Power Queryで2つのExcelシートの差分を取り出してみる
以前、2つのExcelシートの中身を比較して、差分を抽出するツールを作成し、現場で現在も利用してもらっていますが、今回はPower Queryにて2つのシートの差分を取り出して、差異のあった項目だけをリスト化し出力するものを作成しました。
前回のものとは少し事なり、集計表形式ではなくリスト化し、主に別のプログラムで利用しやすくする為に作成したものになりますが、該当箇所だけを取り出すことが可能ですので、使いようによっては現場の事務でも利用可能ではないかと思います。
目次
今回使用するファイル等
- 差分抽出サンプル Power Query版 - Excelワークブック
- 差分抽出サンプル2 - レコード数不一致版
2つのデータ部分と、差分抽出結果を出力するシートの3シートで構成されています。
事前準備
Power Queryで差分チェックをする為には、差分チェック2つのシートに対して以下のような事前準備が必要になります。
- 2つのシートの構成は全く同じ仕様にする必要があります(列名なども一致させておく必要があります)
- 2つのシートのデータ群は必ずテーブル化しておく必要があります。
- データはマスタデータである必要があります(重複するIDが1つのシート内に存在していてはなりません)故に、勤怠のような1人で複数の記録があるようなものには利用できません。
日付や文字列、数値等色々なデータが混在すると思いますが、Power Queryで比較する場合後で全てを文字列型に変換してから作業を行います。また、通常はデータが無い場合(null値)、ピボット解除した際にデータなってしまうので、0で埋めておくのですが、こちらについてもnullを後0に置換しますので、手動で0埋めする必要はありません。
