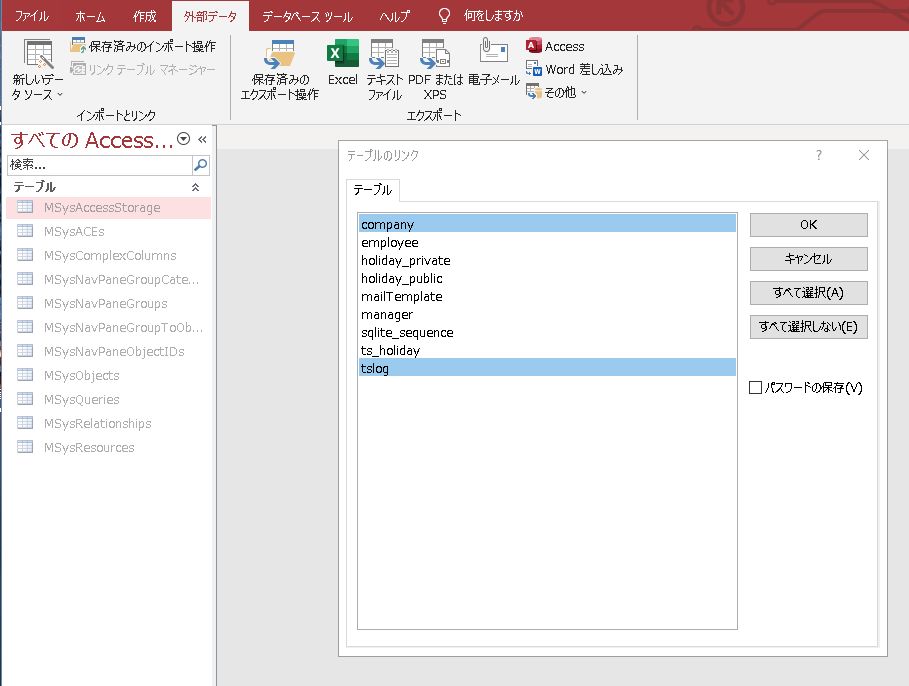
図:リンクするテーブルを選ぶ
