Google Apps ScriptでXMLをよしなに扱う方法【GAS】
最近のウェブサービスは、扱うフォーマットはJSONが基本になってきています。XMLしか出力することのできない旧式のウェブサービスはだいぶ滅び、ごく一部になりつつあります。しかし、XMLフォーマットが滅びたわけではないので、何かとXMLを捌くシーンがあります。
しかし、XMLはJSONとは異なり、単純に値を拾う事が難しいです。そのため、JSONで慣れきってると、とてつもなく面倒で嫌になってしまいます。ということで、この面倒なXMLをGoogle Apps Scriptで扱う際のまとめを残しておこうと思います(自分も毎回、処理方法を忘れ、その度に時間を失うので、メモがないと・・・)
目次
今回使用するスプレッドシート
ソースコード
XML Serviceを使って頑張って処理する
Google Apps ScriptにはXML ServiceというXMLを処理する為のクラスが用意されています。ですので、自力でこのクラスを使ってXMLを捌くことは可能です。ただ鬼門なのは普通のXMLタグならば特に問題なくこれで取得できるのですが、コロン(:)が含まれているようなタグについては、名前空間を指定しての処理が必要になります。
書籍検索ですでに処理については記述しています。
//検索用URL
var sURL = "http://iss.ndl.go.jp/api/opensearch?isbn=9784065142950";
//ブック検索メインルーチン
function booksearch(){
//まずは国会図書館APIの検索URIを組み立てる(キーワードはURLエンコードする)
var array = [];
//検索結果を取得する
var response = UrlFetchApp.fetch(sURL);
//XMLを取得する
var xmldocs = XmlService.parse(response.getContentText());
//itemノードを取得する
var items = xmldocs.getRootElement().getChildren('channel')[0].getChildren('item');
var length = items.length;
//namespaceを取得する
var namespaceDc = XmlService.getNamespace("dc", "http://purl.org/dc/elements/1.1/");
var namespaceDcndl = XmlService.getNamespace("dcndl", "http://ndl.go.jp/dcndl/terms/");
var namespacexsi = XmlService.getNamespace("xsi", "http://www.w3.org/2001/XMLSchema-instance");
//ループでタイトルを取得
for(var i = 0;i<length;i++){
//変数を初期化
var isbn = "";
var tempArray = [];
//dc:identifierを取得
var prop = items[i].getChildren('identifier', namespaceDc);
//dc:identifier内をループでトレース
for(var j = 0; j < prop.length; j++){
//1つ目のidentifierの属性値を取得
var property = prop[j];
//xsi:typeの値を取得
var name = property.getAttribute("type",namespacexsi).getValue();
//xsi:typeの値がISBNならば配列にISBN値としてpush
if(name == "dcndl:ISBN"){
var isbn = items[i].getChildText("identifier", namespaceDc);
tempArray.push(isbn);
break;
}
}
//isbn値が空の場合には、空値をpush
if(isbn == ""){
tempArray.push("");
}
//書籍のタイトル
var bookTitle = items[i].getChildText("title", namespaceDc);
tempArray.push(bookTitle)
//著者名
var author = items[i].getChildText("author");
tempArray.push(author);
//出版社名
var pubname = items[i].getChildText("publisher", namespaceDc);
if(pubname == null){