クエリを作成する
2つのシートをテーブル化する
mainとhikakuの2シート・テーブルがあり、それぞれにいくつかの作業を行い、クエリにしておきます。ここでは
- 型の変更
- 値の置換
- ピボット解除
- インデックス列の追加
という作業を行います。以下の手順で2つのテーブルをクエリとして作成しておきます。シートへの出力は不要です。
- テーブルをクリックし、データタブ⇒テーブルまたは範囲からをクリック
- Power Queryが起動する
- 名前をmain_query等に変更する
- サンプルの社員番号と氏名以外の列を選択し、右クリック⇒型の変更⇒テキストに変更する。ダイアログが出たら、現在のものを置換をクリックする(次項のnullを0に置換する際に日付型があると置換ができないので、この手順を追加してあります)
- 変換タブをクリックし、値の置換をクリック
- 検索する値はnullとし、置換後を0として、OKをクリックする(ピボット解除時にnullだと値なしで非表示になってしまう為)
- 続けて列のピボット解除をクリック
- 続けて列の追加タブをクリックし、インデックス列の▼クリックして、「1から」をクリック
- インデックス列を左端に移動する
- ファイルタブをクリックして、保存して読み込むをクリック
- 新しいシートに書き出されてしまいますが、シートは削除してしまって結構です。
- 2つ目のテーブルもhikaku_queryとして同じ手順でクエリ化しておきます。
テーブルの行を勝手に入れ替える人が居たりするので、その場合比較する行が狂ってしまう為、社員番号等の列でソートしておくのがオススメです。また、テーブルの場合、シート上でフィルタをしていてもきちんとデータはクエリで取得出来るので、ここは気にする必要がありません。
さらに特定列の値でフィルタを実施したもの(例えば、終了済みというレコードは非表示にしたい)ケースの場合、シート上のデータで終了済みになってるデータが無い場合、オカシナ事になってしまうので、カスタム列で終了済みならば-1、そうでなければ0という判定列を設けて、0でフィルタを掛けるというテクニックが有効です。
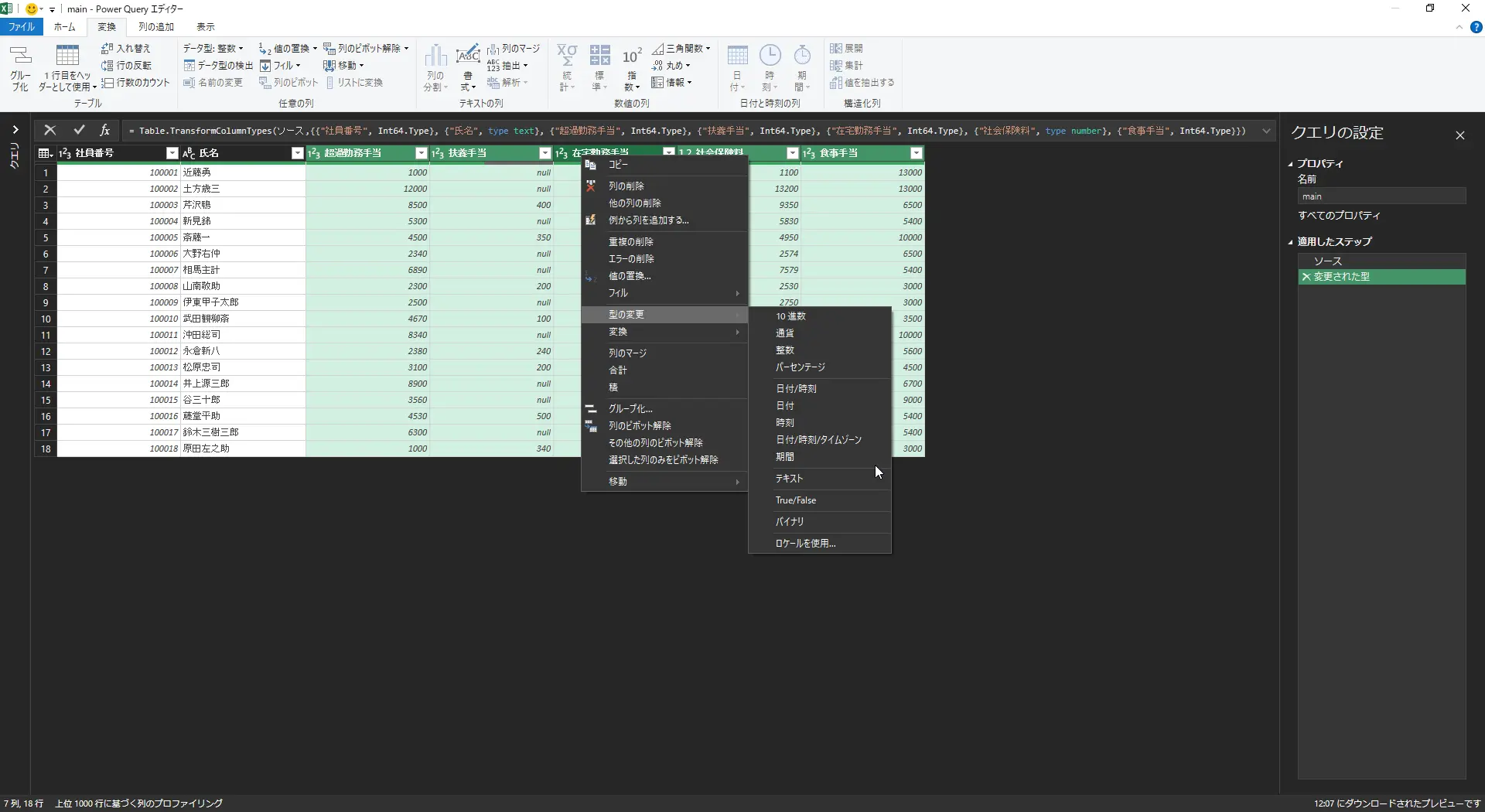
図:型変換で主要データを文字列に変えておく
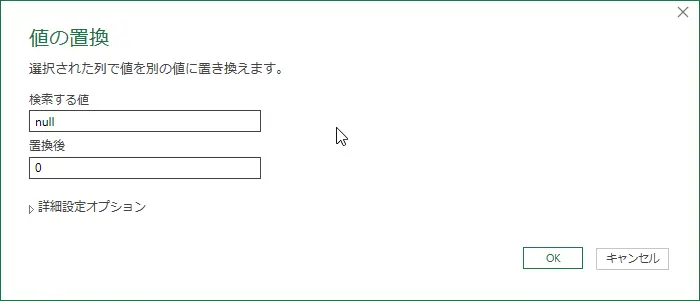
図:値の置換でnullを0に変えておく
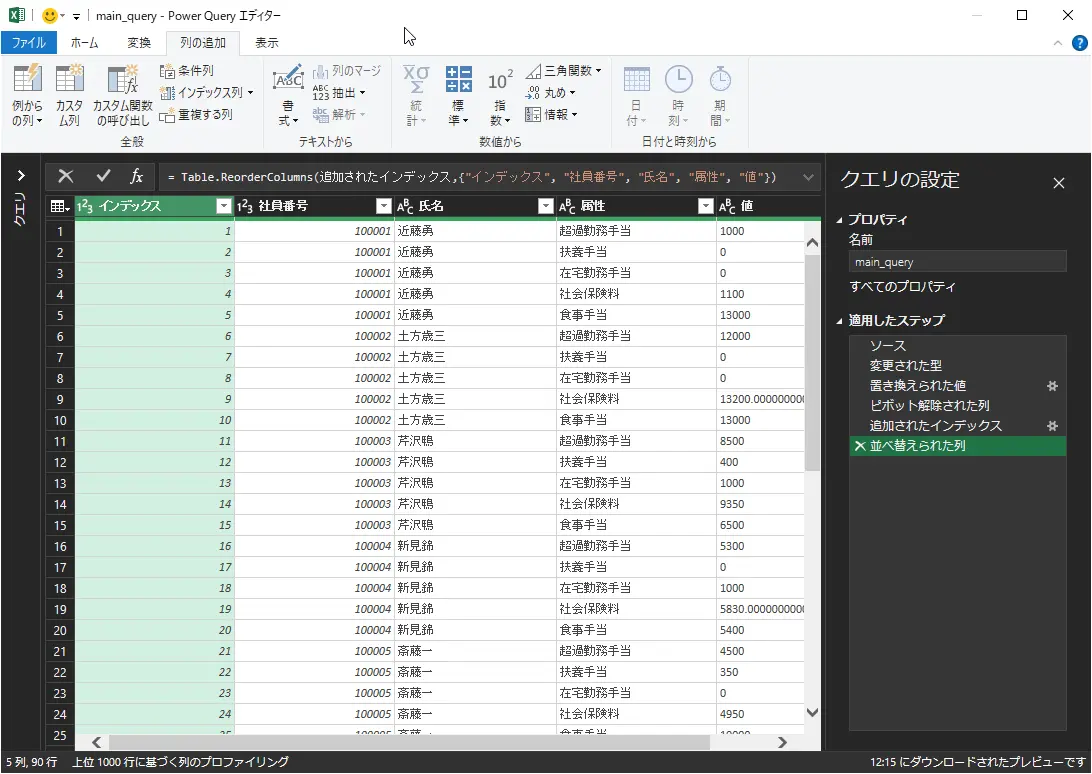
図:比較用の完成形クエリ
不一致検出のクエリを作成する
前項で、mainとhikakuそれぞれに加工を施して、比較用のデータの準備が出来ました。ここから2つのクエリの不一致項目だけを取り出す為のクエリを新規に作ります。クエリと接続から適当なクエリをダブルクリックして、Power Queryを起動します。
- 左サイドバーのクエリをクリックして開き、そこで右クリック⇒新しいクエリ⇒結合⇒新規としてクエリをマージを選択
- マージのダイアログが出るので、1つ目にmain_queryを選択し、インデックス列を選択
- 同じく2つ目にhikaku_queryを選択し、インデックス列を選択