tempArray.push("");
}else{
tempArray.push(pubname);
}
//画像はないので、値を空のままpush
tempArray.push("");
//発売日
var pubday = items[i].getChildText("pubDate");
tempArray.push(pubday);
//値段
var price = items[i].getChildText("price", namespaceDcndl);
if(price == null){
tempArray.push("");
}else{
tempArray.push(price);
}
//書き込み用配列にpushする
array.push(tempArray);
}
//生成した配列を返す
Logger.log(JSON.stringify(array));
return JSON.stringify(array);
}
- namespaceを取得する部分(getNamespace)がポイントで、ここでこの処理をしておかないと、コロン(:)で指定されてるタグ内の項目を取得することが出来ません。
- itemノードのような単純なものでも、getChildrenやらgetAttributeやら・・・ここが最も面倒なポイントです。
- getChildTextにしてタグ内の項目データを抜き出します。
いくらクラスがあるとはいえ、面倒な点は何も解消していないので、正直結構コードを書いていて面倒だなぁと思います。特に冒頭のnamespaceのURLを指定してきちんと定義する部分が・・・
この処理の結果は以下の配列で取得がされます。
[["9784065142950","夜廻り猫の展覧会","深谷かほる 著,深谷, かほる, 1962-,","講談社","","Fri, 14 Dec 2018 09:00:00 +0900","1350円"]]
JSONに変換して処理をする
Node.jsの場合、xml2jsonというとても便利なライブラリのおかげで、XMLを簡単にJSON化して処理をする事が可能です。しかし、Google Apps Scriptでは使えません。GithubにはJSONに変換して扱うコードが結構見かけます。JavaScriptサイドで変換するようなこんなコードもありますね。
今回はあくまでもGASサイドなので、こちらのGithubに公開されてる変換コードを使ってみたいと思います。公開されてる関数コードは以下のような感じです。
//XML2JSONで処理をする
function xmlconvert(){
//検索結果を取得する
var response = UrlFetchApp.fetch(sURL);
//JSONデータに変換する
var jsondoc = xmlToJson(response);
//結果を出力する
Logger.log(jsondoc);
}
//XMLをJSONに変換するとき利用する関数
function xmlToJson(xml) {
//XMLをパースして変換関数に引き渡し結果を取得する
var doc = XmlService.parse(xml);
var result = {};
var root = doc.getRootElement();
result[root.getName()] = elementToJson(root);
return result;
}
//変換するメインルーチン
function elementToJson(element) {
//結果を格納する箱を用意
var result = {};
// Attributesを取得する
element.getAttributes().forEach(function(attribute) {
result[attribute.getName()] = attribute.getValue();
});
//Child Elementを取得する
element.getChildren().forEach(function(child) {
//キーを取得する
var key = child.getName();
//再帰的にもう一度この関数を実行して判定
var value = elementToJson(child);
//XMLをJSONに変換する
if (result[key]) {
if (!(result[key] instanceof Array)) {
result[key] = [result[key]];
}
result[key].push(value);
} else {
result[key] = value;
}
});
//タグ内のテキストデータを取得する
if (element.getText()) {
result['Text'] = element.getText();
}
return result;
}