- 結合の種類は通常は左外部でOK。両方のテーブルに共通してあるレコードのみにしたい場合は、内部を選択する
- OKをクリックすると2つのテーブルがインデックス列で結合される
- 結合されたテーブルの右端、hikaku_queryの列のボタンをクリックし、「値」のみにチェックを入れてほかはチェックをハズする
- 結合されたら、名前を付ける(今回はsabuncheckとした)
- 値列とhikaku_query.値では見ずらいので、列の名前を変えておく。列をクリック⇒名前の変更で可能です(今回はメインと比較と命名した)
- 列の追加タブをクリックし、カスタム列をクリック
- カスタム列ダイアログにて、新しい列名は「不一致検知」とし、カスタム列の式として以下のように指定し、OKをクリックする
if [メイン] = [比較] then 0 else -1
メインと比較の値が一致してたら0を返し、不一致の場合は-1を返すようにしました。
- 不一致検知の列の▼をクリックして、-1だけにチェックを入れてOKをクリック(これで、不一致の項目だけが抽出されます)
- ファイルタブの閉じて次に読み込むをクリックする
- 既存のワークシートを選び、今回はsabunシートのA1を出力先に指定しました
- OKをクリックすると出力される
以降は、mainとhikakuのデータを入れ替えて、sabunのテーブルを右クリック⇒更新するだけで一連の作業が実行されて、差分が自動で抽出されるようになります。RPAなどを使わずとも、このようにExcel業務は自動化が可能になります。
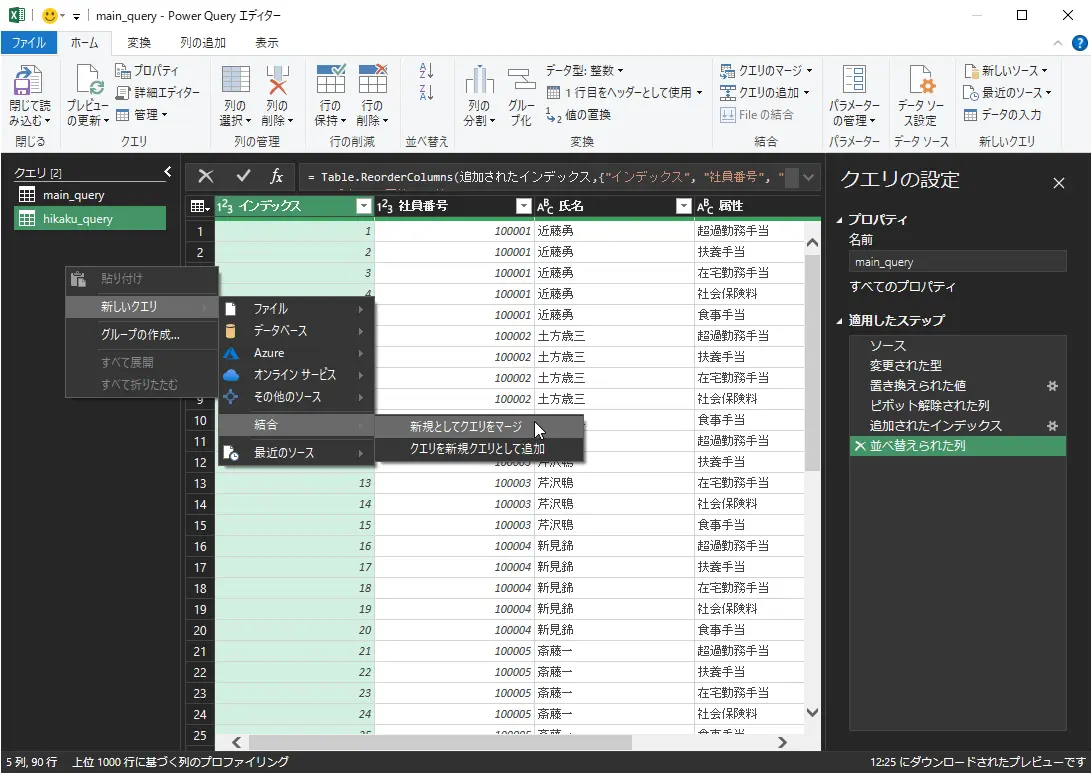
図:2つのクエリをインデックス列を元に結合
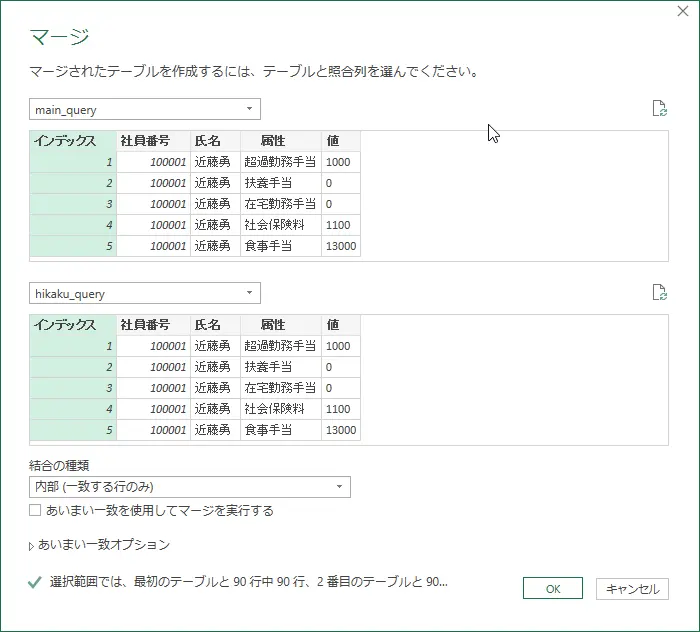
図:2つのクエリを1枚に結合する
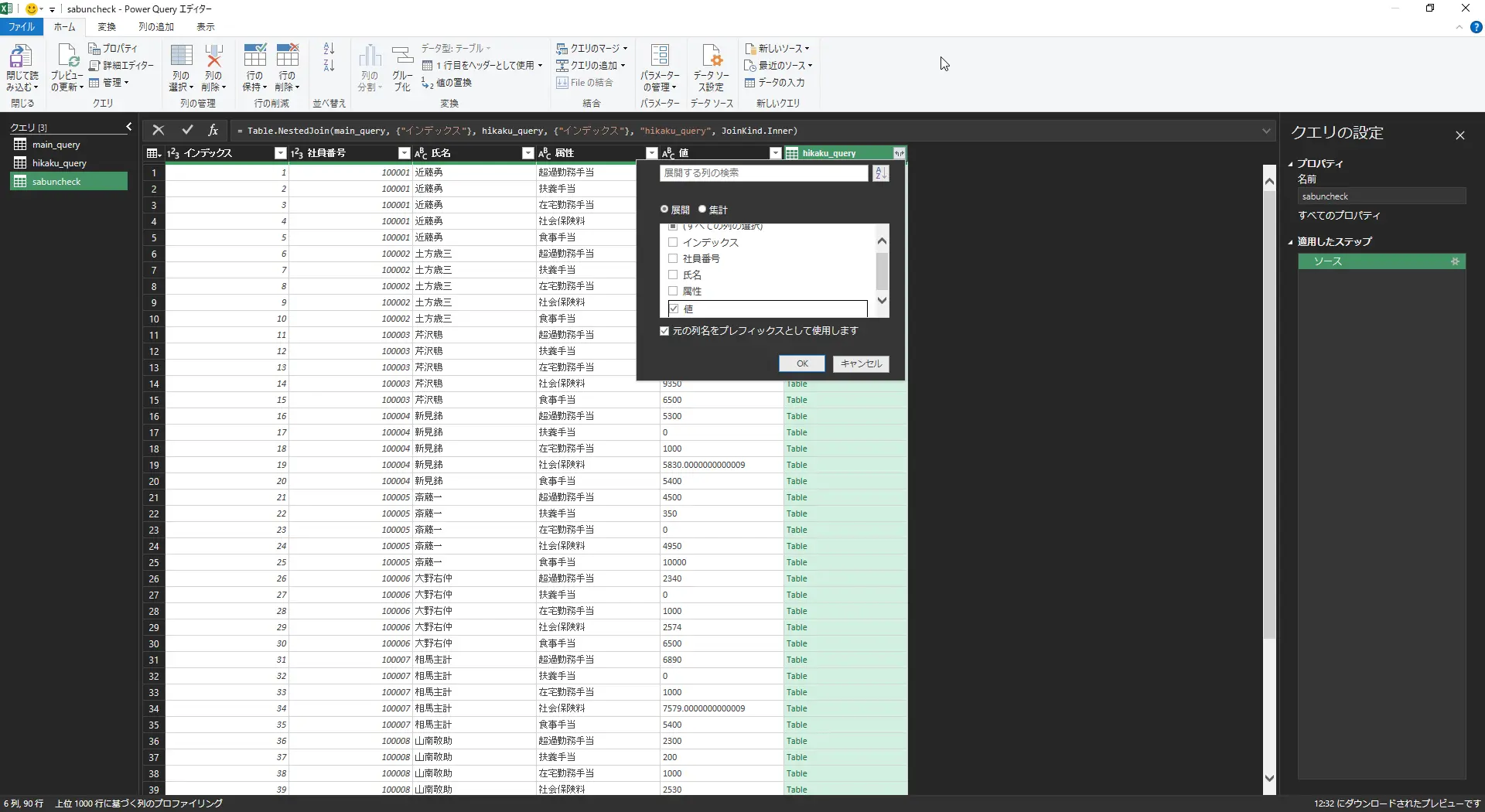
図:結合側の値列のみを表示する
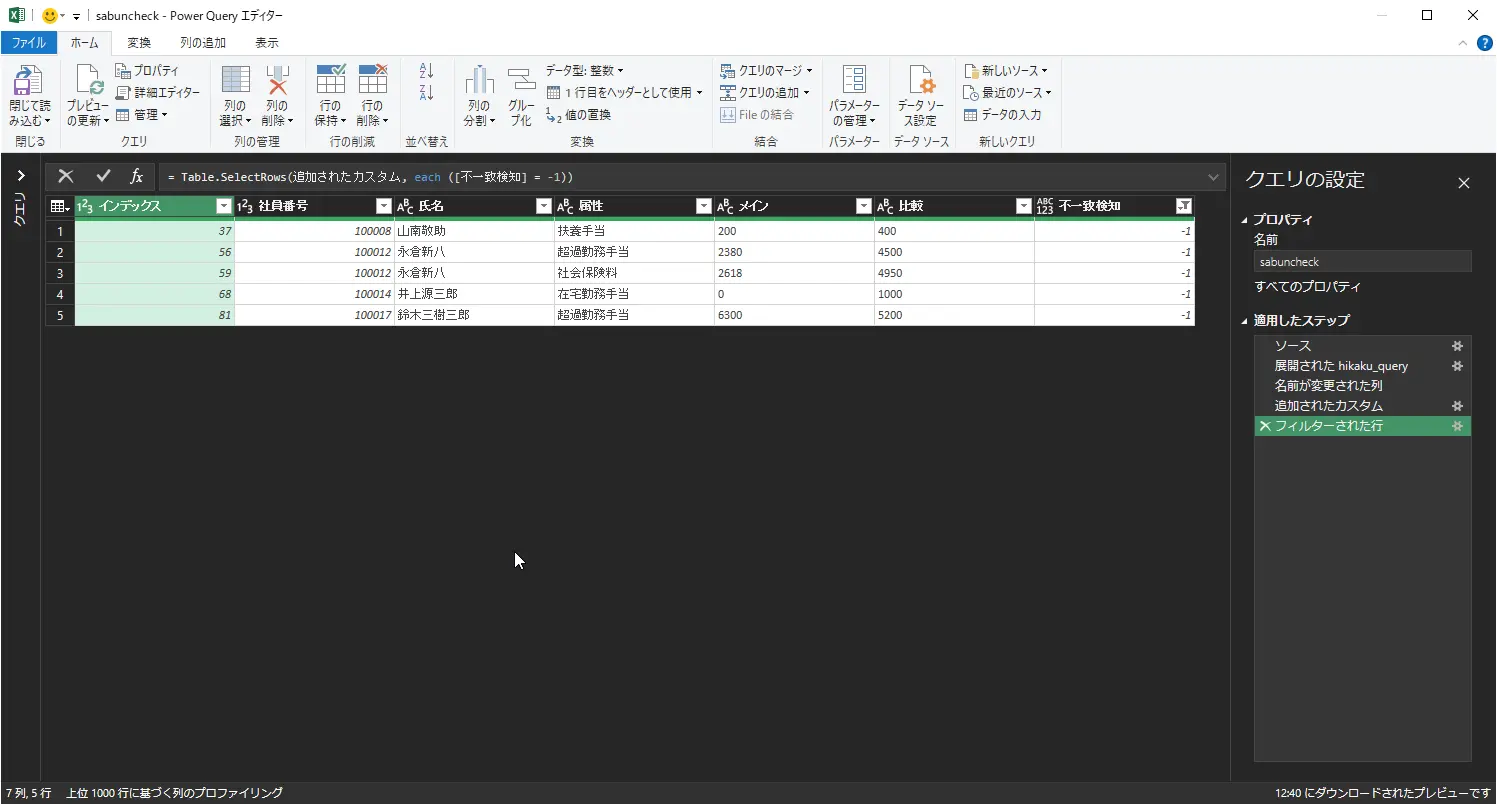
図:カスタム列で判定を加えてフィルタする
不一致検出のクエリを作成する2
前述のクエリは、main_queryとhikaku_queryの2つのテーブルが「同じレコード」「過不足なくレコード数が一致」してる場合に検出が可能ですが、mainにだけ存在するレコードがあったり、逆の場合は検出する行がズレたり、検出結果がおかしな事になります。よって、main側の途中に違うレコードが1個あるだけで、正確な不一致検知ができなくなります。
このケースに対応する場合には、以下のような形で結合してあげると、確実に不一致検知をする事が可能になります。今回はmain_queryとhikaku_queryの両方で一致するレコードだけで結合する内部結合を利用します。
- 左サイドバーのクエリをクリックして開き、そこで右クリック⇒新しいクエリ⇒結合⇒新規としてクエリをマージを選択
- マージのダイアログが出るので、1つ目にmain_queryを選択し、ID列と属性列の2つを選択する(Ctrlキー押しながら2つの列を指定可能)
- 同じく2つ目にhikaku_queryを選択し、ID列と属性列の2つを選択する(Ctrlキー押しながら2つの列を指定可能)
- 両方のテーブルに共通してあるレコードのみにしたいので、内部を選択する