XMLをJSONに変換してログ出力をしてみました。
{rss=
{channel=
{
totalResults={Text=1},
startIndex={Text=1},
item=
{extent=
{Text=93p ; 21cm},
identifier=[Ljava.lang.Object;@229d39f3,
creator={Text=深谷, かほる, 1962-},
author={Text=深谷かほる 著,深谷, かほる, 1962-,},
subject=
[Ljava.lang.Object;@39eccba9,
link={Text=http://iss.ndl.go.jp/books/R100000002-I029336647-00},
description=[Ljava.lang.Object;@d2eb6f8,
Text=,
title=
[Ljava.lang.Object;@301c81ff,
pubDate={Text=Fri, 14 Dec 2018 09:00:00 +0900},
seriesTitleTranscription={Text=ワイド ケーシー},
seeAlso={resource=http://id.ndl.go.jp/bib/029336647},
seriesTitle={Text=ワイドKC},
creatorTranscription={Text=フカヤ, カオル},
price={Text=1350円},
guid=
{isPermaLink=true,
Text=http://iss.ndl.go.jp/books/R100000002-I029336647-00},
publisher={Text=講談社},
category={Text=本},
titleTranscription={Text=ヨマワリネコ ノ テンランカイ},
issued={Text=2018, type=dcterms:W3CDTF}},
itemsPerPage={},
link={Text=http://iss.ndl.go.jp/api/opensearch?isbn=9784065142950},
description={Text=Search results for isbn=9784065142950 },
language={Text=ja},
Text=
ログが途中で切れていましたが、こんな具合に取ることが可能です。これならば、JSONのデータの取得法で簡単にテキストデータを取れますね。Node.jsのxml2jsonのほうがより簡単でしたが。
importxml関数で手っ取り早く処理
GASで色々やるよりも手っ取り早くXMLを処理することの出来る機能が、Googleスプレッドシートには備わっています。それが「importxml関数」。以下の数式を組んで貼り付けるだけで、実はXMLの構造解析と各種データが取得可能です。
//importxmlでパースする
=importxml("http://iss.ndl.go.jp/api/opensearch?isbn=9784065142950","//item")
2個目の引数ではitemエレメント以下を取得するようにしています。より個別のエレメントを指定すればその値だけが取れる仕組みです。GASで扱うならば、関数で処理させた結果を取得するほうが手っ取り早い上にコードも最小で済みます。ライブラリ等も必要ありません。
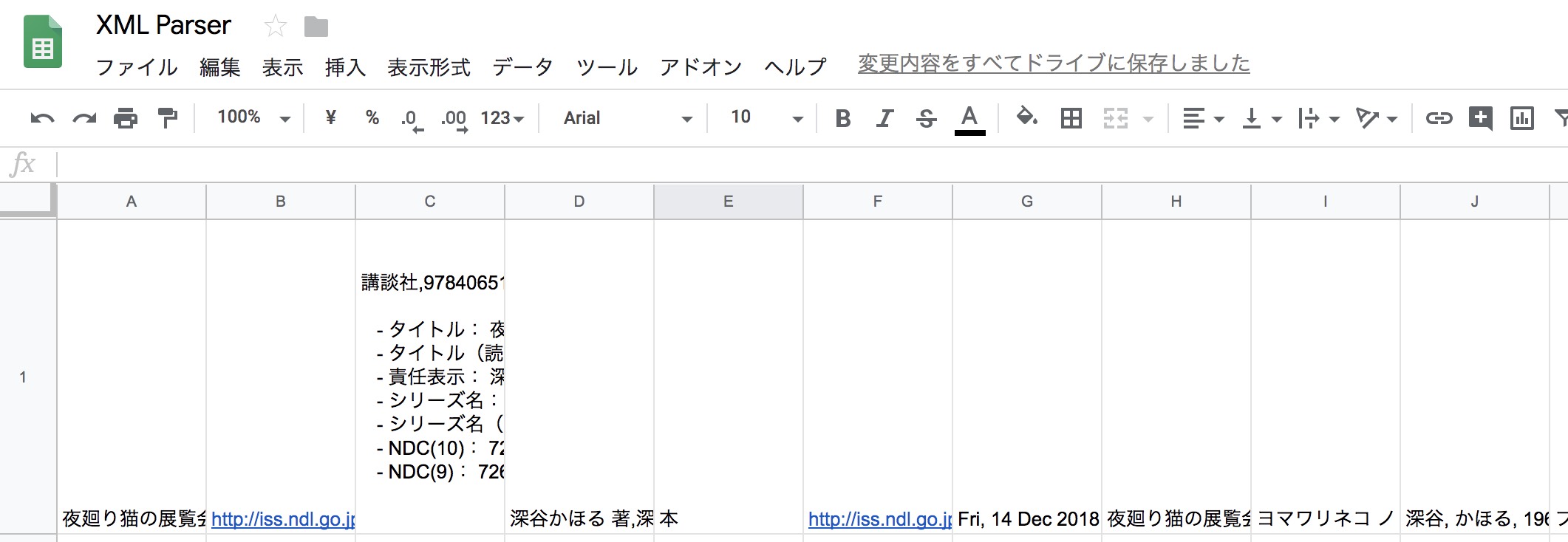
図:下手に考えるより手軽に取れちゃう・・・
関連リンク
- スプレッドシートでXML情報を取得して表形式に出力する方法(前編)
- XML Service - Google Developers
- Using Apps Script for xml json conversion
- Convert XML to JSON with Apps Script
- Spencer-Easton/XMLtoJSON
- Easy data scraping with Google Apps Script in 5 minutes
- [GAS]HTML/XMLをパースする
- Convert XML to JSON with JavaScript
- Google Apps ScriptでHTML・XMLのスクレイピングをするライブラリを公開してみた
- jupegarnica/xml2json.gs
- XMLを駆逐する
- ElectronでNFCを使った書籍貸出管理を作ってみる – 書籍検索編
- Google Apps ScriptでRSSリーダーを作る
- Google Apps ScriptでWebAPIや外部サイトを取得する指南書
- Google Apps Scriptで書籍検索を実装してみる
- SpreadSheetでスクレイピング。Importxml他、便利な関数9+1