- OKをクリックすると2つのテーブルが2列を持って結合される
後の作り方は前述と同じです。よってインデックス列は利用しません。左外部で結合すると、main_queryにいるレコード全部と、hikaku_queryに合致するレコード全部となるので、hikaku_queryにいないレコードでも結果にはnullとして出てきますが、hikaku_queryにしか存在しないレコードは結果には出てきません。
このパターンのサンプルは差分抽出サンプル2をダウンロードしてテストが可能です。

図:2列で連結すれば確実に結合可能
テーブルのソートの問題点
今回のような相違点を抽出するようなクエリの場合あまり問題にならないのですが、重複するレコードを削除するといったようなケースに於いて、列の並び替えを実行して、削除を実行した結果が思ってたような結果と異なるというケースがあります。
これはPower Queryのバグなのかそれとも、Excelのソートのそれとは異なるからなのか、現時点では仕様上そういうものという事になってるようです。つまり、並び替えを実行したステップはあるものの「ソート順番通りの値として保存されてるわけじゃない」という事です。こちらにもそのエントリーが投稿されています。公式サイトだとその旨が記述されています。
必ずその並び順で後のステップは処理をしてくれないと困るというケースの場合には、手動で以下の作業を行います。
- 対象のクエリを開く
- ホームタブの中にある「詳細エディタ」を開く
- M言語にて、各ステップが記述されている中の、「並び替えられた行」に該当する、Table.sortの行を見つける
- Table.sortの行の式を以下のようにTable.bufferで括ってあげる
//Table.bufferでラッピングする 並び替えられた行 = Table.Buffer(Table.Sort(ステップ名,{{"社員番号",Order.Ascending}})),
ただし、Table.SortやTable.Bufferを多用したり、データ量の多いテーブルで実行すると非常にパフォーマンスがよろしくないので、なるべくソートを必要としないテーブル設計をしておく事が肝要です(本来データベースは行の順番がソートされている必要性が無い筈なので)。どうしても利用するケースでは、それらレコードをグループ化して全体のデータ量を減らしてからソートするといったテクニックが必要です。
関連リンク
- IF式を組み合わせて列作成~上級編10回目
- 表に通し番号の列を自動的に追加する方法(インデックス列)[Power Query(パワークエリ)基礎]
- 【Power Query】グループごとに連番をつける方法
- 【豆知識】ピポット解除時の空欄の扱い
- Power Query エディターで見えている結果(プレビュー)は途中経過ではないということ
- えっ?Power Query で行の並び替え Table.Sort 使うんですか?って話
- Power Query ってちょっと不思議なところがあるけど、知っておいた方がいいことがあるよという話をした。
- PowerQuery【11】重複行の削除(上の行/下の行)
- Bug warning for Table.Sort and removing duplicates in Power Query
- Common Issues : Preserving sort
